导语
2026年5月的一篇arXiv论文,指出各类大模型在各个领域中的推理过程,都可视为低维流形上的受约束动力学过程。这项研究为理解大模型思考过程提供了新视野:推理导致大模型在低维空间的宏观因果效应更强,这也可以视作因果涌现的一种表现形式。
关键词:大模型、推理、动力学、低维流形、因果涌现

论文题目:Reasoning emerges from constrained inference manifolds in large language models
发表时间:2026年5月27日
论文地址:https://arxiv.org/abs/2605.08142
论文期刊:arXiv
大模型的推理是表征空间的动力学降维
大语言模型的推理能力从何而来?这个问题困扰着AI研究者、认知科学家,乃至每一个与大模型对话过的普通人。传统评估只看模型输出对错,根本无法洞察内部的思考过程。研究者始终搞不清:为什么模型能在没有显式推理规则的情况下,表现出逻辑推理能力?
该研究选取推理常用评估数据集MMLU中的文本,该数据集包含多个领域的问题。实验时采取无标签的方式,只考察模型在面对问题最后一个词元时的隐藏状态(图1左边)。结果显示,无论哪种大小、不同类别的模型,都呈现出随网络层数增加,表征维度自发塌缩的现象(图1右边)。这种在推理过程中形成的低维结构被称为推理流形(Reasoning Manifold)。推理流形的维度低,意味着概念簇分离清晰、轨迹平滑、因果强度升高。
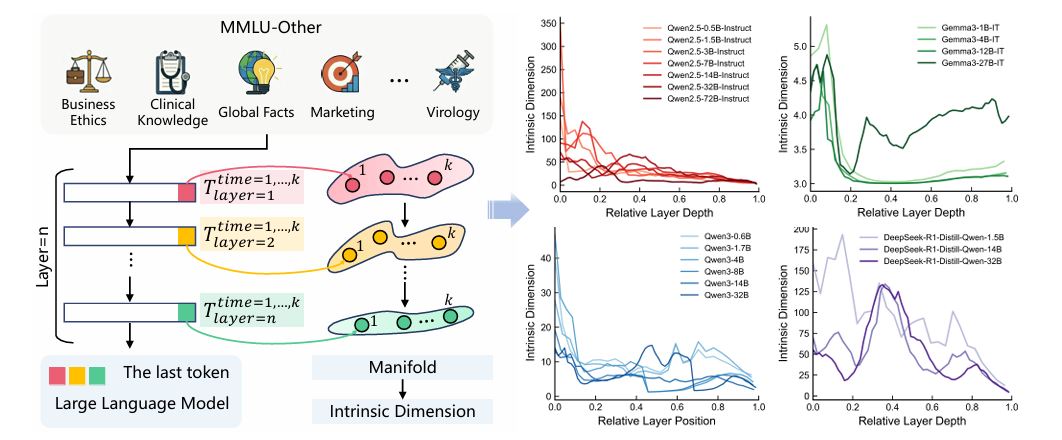
图1:大模型推理时内部表征维度下降
无论是社会科学、STEM还是人文领域,在多种异质刺激下,不同体系的大模型,其推理轨迹内在维度的分布都趋向降低(图2A)。图2B显示,推理过程中的低维推理轨迹与高维静态表征共存,这说明压缩是推理过程的专门化机制,而非模型全局表达能力受限。
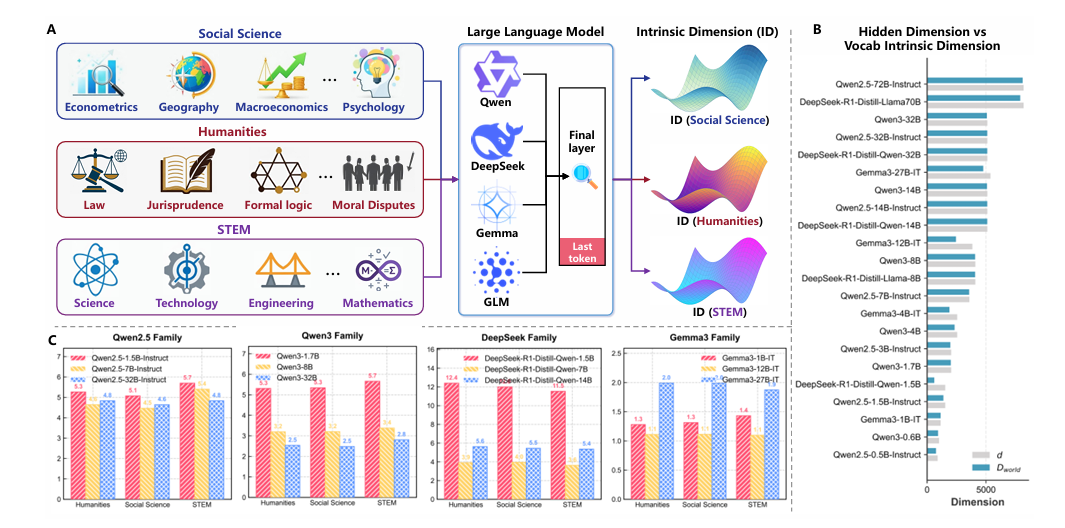
图2:不同模型在不同问题域上呈现出相似的低维度表征
综上所述:大模型的推理,是在高表达力的表征空间内呈现的一种低维动力学过程。推理时的动态行为既非对高维环境的弥散式探索,也非孤立表征之间的静态映射;相反,对提示词的表征会自组织为紧凑的流形,从而约束推理过程中内部状态的演化轨迹。
然而,仅凭维度坍缩这一现象,尚不足以将稳健的推理与出错的推理区分开——这是本文接下来要处理的问题。
良好的推理需要低维表征与高信息容量
推理问题的表征维度,与该问题的推理结果之间存在非单调的变化。如果没有低维表征,推理时对问题的表征就会像无头苍蝇一样在高维空间中四处游荡,称为漫射探索(diffuse exploration)。低维组织确保了推理轨迹被约束在紧凑的内生子空间中,防止无关的维度噪声干扰核心计算。这反映在图3A中:在多数任务里,当表征维度降至某一阈值后,进一步压缩反而可能导致性能持平或下降。
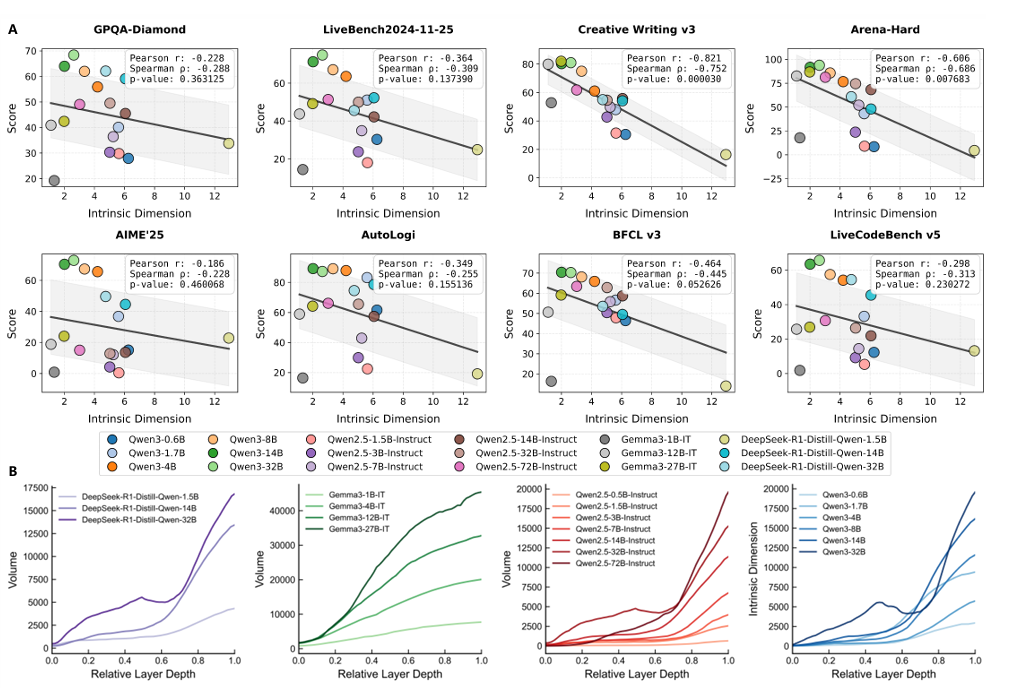
图3:推理时表征的内在维度和信息密度及推理质量的关系
为了解释上述现象,说明还有哪些因素决定推理质量,研究者定义了信息容量(information volume),用于量化大模型在推理过程中内部表示所承载的有效信息含量。其定义基于信息论:首先将每一层最后一个token的隐藏状态投影到一个低维空间,然后利用微分熵(differential entropy)来刻画这些状态点的分布特性,最后将信息体积定义为熵的指数形式。
研究发现,随着推理层数的加深,表征固有维度不断下降,但信息体积(V)却在同步上升(图3B)。有效信息的增加,意味着更深层的模型放大了任务相关的概念变化。早期层的表示维度高但信息稀疏,后期层的表示被高度压缩却信息密集。
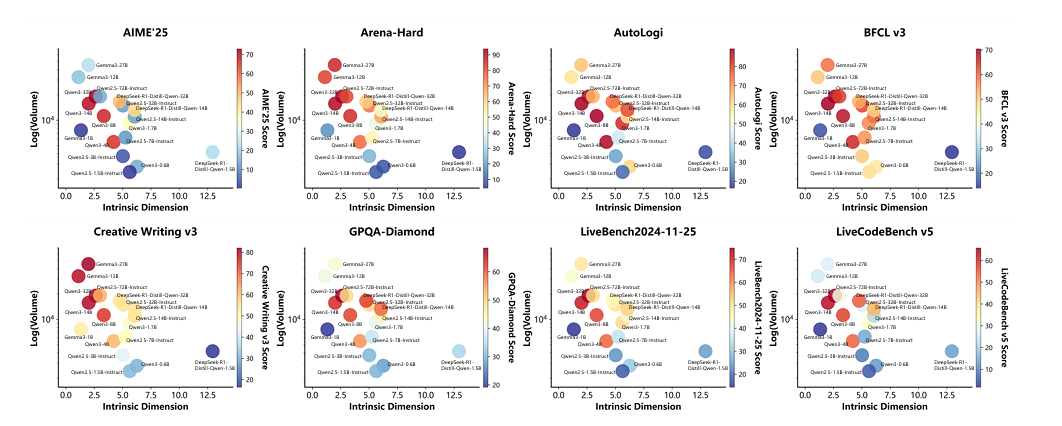
图4:表征维度(横轴)、信息容量(纵轴)与性能(颜色)的三维协同景观
将表征维度和信息容量与推理质量放在一张图中展示(图4),可以看到每个任务类型中,具有高推理质量的案例聚集在一个特定区域——需同时具备较低内在维度(紧凑流形)与较高信息体积(非退化信息流)。位于两个极端的模型,或因过度压缩导致信息不足,或维度弥散导致结构松散,均呈现相对较差的推理性能。
模型的推理质量,能被推理过程的动力学特征准确预测
当大模型需要回答的问题变复杂、包含更多概念时,不同模型的推理质量便出现差异。这暗示存在第三个决定模型推理质量的因素,文中称为模型的表达力容量(Expressive Capacity),即静态词汇嵌入空间所能支撑的概念表征自由度。
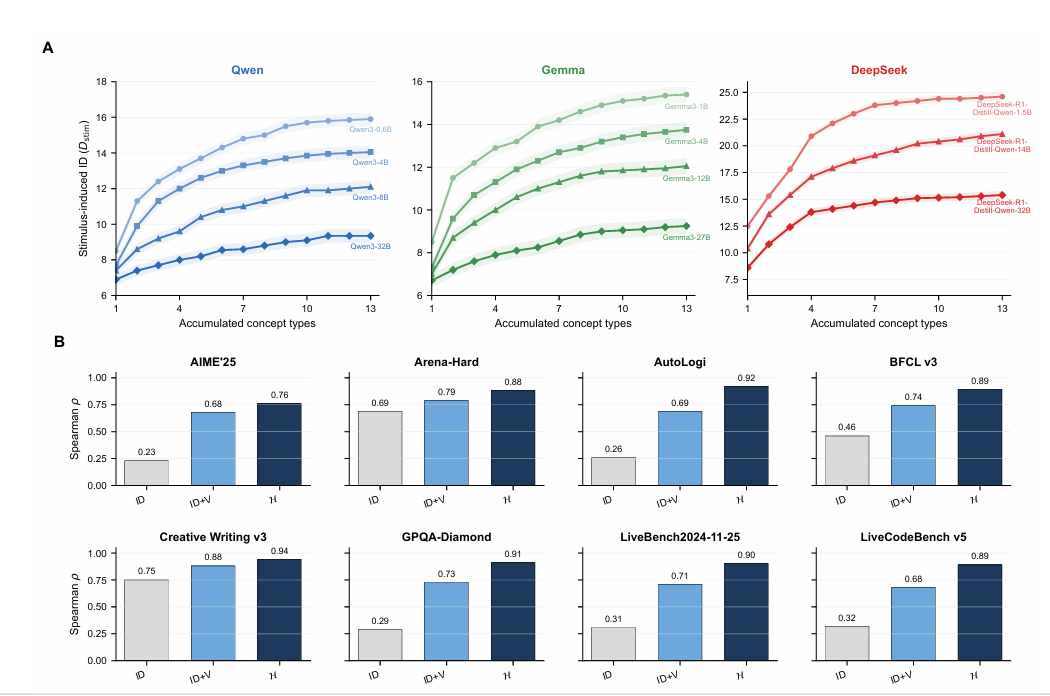
图5:模型表达力容量与概念多样性及推理质量的关系
研究者将MMLU-Other推理任务集划分为13种互斥的问题类型,逐步累积添加问题类型以系统性提升概念多样性。结果发现,高表达力的模型(参数更多),随概念多样性增长更缓慢;低表达力模型则需“招募”更多推理维度来编码异质概念,导致轨迹弥散(图5A)。
模型的表达容量就像是汽车的悬挂系统。当路面变得崎岖(概念多样),好的悬挂系统能够保持车身平稳(推理维度稳定);而差悬挂系统的车辆则会被颠簸挤压得变了形(推理维度急剧扩展)。
综合表征固有维度、信息体积与表达力容量,该文提出了一个统一的健康推理诊断量H——该指标不依赖任何任务标签或基准答案,仅从模型内部的推理动力学过程就能计算得出。
论文测试了包括AIME‘25数学推理、GPQA-Diamond科学推理、LiveCodeBench代码生成等一系列基准任务,发现H与基准表现之间的Spearman秩相关系数在所有测试基准上都超过了0.9(图5B)。这意味着,单凭模型对提示词内部表征的动力学演化,就足以准确预测它在各种任务上的表现。
这种跨领域的普适性,意味着低维流形捕获的因果结构是任务通用的——这正是因果涌现后,宏观变量超越微观细节的典型体现。宏观特征(例如H)无需外部标签,仅通过前向传播即可自发涌现,且比微观具有更高的有效信息。
使用文中描述的推理健康度评估指标H,能显著提升模型可解释性。不仅能在大模型推理时实时评估偏离推理质量,还能精确定位模型在对问题进行表征的过程中,哪一层、哪一个token开始偏离“甜点区”,从而为模型及提示词改进提供指示,或在推理过程的早期向隐藏状态注入引导信号,使其轨迹靠拢健康流形,从而提高输出的正确率和稳定性。通过比较不同模型在单个推理任务上的H值,还能解释为何它们在同一套基准任务上分数相似,但内在机制却可能天差地别。
对于需要高可靠性的场景,H值可作为一项关键的监控指标。部署微调后的大模型之前,开发者可以计算候选模型与对应基模的H值,用来评估微调效果。推理过程中,实时监控对提示词表征的维度及信息容量,一旦偏离程度超过阈值,系统可以立即预警或拒绝回答,从而实现推理层面的实时幻觉拦截。
此外,通过引导模型改变在推理过程中对提示词的表征流形,我们可以让大模型生成更多样化、更具创造性的方案,从而避免模型倾向于趋同、陷入单一的“人工智能蜂巢思维”(Artificial Hivemind),为大模型设计多样化的思考方式提供干预方案。

 发表于 2026-6-7 19:04:43
|
查看: 100|
回复: 0
发表于 2026-6-7 19:04:43
|
查看: 100|
回复: 0
