如何让一张只有4GB显存的“破显卡”也能运行70B参数的大模型?直觉上这似乎不可能——一个70B的模型,仅权重文件就超过百GB,一张普通的消费级显卡怎么可能装得下?这就得聊聊 AirLLM 这个项目了:https://github.com/lyogavin/airllm。

为了让你更直观地理解,我特意准备了一张一图流,把核心逻辑都画了进去。
AirLLM根本没有把整个模型塞进显存
AirLLM 的思路不是把70B模型变小,也不是蒸馏出一个低配版本,而是改变了模型在推理时的“加载方式”。它让显卡在任意时刻只处理模型的一小层,用完即弃,再加载下一层。项目的 README 明确写道,AirLLM 的目标是优化推理时的内存占用,让70B大语言模型能在单张4GB GPU上跑起来。更吸引人的是,它最初的核心卖点是不依赖量化、蒸馏或模型剪枝。当然,项目后来也加入了 4bit/8bit 压缩,用于进一步提升速度。
关键不是“塞得下”,而是“每次只用一点点”
传统的大模型推理,通常会把模型权重尽可能完整地加载到 GPU 显存里。但问题很简单:70B 模型实在太大了。作者在 Hugging Face 文章中给出过一个直观的对比:70B模型以 FP16 精度存储,光是权重本身就占约130GB,这还远没算上 KV Cache、激活值和中间张量。别说一张4GB的显卡,就算普通的消费级旗舰卡也望尘莫及。
但 Transformer 架构有一个极易被忽视的特点——它的计算是严格串行的。
一个典型大模型的前向传播,大致可以理解为以下流程:
输入 token
→ embedding 层
→ 第 1 层 Transformer
→ 第 2 层 Transformer
→ ……
→ 第 80 层 Transformer
→ norm / lm_head
→ 输出下一个 token
推理时,上一层的输出就是下一层的输入。这意味着,在任何一个特定的时钟周期里,真正参与计算的,其实只有当前这一层。
既然如此,为什么非要让所有80层都“长驻”在显存里?AirLLM 的核心逻辑应运而生:要算第几层,就从磁盘或者内存中把那一层搬运到 GPU;算完之后立刻从 GPU 显存中释放掉;然后再去加载下一层。作者把这个方法叫作 Layer-wise Inference,即按层推理。这就是它能跑起来的根本原因。
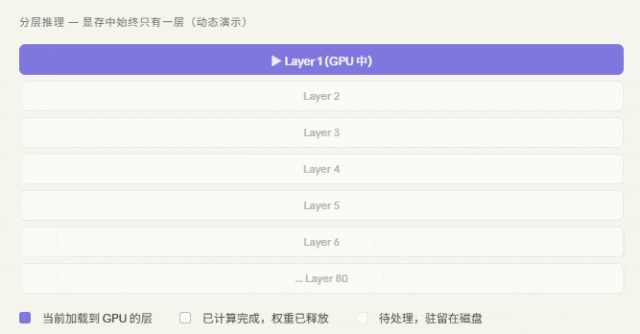
你可以把这个过程想象成做饭:传统方式是直接把80道菜的所有食材全堆在灶台上,家里的灶台自然放不下;而 AirLLM 的做法是,每次只拿一道菜的食材上灶,炒完撤走,再拿下一道。厨房不大,但只要冰箱和储物间够大,理论上就能做出一整桌菜。
它在代码里是怎么做的?
AirLLM 的源码实现非常直白。模型会被拆成按层保存的分片(shard),在前向传播时逐层处理输入,每一层运行结束后立刻释放 GPU 显存。源码注释中也说明,这是一个“sharded version”,目的正是通过将模型拆成 layer shards 来降低显存峰值。
具体来说,流程大致分三步:
第一步,AirLLM 会先把原始的 Hugging Face 模型拆分成按层保存的文件。README 里也特意提到,首次推理时原始模型会被分解并按层存放,所以确保你在 Hugging Face 的缓存目录里有足够的磁盘空间至关重要。
第二步,它借助 Meta Device 初始化一个“空壳模型”。这一步很精妙:模型的计算图结构先建立起来,但权重数据并不真正加载到内存里。AirLLM 的代码中使用了 Hugging Face Accelerate 的 init_empty_weights(),官方文档也强调过,这个上下文管理器能让你初始化模型而不占用 RAM,专门用于处理这类超大模型。
第三步,推理时进入逐层循环。源码的逻辑是,它会根据 layer_names 逐层遍历,先 load_layer_to_cpu,再 move_layer_to_device,把当前层权重搬运到运行设备上;当前层计算完成后,又会把该层移回 "meta",并调用清理函数回收内存。
所以你看,AirLLM 的实现本质并不是“4GB显存放下了70B”,而是“4GB显存只装当前正在运算的那一层”。
为什么恰恰卡在4GB这个坎上?
按照作者的解释,如果一个70B模型有80个 Transformer 层,那么每一层的权重规模大约是总量的 1/80。由此估算,单层参数大概在 1.6GB 左右。再算上中间激活值、KV Cache 等额外开销,完整推理过程的显存监控曲线可以稳稳压在4GB以下。
这里有个容易混淆的概念:KV Cache 并不等于模型权重。
模型权重是模型固有的参数,70B 的体积主要占用在这里。而 KV Cache 是推理时为避免重复计算历史 token 而临时保存的键值对缓存。AirLLM 的作者举例说,当输入长度为 100 时,70B 模型的 KV Cache 大约只有 30MB,比起 GB 级别的模型权重,几乎不算什么。
当然,这绝不意味着“4GB 能通吃一切”。输入序列越长,KV Cache 越大;上下文越长,显存压力也会显著攀升。所以“4GB 能跑 70B”并不等价于“4GB 可以舒舒服服地长上下文、高并发、高速率跑 70B”。
这个项目最初宣称的亮点是“不靠量化、蒸馏、剪枝也能跑”,但后来也加入了 4bit/8bit 的块级压缩(block-wise compression),并在 README 中称最高能带来约3倍的推理提速。文档也解释了它的量化逻辑和常见方案的区别:AirLLM 的瓶颈主要集中在磁盘加载环节,所以它更关注如何缩小权重加载的体积,而不是像常规量化那样同时压缩权重和激活值。
这一点很关键:不压缩,也能靠逐层加载把显存打下来;压缩,只是为了减少磁盘读取量,换一点速度回来。
代价是什么?当然是“慢”
这类方案的代价再明显不过:速度。
普通 GPU 推理之所以快,是因为权重常驻显存,计算时能连续流水线调用。而 AirLLM 每生成一小段内容,都伴随着磁盘/CPU 加载层、搬上 GPU、算完丢掉、再加载下一层的重复循环。它省的是显存,花掉的是时间、磁盘空间、磁盘 I/O 以及 CPU-GPU 间的搬运开销。
所以,AirLLM 更适合下面这些场景:
- 在个人电脑上体验一把 70B 甚至 405B 级别的大模型;
- 研究大模型的结构和推理机制;
- 低预算环境下偶尔跑一次大任务;
- 不追求实时聊天速度,只追求“真能跑起来”。
它不适合:
- 高并发在线服务;
- 低延迟聊天产品;
- 长上下文、高吞吐的推理管道;
- 需要稳定生产部署的业务场景。
换个说法,AirLLM 解决的是“能不能跑”的问题,而不是“跑得爽不爽”的问题。

最后说点有用的
AirLLM 的价值,远不止“4GB 显存跑 70B”这句充满张力的口号。它真正有意思的地方在于,它颠覆了我们对本地大模型部署的一个固有偏见。
过去我们总觉得,大模型必须完整塞进显存里,显存不够就没资格入场。AirLLM 实打实地证明了另一种可能:只要推理流程可以被拆解,硬件瓶颈就可以被重新分配。
显存不够,就少放一点;
磁盘够大,就把权重丢磁盘上;
速度不够,就用预取、压缩、Flash Attention 之类的优化来找补;
模型太大,就让它像流水线一样,分段通过 GPU。
这不是天上掉下来的免费午餐,而是一次精巧的工程权衡:用时间换空间,用磁盘换显存,用更复杂的调度换更低的下场门槛。对于资源受限的研究者和开发者来说,这够不够酷?
 发表于 2026-6-9 20:21:42
|
查看: 162|
回复: 0
发表于 2026-6-9 20:21:42
|
查看: 162|
回复: 0
