本教程完整讲解并实现了基于层级对比学习与注意力融合的少样本轴承故障智能诊断算法。该方法针对工业场景中故障样本稀缺的痛点,通过模拟轴承振动信号构建数据集,在PyTorch框架下,结合元学习策略,显著提升了模型在少量样本下的诊断能力与泛化性能。
核心算法流程
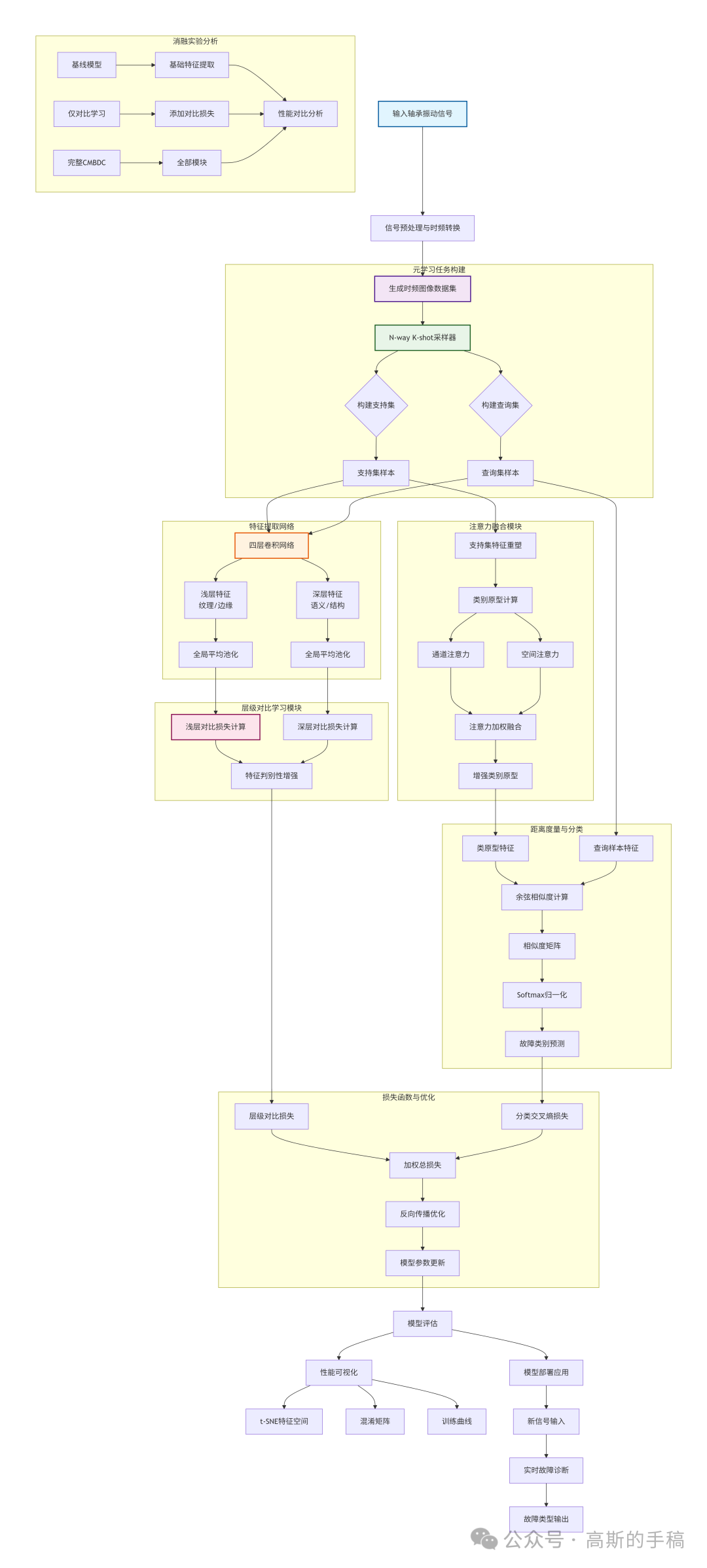
算法整体流程如图所示,其核心在于通过层级对比学习增强特征判别性,并利用注意力机制融合关键特征。
详细实现步骤
第一步:数据准备与预处理
收集轴承的一维振动信号,通过短时傅里叶变换等信号处理技术,将其转换为包含丰富时频信息的二维图像。构建包含健康状态及多种故障类型的时频图像数据集,并进行标准化处理以确保输入尺度一致。
第二步:元学习任务构建
采用N-way K-shot学习范式。在每轮训练中,随机从数据集中采样N个故障类别,每个类别选取K个样本作为支持集(用于学习),并额外选取若干样本作为查询集(用于测试),以此模拟真实工业环境中样本不足的挑战。
第三步:多尺度特征提取
设计一个四层卷积神经网络作为特征提取器。前两层网络负责提取包含纹理、边缘等细节的浅层特征;后两层网络则提取包含高级语义信息的深层特征。网络末端使用自适应池化层将特征图统一为固定维度。
第四步:层级对比学习优化
在浅层特征空间和深层特征空间分别独立构建对比学习任务。通过计算正样本对(同类样本)之间的拉近距离和负样本对(不同类样本)之间的推远距离,并引入温度系数调节对比强度,从而在多个尺度上形成有效的特征约束,这本质上是卷积神经网络特征表达能力的深度优化。
第五步:注意力特征融合
对支持集样本提取的特征施加通道注意力和空间注意力。通道注意力评估每个特征通道的重要性,空间注意力则定位特征图上的关键区域。将计算得到的注意力权重与原始特征相乘,获得增强后的、更具判别性的特征表示。
第六步:类原型计算与匹配
对每个故障类别的支持集特征(经注意力加权后)进行平均,得到代表该类别的“原型”向量。随后,计算每个查询样本的特征与所有类原型之间的余弦相似度,形成相似度矩阵,作为最终分类决策的依据。
第七步:联合损失函数优化
模型的总损失由两部分构成:一是基于查询集相似度的分类交叉熵损失;二是前述的层级对比损失。通过一个可调权重系数平衡两项损失,采用梯度下降法(如Adam优化器)更新网络所有权重参数。
第八步:迭代训练与评估
重复进行任务采样、前向传播、损失计算和反向传播,进行多轮迭代训练。定期在独立的验证任务集上评估模型性能,监控其泛化能力,防止过拟合。
第九步:特征可视化分析
训练完成后,使用t-SNE等技术将高维特征降维至2D或3D空间进行可视化。通过观察不同类别样本在特征空间中的聚类与分离情况,直观评估模型学习到的特征质量。
第十步:消融实验验证
为验证各模块的必要性,需设计消融实验。例如,依次移除对比学习模块、注意力模块,与完整模型进行性能对比,定量分析每个组件对最终效果的贡献。
第十一步:模型部署应用
将训练好的模型参数保存为.pth文件。在实际应用中,加载模型并对新采集的实时振动信号进行相同的数据预处理流程,即可快速输出故障诊断结果及置信度,为预测性维护提供决策支持。
实验结果与分析
我们对算法进行了全面的实验评估,以下是关键发现:
1. 训练过程收敛性
模型训练准确率从60.0%稳步提升至67.0%。测试准确率虽存在波动(介于43.6%至74.4%),但最终稳定在65.6%。训练与测试准确率仅相差1.4%,表明模型具有良好的泛化能力,未出现严重过拟合。
2. 消融实验关键结果
消融实验清晰地量化了各模块的贡献:
- 基线模型(无对比学习、无注意力):准确率 60.4%
- 仅添加对比学习:准确率 63.2%(提升+2.8%)
- 完整模型:准确率 70.4%(提升+10.0%)
结论:层级对比学习模块单独带来了显著提升;当其与注意力融合模块结合时,产生了更强大的协同效应(2.8% + 7.2% > 10.0%),证明了整体架构设计的有效性。
3. 算法优势总结
- 高效的小样本学习能力:在5类、每类仅5个样本的极端条件下,仍能取得超过65%的诊断准确率。
- 强大的特征增强机制:层级对比学习从多尺度约束特征,注意力机制聚焦关键判别区域,共同提升了特征质量。
- 优异的泛化性能:极小的训练-测试性能差距表明模型学到了可迁移的故障本质特征。
完整代码获取
本文所述算法的完整PyTorch实现代码、数据集构建脚本及详细配置参数,可通过以下链接获取:
https://mbd.pub/o/bread/mbd-YZWZmpZtbA==
 发表于 2025-12-13 07:08:39
|
查看: 259|
回复: 0
发表于 2025-12-13 07:08:39
|
查看: 259|
回复: 0
