这两年 AI 行业里 Agent 智能体概念非常火。
如果只是在 Demo 阶段,看着 Agent 自动写个爬虫、发封邮件,你可能会觉得这技术已经走进了科幻电影。但但凡尝试把它推到生产环境,去解决那些复杂的真实业务,你就会发现:阻碍 Agent 落地的最大瓶颈,根本不是大模型够不够聪明,而是极低的容错率和几乎为零的工程掌控感。
做 AI 应用这两年,我手头 90% 以上的 Agent 项目最后都无疾而终。做到最后,大家心里都只剩一句话:这玩意儿,谁敢往生产环境里用?
各种不可控因素叠加在一起,上线之后你心里完全没底。
概率错误叠加:为什么步骤越多越容易崩?
传统的后端程序是确定性的。
第一步成功了,第二步紧跟着稳稳接上,代码怎么写的它就怎么跑。
但 Agent 在本质上是一个概率状态机,它的每一步决策、工具选择、返回结果解析,全是概率性的。假设你用的 大模型 已经非常优秀了,每一步决策的正确率能达到 95%——那么,当一个任务需要 Agent 连续自主执行 10 个步骤时,整个流程完全走对的概率是多少?
来算一下:0.95^10 ≈ 60%。
如果需要 20 个步骤,成功率就直直跌到 35% 上下了。在实际业务中,任何一个步骤出错,比如工具返回了一个非预期的格式,或者模型产生了那么一丁点理解偏差,整个 Agent 要么开始“一本正经地胡说八道”,要么直接掉进“报错-重试-再报错”的死循环里,直到把你卡里的 Token 额度全部扣光。
这种由概率叠加引发的不可控,才是它进不了核心业务的致命痛点。

评估太难:连基本的回归测试都做不了
做普通后端开发,我们好歹能写单元测试、集成测试,通过 CI/CD 流水线来验证代码逻辑。可到了 Agent 这边,回归测试怎么做?
你今天微调了某个步骤的 Prompt,或者把底层大模型升了个级,你怎么知道这个改动不会让 Agent 在另外 5% 的边缘场景里彻底失控?
你没法像验证传统软件那样去写 Assert 断言,因为它的输出和决策路径是非确定性的。你更不可能在每次提交代码时,都让 Agent 去跑 1000 次真实的浏览器自动化脚本,或者调 1000 次第三方 API——那实在太慢、太贵,而且频繁触发外部接口的限流。
正因为没法建立起标准化、低成本的自动化测试反馈环,研发人员每次修改 Agent 逻辑都像在拆炸弹,上线时胆战心惊,根本不敢大范围推广。
长路径任务下的两个极端行为
现在的推理模型在处理 2 到 3 步的短路径任务时表现惊艳。可一旦任务路径变长——比如去跑一个持续数小时的复杂软件重构——Agent 就会暴露出两种极端问题:
注意力漂移
执行到第 15 步时,它可能已经完全忘了第 1 步时用户让它干什么了。即便上下文窗口足够大,模型也会在冗长的执行历史中彻底迷失,被某些中间步骤产生的噪音一路带偏。
过度执念
它可能在第 8 步撞上了一个极其微不足道的环境配置报错,比如某个不影响全局的本地依赖版本冲突。换成正常人,绕过这个报错或者换个法子实现就完了。但 Agent 会开始疯狂地尝试各种手段去“修复”这个依赖,花掉十几美元的 Token,最后把整个系统配置搞崩——它完全没有那种“绕道走”的人类智慧。
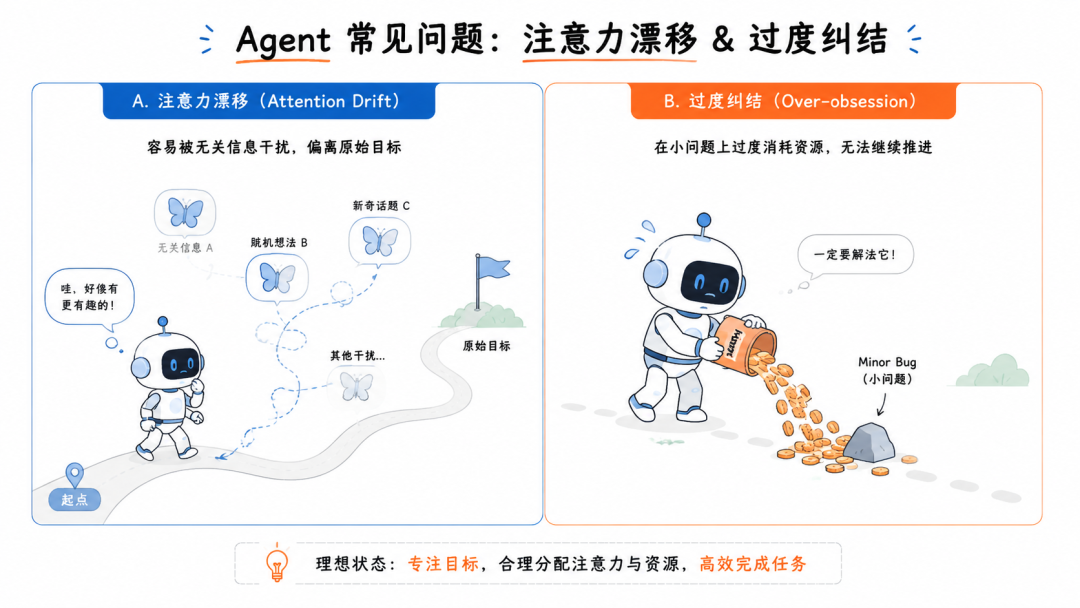
脆弱的现实交互:一出沙盒就翻车
Agent 如果只是在本地沙盒里玩,一切都挺完美。可一旦它上线跟真实互联网环境打交道,情况就变得极不稳定:API 会超时、网页前端会频繁改版导致爬虫失效、目标系统会冷不丁弹出防爬验证码、网络延迟还会时不时抖一抖。
Agent 的观察与执行模块在这种场景下非常脆弱。一次网络超时,或一个格式不规范的 API 返回,就可能让大模型的推理链直接断掉,导致后续流程全部跑不下去。
怎么控制这些不确定性?
大模型是概率的,而商业应用必须绝对严谨。
现在行业里要把 Agent 往生产环境推,基本已经放弃了让模型完全自主规划的方案,转而用更严格的工程手段来做控制:
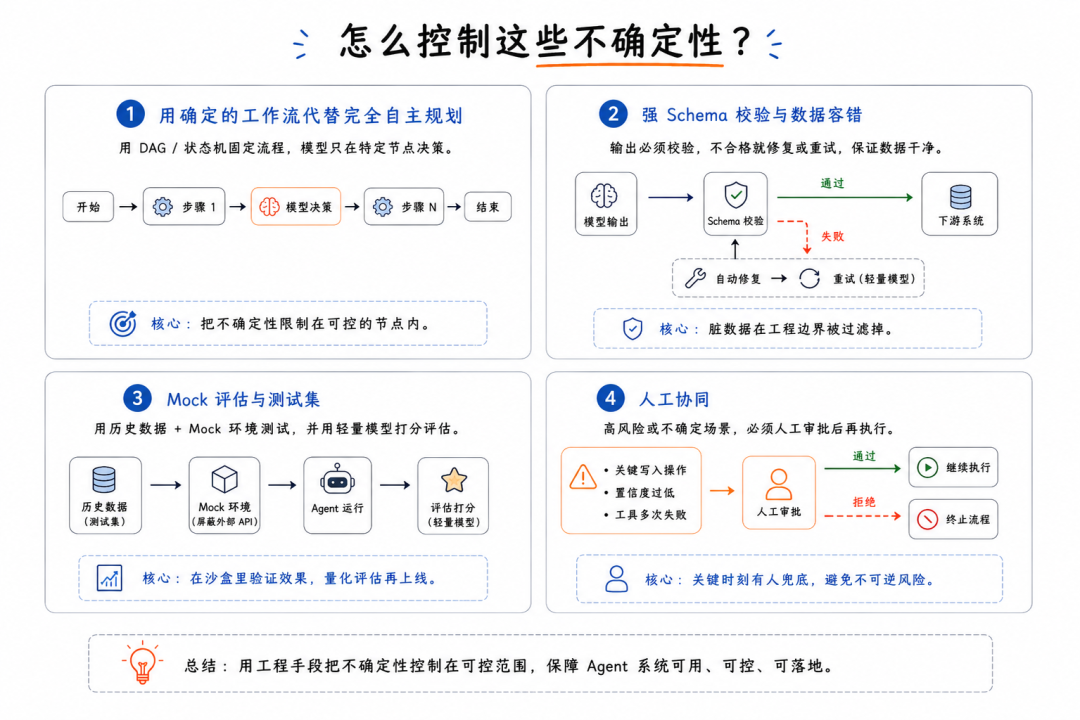
用确定的工作流代替完全自主规划
不要放任 Agent 自己去决定每一步怎么走。当前的实际做法,是在代码里用有向无环图或状态机把业务流程彻底定死,模型只被允许在特定节点上做局部决策或信息提取,把它的行为轨迹牢牢限制在工程框架之内。
强 Schema 校验与数据容错
大模型吐出来的数据,绝不能直接传给下游系统。必须在接收端用 Pydantic 这类工具做格式校验。如果校验失败,通过代码自动进行格式修复;修复再失败,才走轻量级的模型重试流程。一句话:在工程边界上,把所有脏数据都过滤干净。
Mock 评估与测试集
别拿真实接口去跑测试。开发阶段就要积累一批典型的历史业务数据作为测试集。测试时,把外部 API 调用全部 Mock 掉,让 Agent 在沙盒环境里跑。跑完之后,再用一个轻量模型对运行轨迹和结果进行打分评估,检查它是否真的符合预期。
人工协同
遇到关键写入操作(比如扣款、改配置),或者模型判断置信度极低、工具重试多次仍失败时,流程必须强制停下,触发人工审批。确认没问题了再放行,这样才能在关键时刻有一个兜底的人,避免引发不可逆的风险。
写在最后
现在不少人觉得,大模型单体能力的增速已经在放缓,所以 Agent 是唯一的出路。
但作为开发者,我们更该清醒地意识到一点:怎么用确定性的工程手段去驾驭大模型内在的不确定性,其开发难度已经远远超出了调用大模型 API 本身。
这正是限制 Agent 走出 Demo 阶段、真正渗透进千行百业的最大瓶颈。而在云栈社区,很多一线开发者也在持续探讨如何用更扎实的工程化方案,把这些高可用的难题一步一个脚印地啃下来。
《十万个why》系列持续更新~
 发表于 2026-6-8 19:28:29
|
查看: 128|
回复: 0
发表于 2026-6-8 19:28:29
|
查看: 128|
回复: 0
