通用强化学习(RL)与基于大语言模型的强化学习之间存在一个核心但常被忽视的区别:状态转移过程的确定性。这一底层差异深刻影响着算法设计与优化的侧重点。
在许多传统 RL 应用场景,如电子游戏、机器人控制中,环境的状态转移通常具有显著的随机性。以《星际争霸》为例,执行相同的指令后,由于对手单位的AI行为、环境噪音或物理引擎的随机性,下一帧的游戏画面可能截然不同。机器人执行相同动作时,也会因摩擦力、惯性和外部扰动等因素得到不同的结果。
因此,在通用 RL 框架中,环境动力学通常被建模为一个概率分布:P(next_state | state, action)。算法在优化策略时,必须有效处理这种随机性带来的高方差问题,这使得价值函数估计、重要性采样以及各类方差削减技术变得至关重要。
然而,在大型语言模型的强化学习任务中,情况则完全不同。
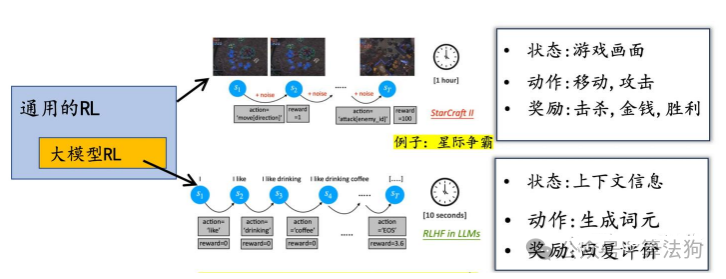
对于语言模型(LLM),其“状态”是已生成的文本序列(tokens),“动作”是当前待生成的下一个token,而“下一状态”仅仅是简单地将这个新token拼接到已有序列的末尾。这一过程没有环境噪声,也不受任何外界随机因素干扰。相同的状态(上文)和动作(选择的token)必然导向唯一确定的下一个状态(新的上文)。这是一种严格确定性的状态转移。
这种确定性本质带来了几个至关重要的影响:
-
方差显著降低:由于状态转移过程是确定的,智能体决策所面临的动态环境不确定性大大减少。因此,像 REINFORCE 这类在传统 RL 环境中因高方差而难以训练的直接策略梯度方法,在语言任务中变得相对可行和稳定。
-
无需复杂环境建模:语言生成的“环境”可以被视为一个无噪声的、确定性的、可完全模拟的自回归过程。这使主流方法如 RLHF(基于人类反馈的强化学习)、PPO(近端策略优化)、GRPO等,能够将全部注意力集中在策略(即模型本身)的优化上,而非耗费精力去学习和估计一个复杂的环境模型。
-
价值函数角色的转变:在 LLM 的强化学习(RL)任务中,价值函数的主要作用不再是应对随机转移带来的不确定性。它更多地扮演着一种奖励平滑机制的角色,用于降低长序列任务中稀疏的序列级奖励所带来的方差,从而提升整个训练过程的稳定性。
总结来说,当我们谈及“通用RL环境通常是不确定的”时,并非指RL算法本身随机,而是强调其应用场景的环境动力学天然包含大量随机性。相比之下,LLM的强化学习过程则建立在高度确定性的状态转移之上。正因如此,针对大模型的强化学习算法选择与优化重点,与传统RL领域大相径庭:它无需学习环境模型,也无需重点处理复杂的随机转移,更不必在价值函数估计上投入过多精力;其核心挑战与优化方向,更多地转向了对长程依赖的建模、对稀疏的序列级奖励进行有效分配,以及对超大模型生成行为的精细化引导与控制。 |  发表于 2025-12-13 07:55:16
|
查看: 224|
回复: 0
发表于 2025-12-13 07:55:16
|
查看: 224|
回复: 0
