智能体(Agent),即基于语言模型且具备推理、规划和行动能力的系统,正在成为现实世界 AI 应用的主导范式。尽管其已被广泛采用,但决定其性能的原则仍未被充分探索,导致从业者只能依赖启发式经验,而非有原理依托的设计选择。
谷歌近期发布的一项大规模实证研究,填补了这一关键空白。通过系统性的实验,他们为智能体系统找到了可量化的扩展原则(Scaling Law)。
研究将智能体系统的扩展定义为智能体数量、协作结构、模型能力和任务属性之间的复杂相互作用。为了量化这些关系,研究团队在四个不同基准上展开了评估:Finance-Agent(金融推理)、BrowseComp-Plus(网络导航)、PlanCraft(游戏规划)和 Workbench(工作流执行)。
研究采用了五种典型的智能体(Agent)架构设计(单智能体系统以及四种多智能体系统:独立型、中心化、去中心化、混合型),并在三大主流LLM家族(OpenAI GPT, Google Gemini, Anthropic Claude)中进行实例化。通过对180种配置进行受控评估,并标准化工具、提示和token预算,研究成功将架构效应与具体实现细节隔离开来。

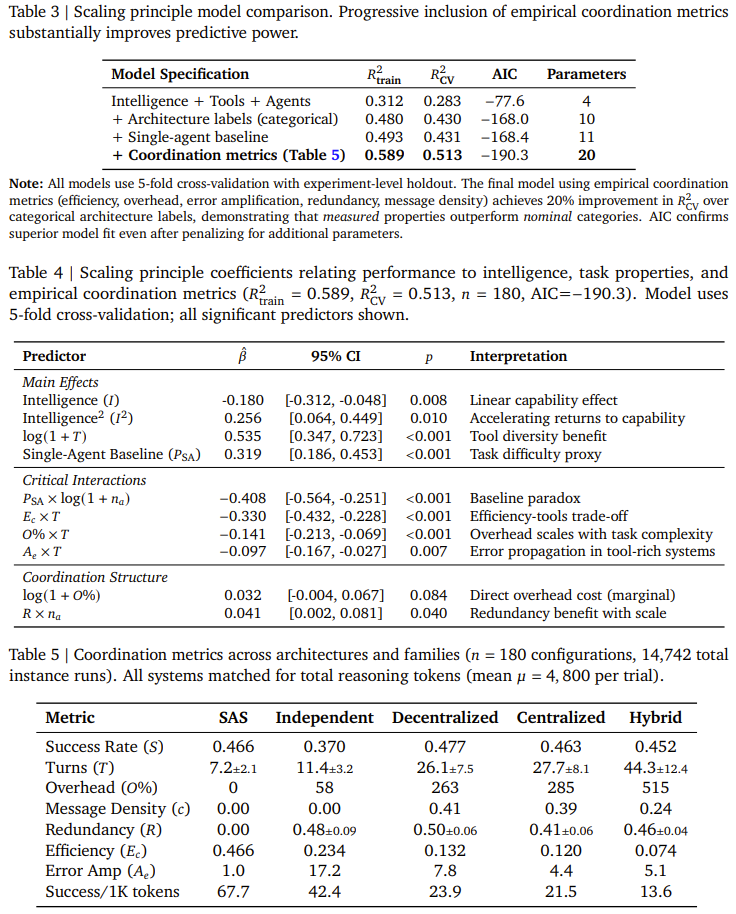
基于经验性的协作指标(包括效率、开销、错误放大和冗余),团队最终推导出一个预测模型。该模型在交叉验证中取得了R²=0.513的拟合度,其关键优势在于能够通过对通用任务属性建模,来预测未见任务领域的性能,而非过度拟合特定数据集。谷歌表示,该框架在预测保留任务的最佳架构方面实现了87%的准确率,为智能体的部署决策首次提供了强有力的原则性支撑。
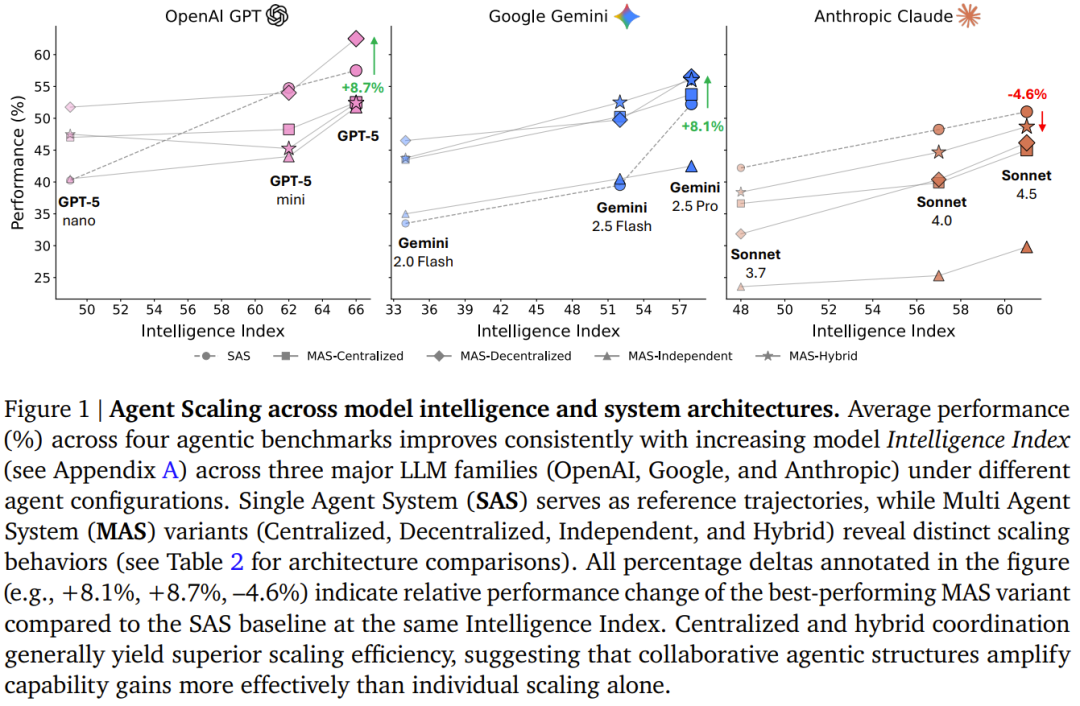
核心发现:任务类型是决定协作成败的关键
传统观念认为“人多力量大”,但这项研究揭示了更为复杂的真相:多智能体协作的效用高度依赖于具体任务的性质。
- 适合协作的“红榜”任务:在如金融分析(Finance-Agent)这类可分解、可并行的任务中,多智能体协作能带来巨大收益。例如,采用中心化架构(一个“指挥官”分派子任务)可使性能提升高达80.9%。任务被有效拆分后,各智能体能够并行工作,极大提升效率。
- 避免协作的“黑榜”任务:在如游戏规划(PlanCraft)这类步骤强依赖、环环相扣的任务中,引入多智能体协作反而会导致性能严重下降(39% 到 70%)。因为拆分任务会产生巨大的沟通与协调开销,甚至抵消掉个体智能体的推理能力。
阻碍扩展的三大核心瓶颈
研究进一步量化了影响智能体系统扩展效率的三个关键瓶颈:
- 工具-协作权衡:当任务需要使用的工具数量过多(例如超过16个API)时,引入多智能体协作往往会适得其反。密集的工具调用会带来巨大的沟通开销,导致系统整体速度变慢、准确率下降。
- 能力饱和效应:这是一个反直觉的发现。当单智能体基线性能已经足够高(例如准确率超过45%)时,再增加智能体进行协作,其带来的边际收益很可能为负,即出现“帮倒忙”的现象。
- 错误放大效应:在没有中心协调的独立型架构中,智能体之间的错误会相互传播并指数级放大,实验测得错误放大率高达17.2倍。而引入中心化“指挥官”进行管理后,能将错误放大率有效控制在4.4倍左右,凸显了架构设计的重要性。
研究还发现,不同厂商的模型在协作中表现出鲜明的“性格”差异:
- Google Gemini:高效的层级管理者。在中心化架构下表现卓越,尤其在金融任务中带来了+164.3%的性能提升。数据显示其执行力强,在不同架构间的性价比最为平衡。
- OpenAI GPT:复杂的沟通协调者。在混合型架构(Hybrid)中表现最佳,能够有效驾驭智能体间复杂的横向与纵向通信网络,展现出独特的“通信协同效应”。
- Anthropic Claude:稳健的保守派。对协作开销极为敏感,沟通复杂度上升会导致其成本急剧增加。它最适合简单的中心化架构,且是唯一在“弱指挥官带强兵”的异构混合模式下仍能提升性能的模型,显示出独特的容错性。
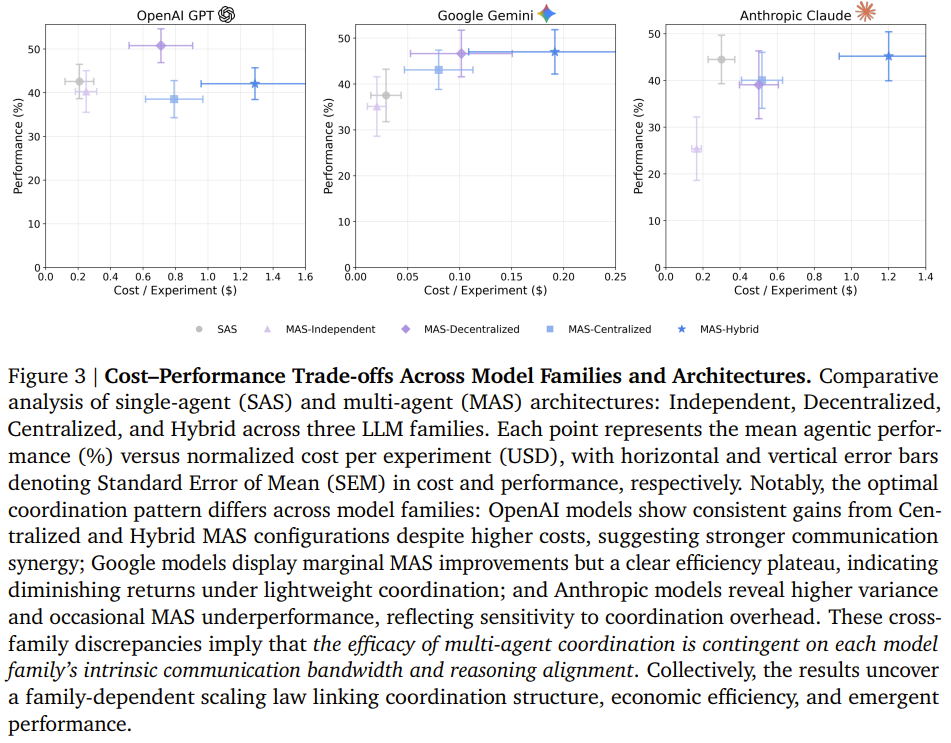
从“炼金术”到“可预测工程”
最终,基于效率、开销、错误放大率等硬指标,谷歌团队构建了一个实用的预测模型。该模型能够以高准确率指导开发者为特定任务和模型选择最优的智能体架构(单智能体、中心化、去中心化等)。
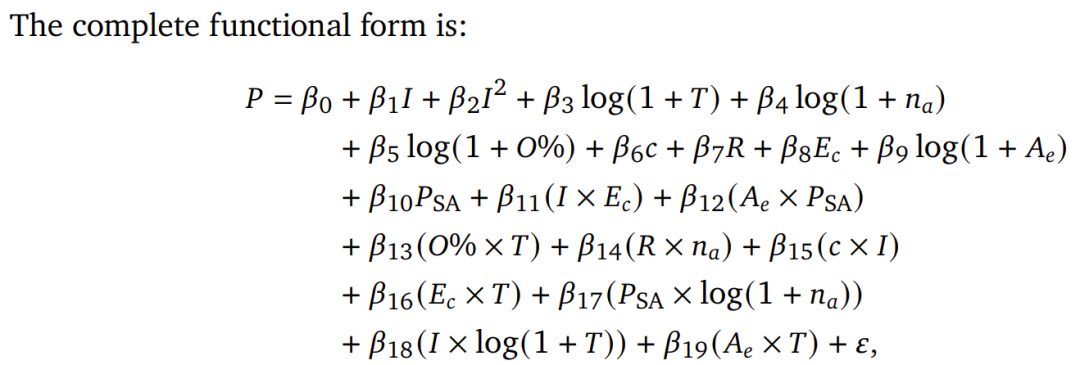
这项研究标志着智能体系统的设计开始从依赖经验的“炼金术”阶段,迈向有理论依据、可计算预测的“化学”时代,为构建更可靠、高效的大型智能体应用奠定了坚实基础。 |  发表于 2025-12-14 14:28:35
|
查看: 213|
回复: 0
发表于 2025-12-14 14:28:35
|
查看: 213|
回复: 0
