一、Pod日志收集方案
在Kubernetes环境中,有效的日志管理是云原生应用可观测性的基石。通常,我们会采用开源的EFK技术栈来构建日志系统。
1. 开源方案EFK
EFK是Elasticsearch、Fluentd/Fluent Bit/Filebeat、Kibana的简称,是一套流行的日志收集、存储和可视化解决方案。
- Elasticsearch:一个基于Apache Lucene构建的开源分布式搜索和分析引擎,作为日志的存储和索引后端。
- Kibana:一个与Elasticsearch深度集成的开源数据可视化平台,用于日志的搜索、分析和仪表盘展示。
- Filebeat:一个轻量级的日志数据收集器,负责从指定源头采集日志,并将其发送到Elasticsearch或Logstash等目标。
选择建议:
- 需要海量数据搜索、实时日志分析 → 选择Elasticsearch。
- 需要强事务、复杂关联查询 → 选择MySQL。
2. Kubernetes中的日志特性
在Kubernetes集群中,对于应用日志的输出,有一个最佳实践:
- 建议应用将日志输出到标准输出(stdout)和标准错误输出(stderr),而不是直接写入容器内的日志文件。
- 容器运行时(如Docker/Containerd)会自动捕获这些标准输出流,并将其写入宿主机上的JSON文件中。用户可以通过
kubectl logs 或 docker logs 命令查看这些日志。
在Kubernetes节点上,日志的实际存放路径为:
- 容器日志:
/var/log/containers/*.log
- Pod日志:
/var/log/pods/
注意:日志以文件形式存储,存在写满磁盘的风险,通常需要配合logrotate等工具进行日志轮转(压缩、归档、删除)。
3. 集群级别日志采集架构
Kubernetes提供了几种主流的日志采集架构,适用于不同场景。
节点级日志代理 (Node-level Logging Agent)
这种架构在每个节点上部署一个日志采集代理(DaemonSet),收集该节点上所有容器的日志。
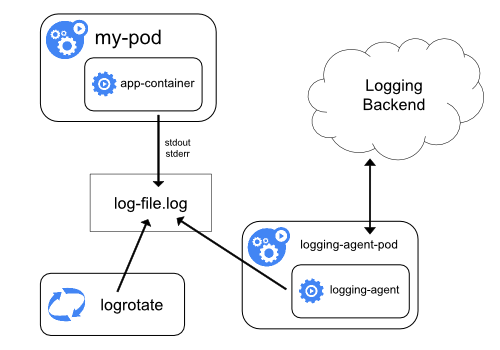
- 应用写日志:应用容器将日志输出到标准输出或容器内的日志文件。
- 日志轮转:宿主机上的
logrotate 等工具定期处理日志文件。
- 采集与转发:节点上的
logging-agent (如 Filebeat, Fluentd) 读取日志文件,并发送到后端的日志存储(如 Elasticsearch)。
Sidecar容器运行日志代理
为需要特殊日志处理的应用Pod添加一个专用的Sidecar容器来负责日志采集。
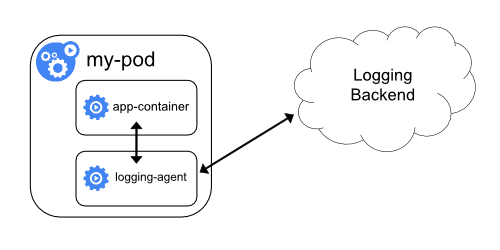
- 应用输出日志:应用容器将日志输出到标准输出或文件。
- Sidecar采集:Sidecar容器中的
logging-agent 读取应用容器的日志。
- 转发至后端:Sidecar将处理后的日志发送到日志存储后端。
应用直接输出
最简单的模式,依赖Kubernetes和容器运行时的基础设施。
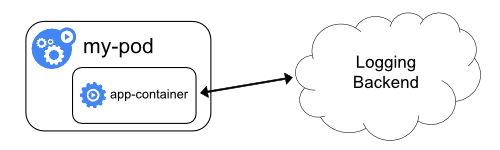
- 应用输出:应用容器直接将日志输出到标准输出(stdout/stderr)。
- 运行时采集:Kubernetes/容器运行时自动捕获这些日志流。通常需要配合节点级代理将宿主机上的日志文件发送到日志后端。
二、传统服务器架构下的EFK部署
为了深入理解EFK,我们先在传统虚拟机或物理机上进行部署。
1. Elasticsearch核心概念
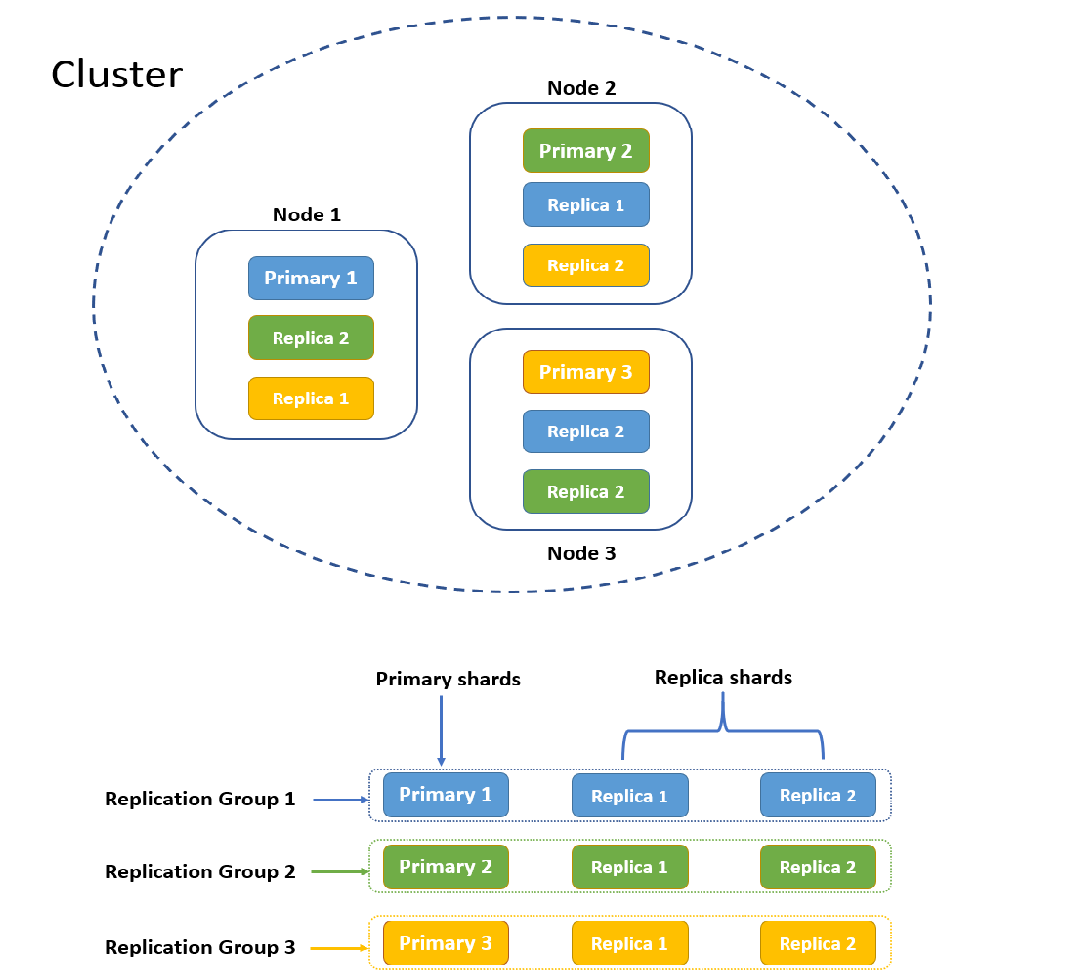
理解以下核心概念对部署和排错至关重要:
- 集群:一个Elasticsearch集群由多个节点组成,共同工作以提供高可用性和扩展性。
- 节点:一个运行中的Elasticsearch实例。
- 索引:存储和管理相关数据的逻辑容器,类似于关系型数据库中的“表”。
- 分片:
- 主分片:用于处理数据写入和存储,每个索引在创建时需定义主分片数。
- 副本分片:主分片的拷贝,用于提供数据冗余和高可用性,支持读请求。
2. Elasticsearch安装部署
以下是基于RPM包在CentOS/RHEL系统上的安装步骤。
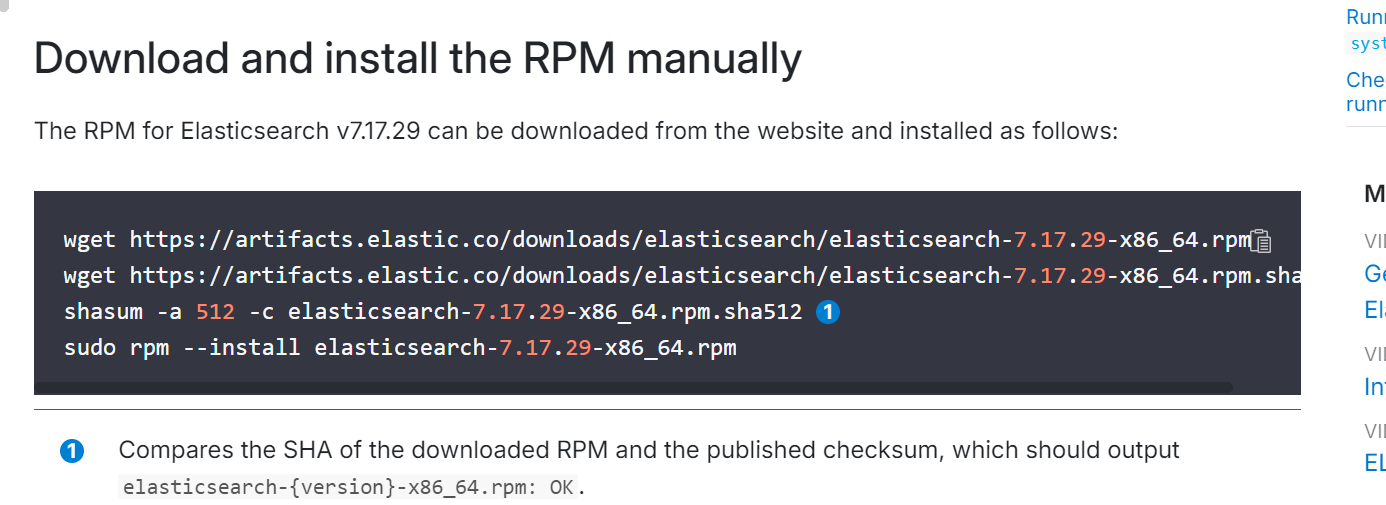
# 1. 下载RPM安装包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.16-x86_64.rpm
# 2. 安装RPM包
rpm -ivh elasticsearch-7.17.16-x86_64.rpm
# 3. 编辑配置文件
cd /etc/elasticsearch/
vi elasticsearch.yml
关键的配置项如下:
cluster.name: my-cluster
node.name: node-1
path.data: /data/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.5.5"]
cluster.initial_master_nodes: ["192.168.5.5"]
继续执行以下命令完成部署:
# 4. 创建数据目录并授权
mkdir -p /data/elasticsearch
chown -R elasticsearch:elasticsearch /data/elasticsearch
# 5. 启动服务
systemctl start elasticsearch
# 6. 检查服务端口
netstat -nlpt | grep java
# 应看到9200 (HTTP API) 和9300 (集群通信) 端口

3. 检查Elasticsearch集群状态
使用curl命令验证集群是否健康运行。
curl -XGET 127.0.0.1:9200/_cluster/health\?pretty
返回结果中,status字段是关键:
- green:集群健康,所有主分片和副本分片均已分配。
- yellow:所有主分片已分配,但部分副本分片未分配。单节点集群通常为此状态,功能正常。
- red:有主分片未分配,集群功能不全。
{
"cluster_name" : "my-cluster",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 3,
"active_shards" : 3,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
常用集群管理命令:
# 查看集群健康摘要
curl -XGET 127.0.0.1:9200/_cat/health?v
# 查看主节点
curl -XGET 127.0.0.1:9200/_cat/master?v
# 查看所有节点
curl -XGET 127.0.0.1:9200/_cat/nodes?v
# 查看所有索引
curl localhost:9200/_cat/indices?v
4. Kibana安装与配置
Kibana是日志的可视化界面。
# 下载并安装Kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.17.16-x86_64.rpm
rpm -ivh kibana-7.17.16-x86_64.rpm
# 编辑配置文件,连接到Elasticsearch
cd /etc/kibana/
vi kibana.yml
配置示例:
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://192.168.5.5:9200"]
# 启动Kibana服务
systemctl start kibana
# 验证端口
netstat -nltp | grep 5601
访问 http://<服务器IP>:5601 即可打开Kibana界面。
5. Filebeat安装与配置
Filebeat作为采集端,这里配置其收集系统日志。
注:Filebeat的 filestream input类型专用于从日志文件中进行长时采集。
# 1. 添加Elastic GPG密钥并配置Yum仓库
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
cat > /etc/yum.repos.d/elastic.repo << EOF
[elastic-7.x]
name=Elastic repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF
# 2. 安装Filebeat
dnf -y install filebeat-7.17.15
# 3. 配置Filebeat
cd /etc/filebeat/
vi filebeat.yml
主要配置修改处:
filebeat.inputs:
- type: filestream
enabled: true
paths:
- /var/log/*.log
- /var/log/messages*
- /var/log/elasticsearch/*.log
output.elasticsearch:
hosts: ["192.168.5.5:9200"]
# 4. 启动Filebeat
systemctl start filebeat
# 5. 可以查看Filebeat自己的日志观察采集状态
tail -f /var/log/messages
6. 在Kibana中查看日志
Filebeat启动后会自动在Elasticsearch中创建索引。登录Kibana,查看数据是否成功采集。
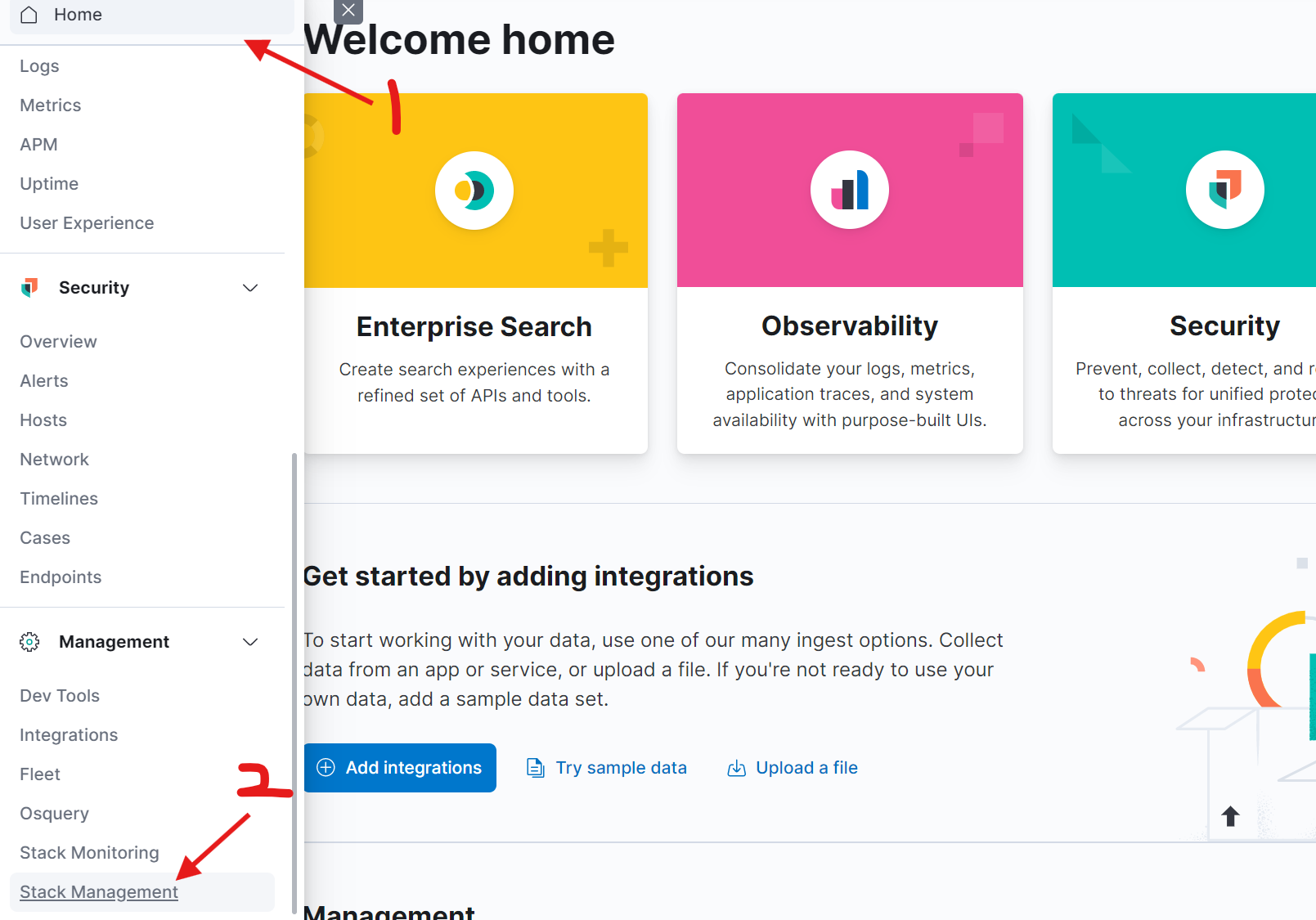
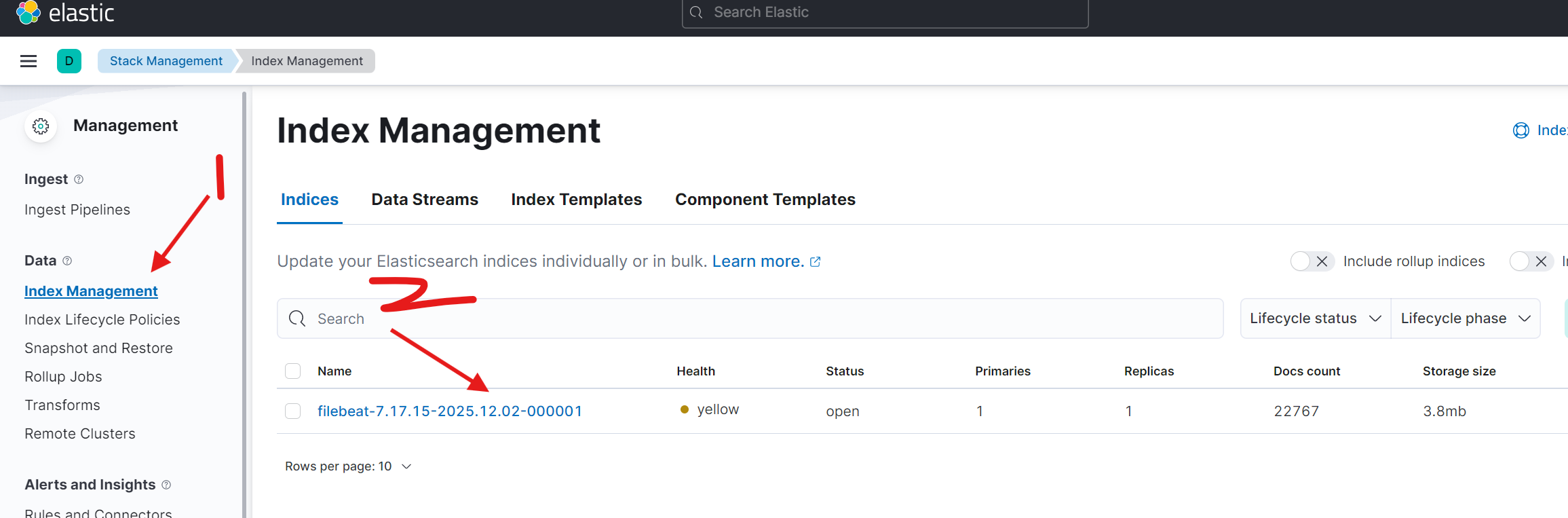
索引名格式通常为 filebeat-7.17.15-2025.12.02-000001。如果按天滚动,后续索引名会包含日期,例如:
app-name-2025.12.02app-name-2025.12.03
注:单节点Elasticsearch集群的索引状态可能为yellow,这是因为副本分片无法分配(需要其他节点),但数据采集和搜索功能完全正常。
接下来,需要在Kibana中创建索引模式来匹配这些索引,以便进行搜索和可视化。
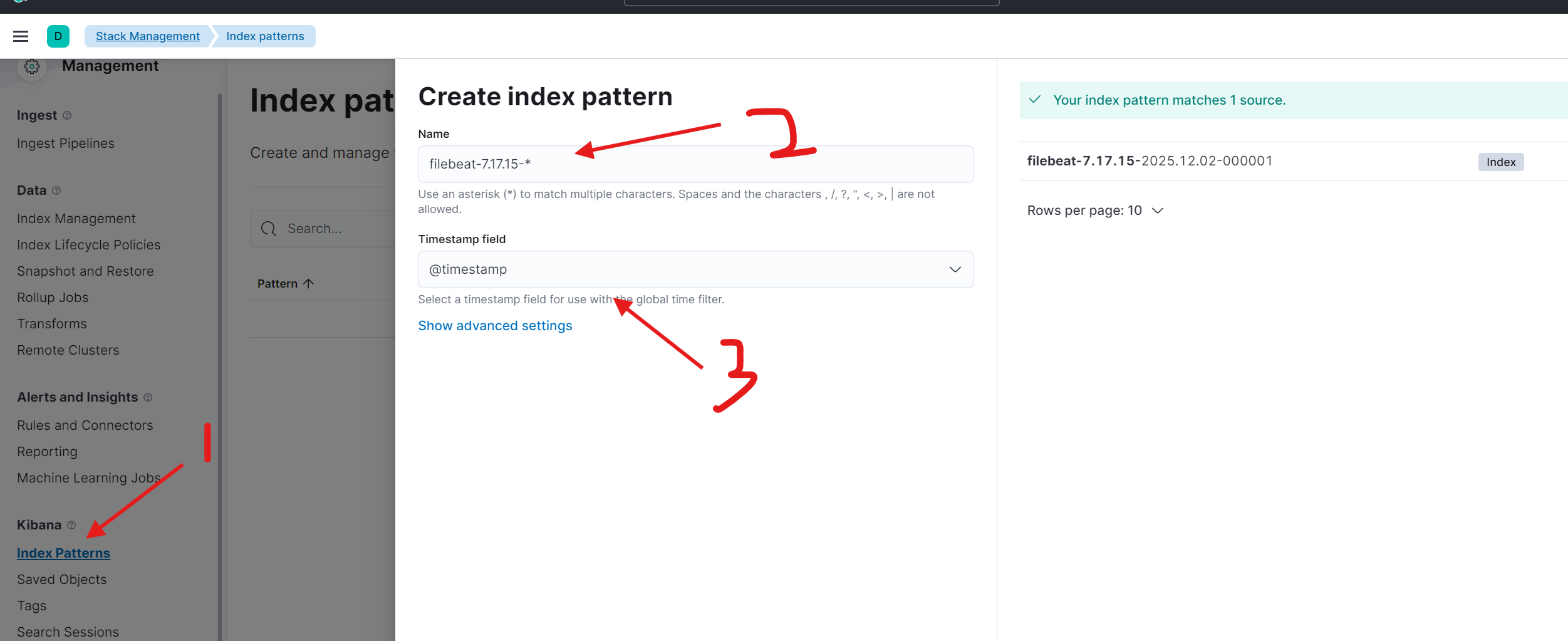
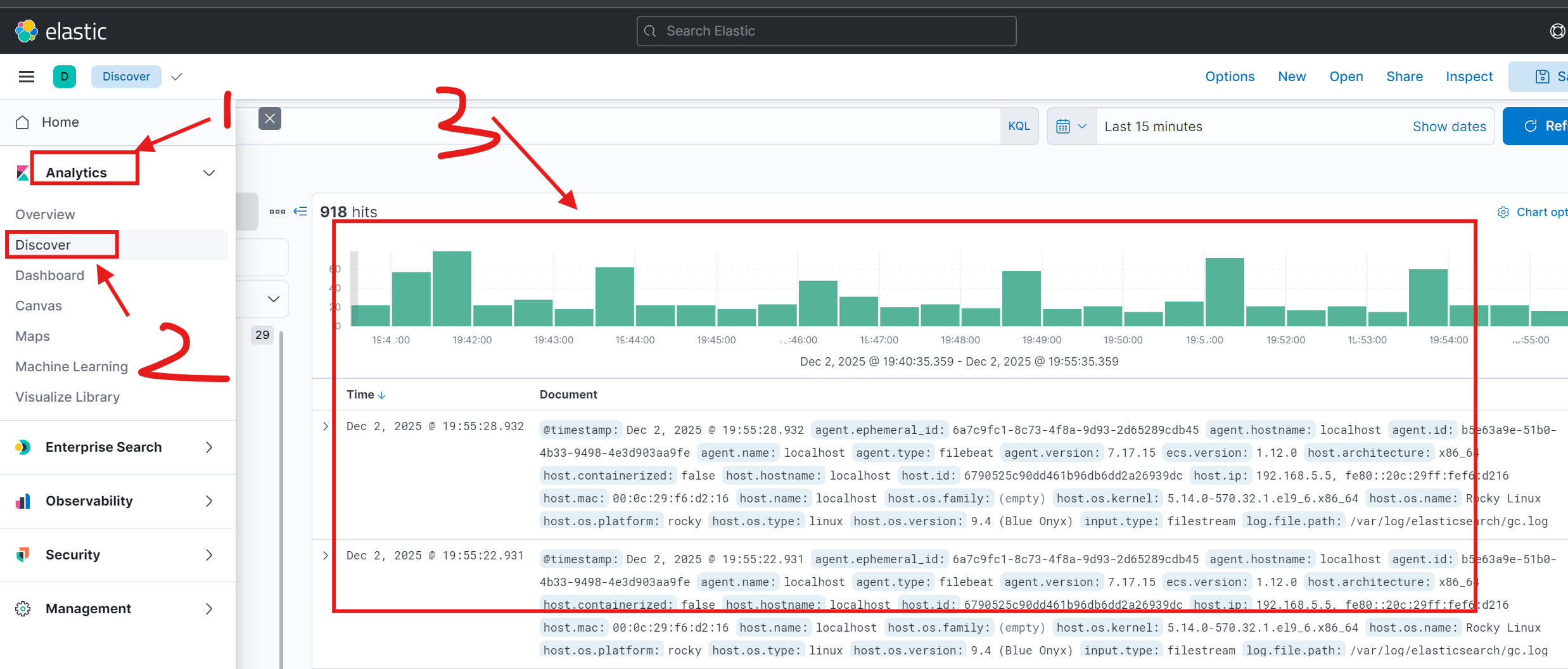
创建成功后,即可在 Discover 页面查看和分析采集到的日志数据。
三、Kubernetes集群架构下的EFK部署
在Kubernetes中部署EFK,我们采用Helm Chart方式,这能极大地简化运维部署和管理流程。
1. 使用Helm部署Elasticsearch
首先添加Elastic官方的Helm仓库并拉取Chart。
# 添加Elastic Helm仓库
helm repo add elastic https://helm.elastic.co
# 搜索特定版本的Elasticsearch Chart (本文使用7.17.3)
helm search repo elastic/elasticsearch -l
# 拉取Chart包到本地
helm pull elastic/elasticsearch --version=7.17.3
tar xf elasticsearch-7.17.3.tgz
cd elasticsearch/
编辑 values.yaml 文件,根据需求调整配置,例如设置副本数和资源限制。
# 示例配置片段
replicas: 2 # 设置两个ES节点实例
resources:
requests:
cpu: "500m"
memory: "1Gi"
limits:
cpu: "500m"
memory: "1Gi"
persistence:
enabled: false # 测试环境可禁用持久化存储,生产环境务必开启
使用Helm在指定的命名空间(如logging)中部署Elasticsearch。
helm upgrade --install els -n logging ./elasticsearch --create-namespace --namespace logging
检查Pod状态,并验证集群健康度。
kubectl -n logging get pod -o wide
# 获取Elasticsearch Pod的IP并检查集群状态
curl <Pod-IP>:9200/_cluster/health?pretty
输出显示 "status" : "green" 且 "number_of_nodes" : 2 即表示部署成功。
2. 使用Helm部署Kibana
以类似的方式部署Kibana。
helm pull elastic/kibana --version=7.17.3
tar xf kibana-7.17.3.tgz
cd kibana/
修改 values.yaml,例如设置Service类型为NodePort以便外部访问。
resources:
requests:
cpu: "500m"
memory: "1Gi"
service:
type: NodePort
执行安装命令:
helm -n logging upgrade --install kibana ./kibana
查看Service,获取Kibana的访问端口。
kubectl -n logging get svc
# 找到 kibana-kibana 服务,其NodePort即为外部访问端口(如32051)
通过 http://<NodeIP>:<NodePort> 即可访问Kibana界面。
3. 使用Helm部署Filebeat (DaemonSet)
Filebeat将以DaemonSet形式部署到每个Kubernetes节点上,采集容器日志。
helm pull elastic/filebeat --version=7.17.3
tar xf filebeat-7.17.3.tgz
cd filebeat/
关键的配置在于修改 values.yaml 中的 filebeat.yml 部分,使其能够采集容器日志并添加Kubernetes元数据。
# values.yaml 关键配置示例
daemonset:
enabled: true
filebeatConfig:
filebeat.yml: |
filebeat.inputs:
- type: container
paths:
- /var/log/containers/*.log
processors:
- add_kubernetes_metadata:
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: "/var/log/containers/"
output.elasticsearch:
hosts: '${ELASTICSEARCH_HOSTS:elasticsearch-master:9200}'
resources:
requests:
cpu: "200m"
memory: "200Mi"
limits:
cpu: "1000m"
memory: "2000Mi"
部署Filebeat:
helm -n logging install filebeat ./filebeat
稍等片刻,Filebeat Pod运行后,即可在Kibana中按照之前的步骤创建索引模式(例如 filebeat-7.17.3-*),然后在 Discover 页面查看采集到的Kubernetes容器日志。
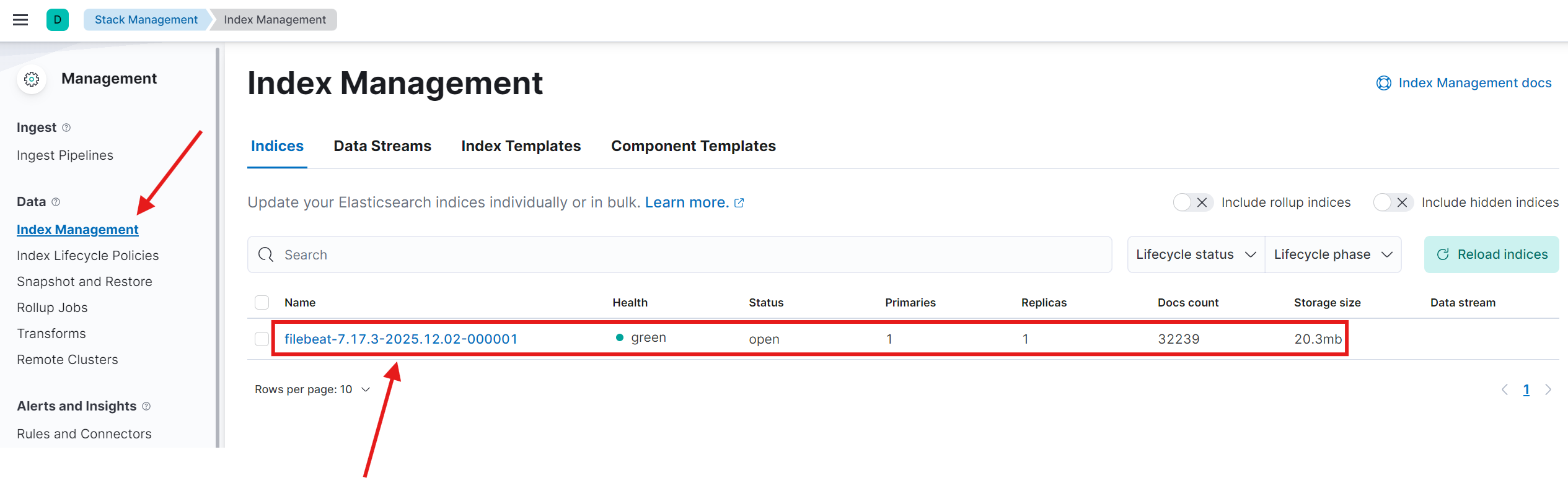
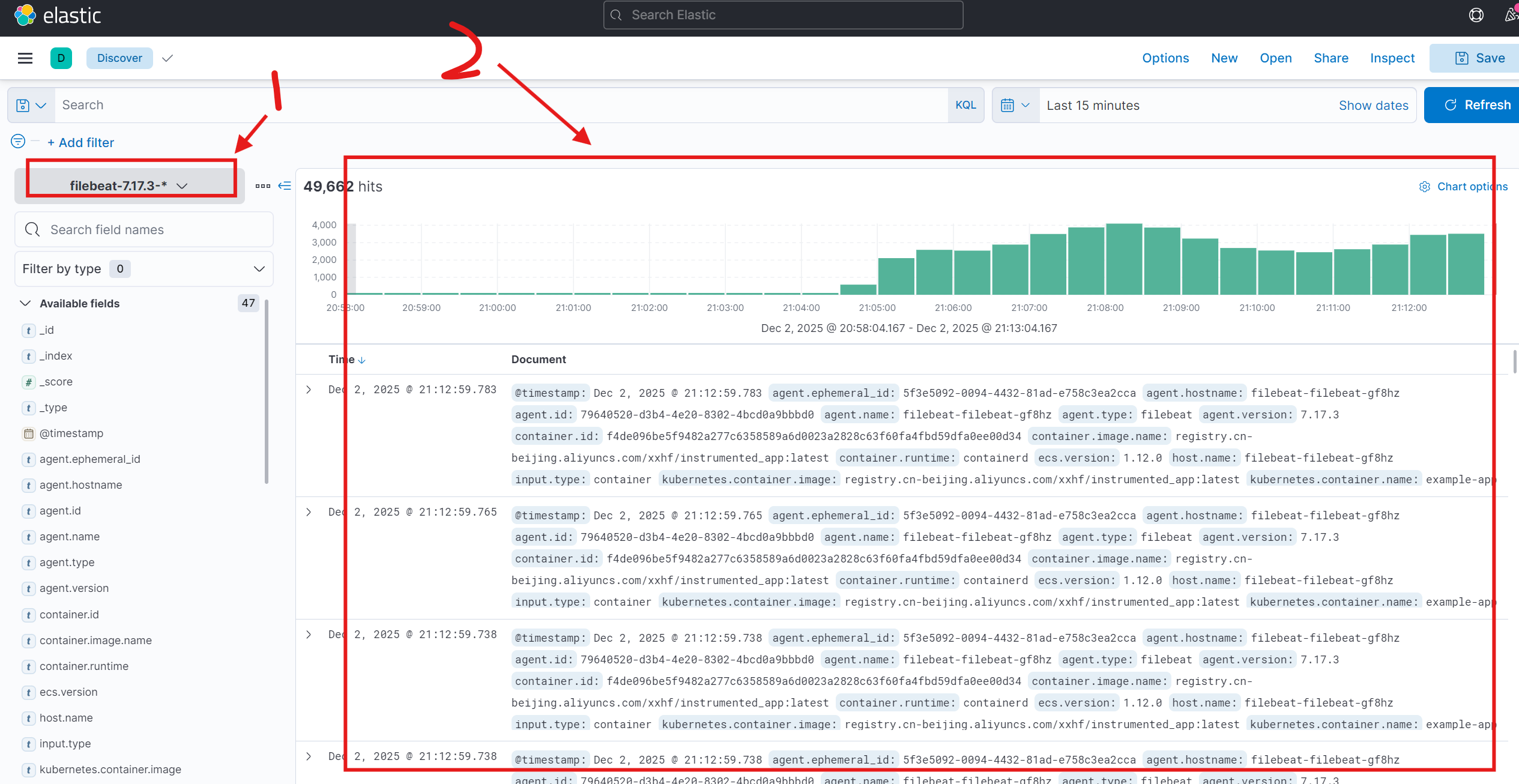
4. 进阶:按应用配置索引
默认配置下,所有日志可能进入同一个索引。为了更好的管理,可以配置Filebeat,使其按容器名或Pod名生成不同的索引。
创建一个自定义的values文件,例如 filebeat-values.yaml:
daemonset:
enabled: true
filebeatConfig:
filebeat.yml: |
filebeat.inputs:
- type: container
paths:
- /var/log/containers/*.log
processors:
- add_kubernetes_metadata:
in_cluster: true
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: "/var/log/containers/"
setup.ilm.enabled: false # 禁用索引生命周期管理
output.elasticsearch:
hosts: '${ELASTICSEARCH_HOSTS:elasticsearch-master:9200}'
index: "%{[kubernetes.container.name]}-%{+yyyy.MM.dd}" # 按容器名和日期生成索引
使用新的配置更新已部署的Filebeat:
helm upgrade filebeat -f filebeat-values.yaml ./filebeat -n logging
更新后,Elasticsearch中将会出现类似 calico-node-2025.12.02、filebeat-2025.12.02 这样的索引,实现了按应用维度的日志分离,便于管理和查询。
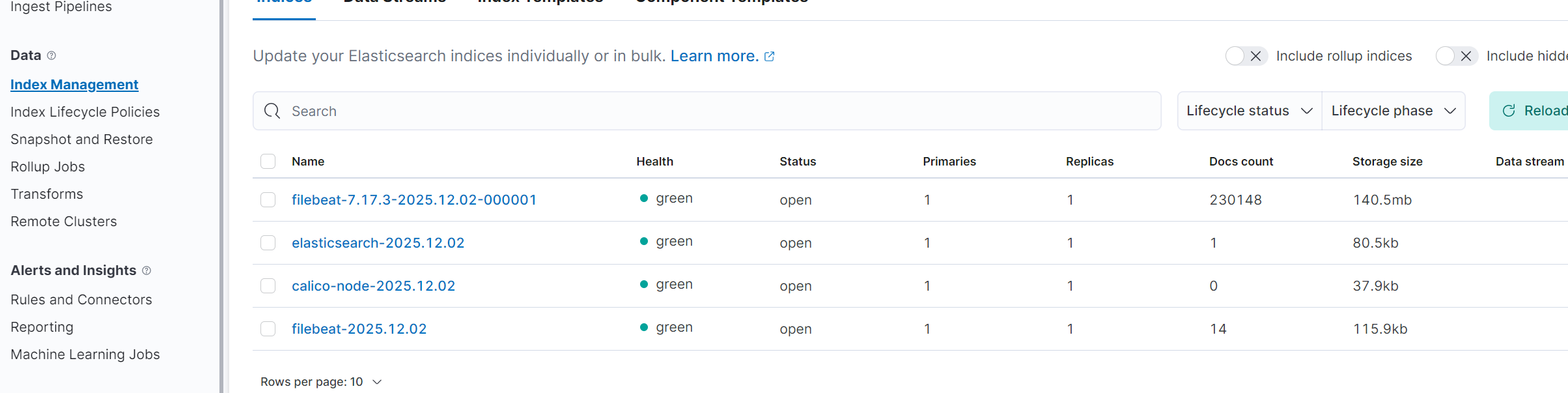
 发表于 2025-12-14 07:31:49
|
查看: 194|
回复: 0
发表于 2025-12-14 07:31:49
|
查看: 194|
回复: 0
