在 DeepSeek-R1 和 OpenAI o1 等大语言模型通过强化学习(RL)展现出惊人的数学与逻辑推理能力后,业界围绕其能力来源展开了激烈辩论:RL 真的赋予了模型预训练阶段未曾掌握的推理能力,还是仅仅优化了模型从已有知识中提取信息的过程?
现有研究结论不一。一些观点认为 RL 仅是“能力精炼器”,无法突破预训练阶段设定的能力天花板;而另一些实验则证明 RL 能解决预训练中从未出现的复杂问题。这种分歧的根本原因在于,现代大规模预训练数据(数万亿 token)如同一个“黑盒”,我们无法确切知晓模型在其中究竟学到了什么,因此难以界定 RL 后的表现属于“知识回忆”还是“能力创新”。

来自卡内基梅隆大学(CMU)的研究团队通过一篇论文为这场争论提供了清晰答案。他们摒弃了不可控的互联网数据,构建了一个完全可控的合成数据“实验室”,不仅厘清了预训练、中期训练与 RL 之间的复杂关系,更总结出一套关于“如何高效培养模型推理能力”的精确方法。
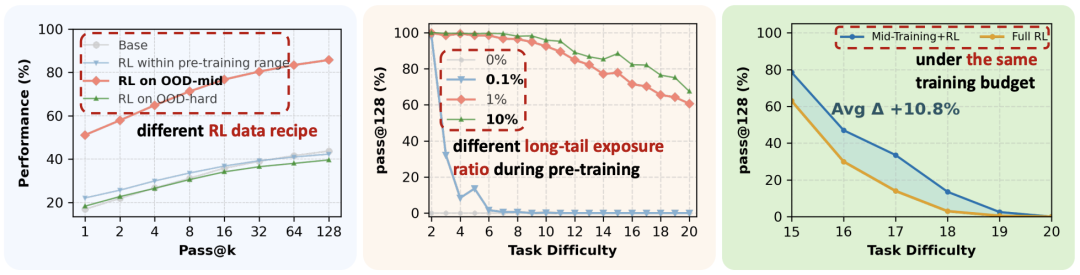 图解:论文三大核心发现。左:RL 仅在任务难度略高于预训练范围时有效;中:情境泛化依赖于预训练阶段的微量接触;右:中期训练能显著提升计算效率。
图解:论文三大核心发现。左:RL 仅在任务难度略高于预训练范围时有效;中:情境泛化依赖于预训练阶段的微量接触;右:中期训练能显著提升计算效率。
1. 实验方法:打造一个“纯净的实验室”
为探究因果关系,研究团队建立了一个受控环境,以排除真实数据的干扰。
1.1 数据生成框架:骨架与皮肤
研究者基于GSM-Infinite框架生成数据。该框架巧妙地将数学问题解构为两部分:
- 依赖图(Dependency Graph):问题的“骨架”或逻辑结构。例如,A + B = C,C * D = E。通过控制图的节点数量(运算步数,记为
op),可以精确控制问题难度。
- 情境模板(Contextual Template):问题的“皮肤”或故事背景。相同的逻辑骨架,可被渲染为“动物园里的狮子和老虎”(情境 A),或“学校里的老师和学生”(情境 B)。
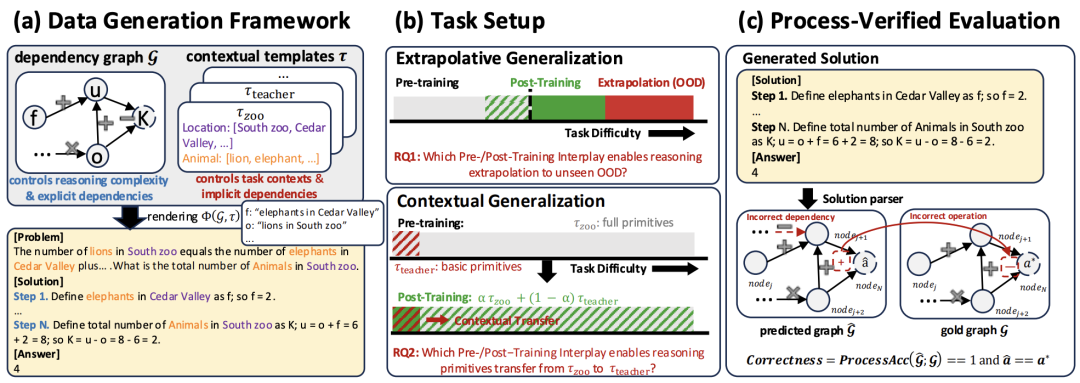 左侧为控制逻辑复杂度的依赖图,中间是不同情境模板,右侧是生成的具体问题与推理步骤。此设计实现了“难度”与“内容”的完全解耦。
左侧为控制逻辑复杂度的依赖图,中间是不同情境模板,右侧是生成的具体问题与推理步骤。此设计实现了“难度”与“内容”的完全解耦。
1.2 两个维度的泛化
论文定义了两种关键的推理能力评估指标:
- 外推性泛化(Extrapolative Generalization):在深度上的扩展。即模型能否通过 RL,解决比预训练所见更复杂(运算步数更多)的问题。
- 情境性泛化(Contextual Generalization):在广度上的迁移。即模型能否通过 RL,将一种故事背景(如“动物园”)下学到的逻辑,应用到另一种背景(如“学校”)中。
1.3 严苛的评分标准:过程验证
为防止模型通过“蒙答案”得分(这在 RL 中常见),研究者采用了过程级验证(Process-Verified Evaluation)。只有当模型生成的每一步推理(中间变量、运算逻辑)均与真实依赖图完全一致,且最终答案正确时,才计为成功。
2. 核心发现一:RL 何时能真正提升推理能力?(外推性泛化)
实验揭示了强化学习有效性背后的规律:RL 的收益高度依赖于任务难度与模型当前能力的相对位置。
2.1 三个难度区间的表现
研究者将基础模型(Base Model)的能力范围设定在 op=2-10(即 2 到 10 步运算)。随后观察 RL 在不同难度数据上的表现:
- 分布内(ID, op=2-10):RL 对高采样下的准确率(pass@128)几乎无提升。模型已掌握此类任务,RL 的作用更多是提升一次通过率(pass@1),属于“锦上添花”。
- 能力边界(OOD-edge, op=11-14):这是 RL 的“黄金区间”。任务略高于预训练难度,模型虽不能稳定做对(pass@1 低),但偶尔能成功(pass@128 不为零)。在此类数据上进行 RL,模型可通过探索学会组合已有原子操作,实现能力突破。
- 极难任务(OOD-hard, op=15-20):若直接用此类数据训练,模型会因难度过高而无法学习。但先在“能力边界”数据上训练后的模型,却能有效泛化至这些极难任务。
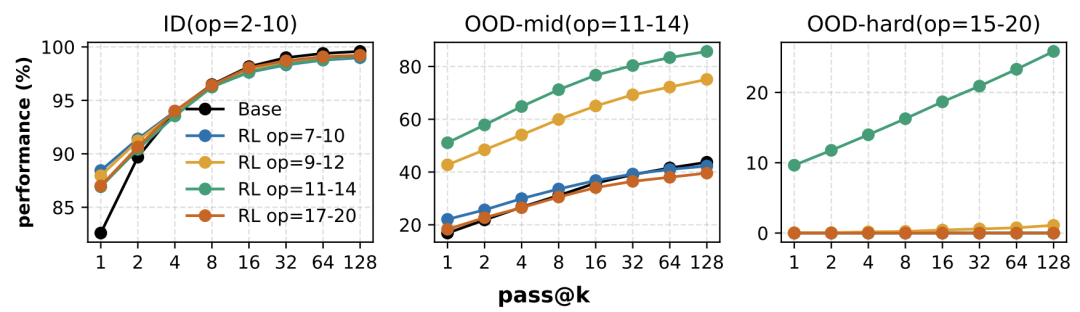 左图(简单任务)RL 曲线重合;中图(边界任务)RL 带来巨大性能增益;右图显示,只有经过边界任务训练的 RL 模型(绿线)才能解决极难问题。
左图(简单任务)RL 曲线重合;中图(边界任务)RL 带来巨大性能增益;右图显示,只有经过边界任务训练的 RL 模型(绿线)才能解决极难问题。
2.2 结论
RL 产生实质性推理收益需满足两个条件:
- 预训练未使模型能力饱和(留有提升空间)。
- RL 训练数据必须位于模型的“能力边界”(Edge of Competence)——既非已掌握的,也非完全无法理解的。
3. 核心发现二:从“动物园”到“学校”的跨越(情境性泛化)
如果模型只在预训练中见过“动物园”背景的问题,它能通过 RL 学会解决逻辑相同但背景为“学校”的问题吗?
3.1 “种子”理论
实验设计巧妙:在预训练数据中混入 99.9% 的“情境 A”(如动物园),通过控制“情境 B”(如学校)的混入比例(0%, 0.1%, 1%, 10%),观察 RL 后的效果。
- 0% 接触:如果预训练完全未见情境 B,无论 RL 如何训练,模型都无法掌握。RL 无法“无中生有”。
- 0.1% 接触:效果依然很差,模型无法泛化。
- 1% 接触:关键转折点!只要预训练中有 1% 的数据涉及情境 B(即便是简单原子操作),RL 就能像催化剂一样,让这点微小的“种子”迅速发展,最终使模型能完美解决情境 B 中的复杂问题。
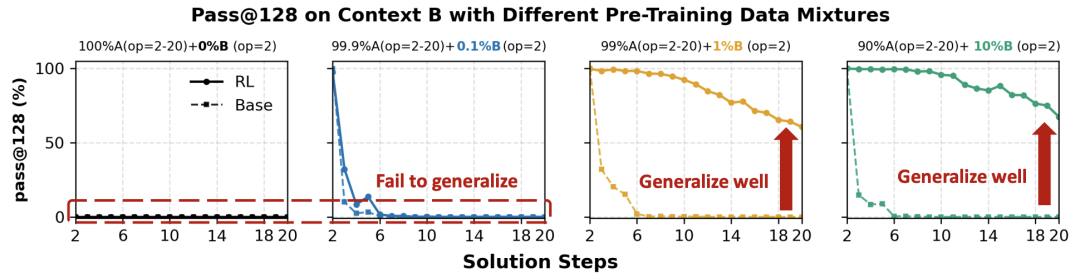 对比可见:左侧(0%和0.1%暴露)RL 后性能无起色;右侧(1%和10%暴露)RL 迅速将性能提升至 100%,证明了“种子”的必要性。
对比可见:左侧(0%和0.1%暴露)RL 后性能无起色;右侧(1%和10%暴露)RL 迅速将性能提升至 100%,证明了“种子”的必要性。
3.2 结论
RL 是放大器,而非创造者。 它需要预训练阶段提供最基础的“原语”或“概念种子”。只要种子存在,RL 便能将其有效组合与强化,实现强大的跨情境泛化。
4. 核心发现三:被忽视的关键——中期训练(Mid-Training)
中期训练指在预训练与 RL 之间,使用高质量、特定领域数据进行的监督微调。论文证明这一阶段至关重要。
4.1 计算预算的博弈
研究设定了固定计算预算,探讨如何在中训与 RL 间分配。引入等效公式统一衡量成本:C = N * K * L,其中 N 是样本数,K 是采样次数,L 是序列长度。这表明 RL 的采样探索成本高昂。
4.2 实验结果:混合策略最优
- Light-RL(重中期训练,轻 RL):在固定预算下,此策略在能力边界任务(OOD-edge) 上的 pass@1 最高。中期训练能有效固化基础能力,提升输出稳定性。
- Heavy-RL(轻中期训练,重 RL):此策略在极难任务(OOD-hard) 上表现最佳。大量的 RL 探索对于攻克模型未曾接触的深层逻辑至关重要。
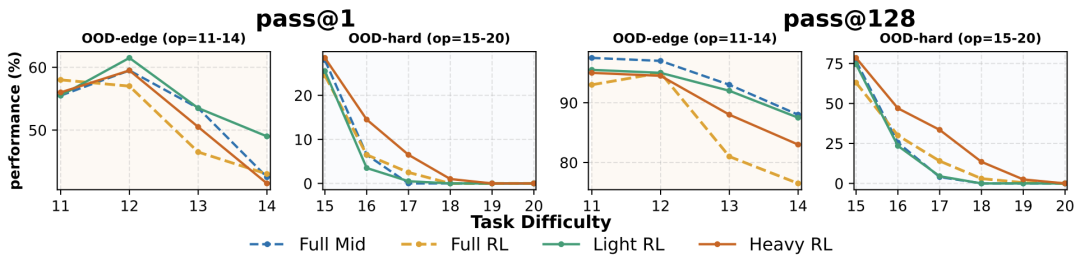 不同策略对比:深蓝线(Light RL)在边界任务表现好;棕线(Heavy RL)在极难任务表现优。
不同策略对比:深蓝线(Light RL)在边界任务表现好;棕线(Heavy RL)在极难任务表现优。
4.3 结论
中期训练是预训练与 RL 间的关键桥梁,负责将模型调整至“RL 就绪”状态。最佳实践是:预留部分预算用于中期训练以建立稳健先验,再使用 RL 进行大规模探索以突破极限。
5. 核心发现四:拒绝“奖励黑客”——过程监督的作用
RL 中经典的“奖励黑客”问题是指模型可能通过错误推理凑出正确答案。
5.1 奖励函数的设计
为解决此问题,论文引入了过程监督。奖励函数设计为:
R_result:结果奖励(答案正确给1,错误给0),稀疏。R_process:过程验证奖励(每一步推理正确性),密集。
更严格的版本是:仅当推理过程完全正确时,才给予结果奖励。
5.2 效果验证
实验表明,引入过程奖励能显著减少逻辑错误(如幻觉出不存在节点),并将外推性极难任务(OOD-hard)的 pass@1 准确率提升了 4-5%。
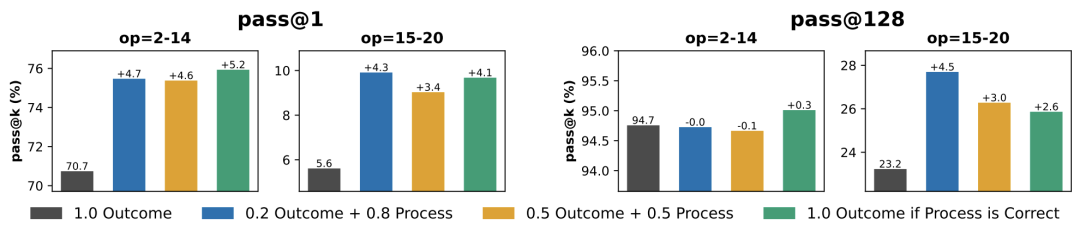 柱状图显示,相比纯结果奖励(灰柱),融合过程奖励的策略(蓝、黄、绿柱)在所有难度任务上准确率更高,证明过程监督能有效抑制奖励黑客行为。
柱状图显示,相比纯结果奖励(灰柱),融合过程奖励的策略(蓝、黄、绿柱)在所有难度任务上准确率更高,证明过程监督能有效抑制奖励黑客行为。
结论与展望
这项研究通过严格控制变量的实验,澄清了关于 RL 作用的诸多猜测,并为 AI 训练提供了实用指南:
- RL 的本质:它不是万能魔法,而是一个强大的组合器与放大器,无法创造预训练中不存在的基础概念。
- 预训练的关键:必须广泛覆盖基础“原语”,并为长尾知识埋下“种子”(至少 1% 的覆盖率),这是后续 RL 实现迁移的前提。
- 训练策略:
- 难度设计:RL 数据应精准针对模型的“能力边界”。
- 阶段配合:不可跳过中期训练。应先用中期训练夯实基础,再用 RL 探索攻坚。
- 奖励设计:尽可能采用过程奖励,以引导模型学习正确的推理逻辑,而非仅仅追求答案。
这项研究揭示,打造强大的推理模型不仅依赖于大规模算力(用于 RL 探索),更离不开精细的数据工程(预训练种子铺设)与科学的课程设计(难度阶梯构建)。
 发表于 2025-12-13 06:19:33
|
查看: 246|
回复: 0
发表于 2025-12-13 06:19:33
|
查看: 246|
回复: 0
