Perl曾因其强大的文本处理能力,被冠以“脚本语言中的瑞士军刀”的美誉。
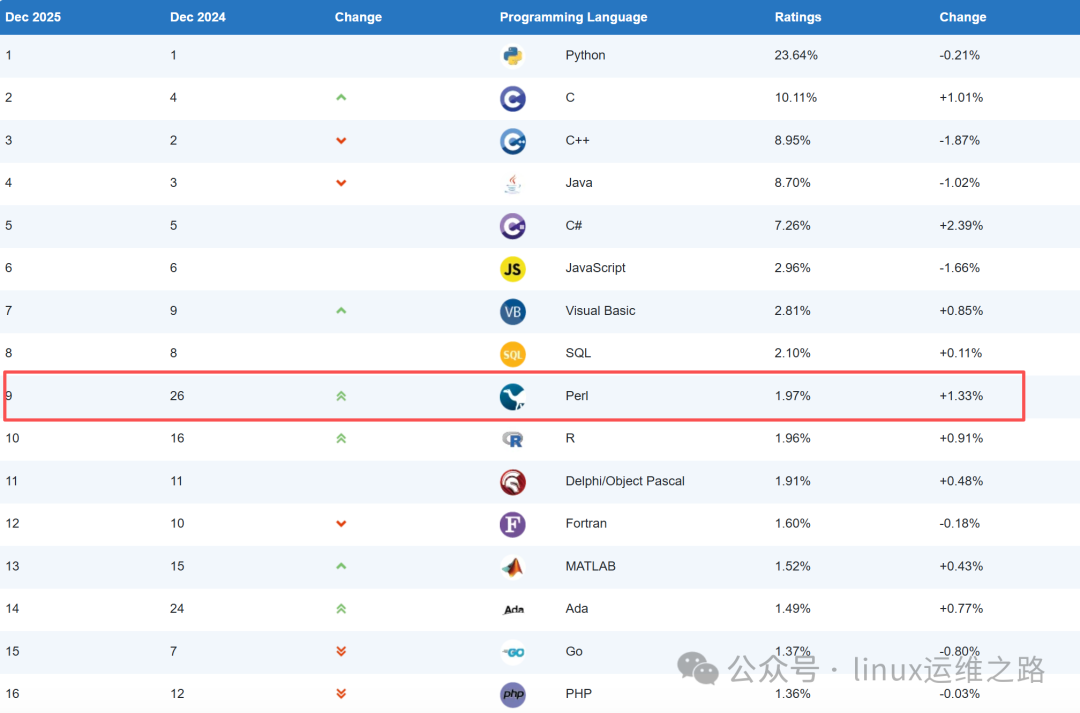
近期,在2025年9月的TIOBE编程语言排行榜中,Perl时隔二十年再次跻身前十。这无疑提醒我们,在Python、Go等现代语言盛行的当下,这位“老将”在特定领域——尤其是运维/DevOps自动化中——依然拥有着独特的、难以被完全替代的价值。
对于Linux运维工程师而言,Shell脚本是日常工作基础。但在处理复杂的文本解析、批量文件操作时,繁琐的转义和命令组合常常令人头疼。Perl恰好能弥补Shell的短板,它继承了命令行操作的便捷性,并提供了更强大、更严谨的语法特性,能显著提升工作效率。下面通过几个典型场景进行对比说明。
场景一:批量处理含特殊字符的文件名
运维中常需处理从Windows系统上传的文件,这些文件名可能包含空格、&、$等特殊字符。例如文件 Fibber&Molly (10-1-47) “Fibber‘s lost $” (v\g snd!).mp3,若在Shell中使用mpg123播放,需要大量转义:
mpg123 Fibber\&Molly\ \(10-1-47\)\ \"Fibber\'s\ lost\ \\$\"\ \(v\\\\g\ snd\!\).mp3
若需批量重命名此类文件,使用Shell脚本需要复杂的sed命令和条件判断。而使用Perl,核心逻辑可以非常简洁:
#!/usr/bin/perl
foreach my $file_name (@ARGV) {
my $new_name = $file_name;
# 批量替换特殊字符
$new_name =~ s/[\s\t]/_/g; # 空格/制表符转下划线
$new_name =~ s/[&]/_and_/g; # & 转 _and_
$new_name =~ s/[\$\`\'\"]/_/g; # $`'" 等转下划线
$new_name =~ s/[<>\\()]/x/g; # 括号等转 x
# 处理重名冲突
if (-f $new_name) {
my $ext = 0;
$ext++ while (-f “$new_name.$ext”);
$new_name .= “.$ext”;
}
rename $file_name, $new_name && print “$file_name -> $new_name\n”;
}
执行命令 perl fix_names.pl Fibb* 即可完成批量重命名。Perl原生支持强大的正则表达式,无需依赖外部命令如sed或awk,语法更统一,执行效率也更高。
场景二:高效的日志分析与统计
分析Nginx访问日志是运维日常工作。例如,统计访问量TOP 10的IP地址。使用Shell命令组合通常如下:
awk ‘{print $1}’ /var/log/nginx/access.log | grep -E ‘^[0-9]+\.’ | sort | uniq -c | sort -nr | head -10
此命令链存在局限:难以过滤无效IP、处理海量日志时性能不佳,且扩展新维度(如按小时统计)需重构整个管道。改用Perl脚本,则逻辑清晰且易于扩展:
#!/usr/bin/perl
use strict;
use warnings;
use Time::Piece; # Perl内置时间处理模块
my (%ip_count, %hour_count);
open my $log_fh, ‘<’, ‘/var/log/nginx/access.log’ or die “打开日志失败: $!”;
while (my $line = <$log_fh>) {
# 正则匹配IP与时间戳(适配Nginx通用日志格式)
if ($line =~ /^(\d+\.\d+\.\d+\.\d+)\s+-\s+-\s+\[(.*?)\]/) {
my $ip = $1;
my $time_str = $2;
# 解析时间,获取小时
my $hour = Time::Piece->strptime($time_str, “%d/%b/%Y:%H:%M:%S %z”)->hour;
$ip_count{$ip}++;
$hour_count{$hour}++;
}
}
close $log_fh;
# 输出IP访问TOP10
print “=== 访问量TOP10 IP ===\n”;
my $count = 0;
foreach my $ip (sort { $ip_count{$b} <=> $ip_count{$a} } keys %ip_count) {
printf “%-15s %d次\n”, $ip, $ip_count{$ip};
last if ++$count >= 10;
}
# 输出每小时访问分布
print “\n=== 每小时访问量 ===\n”;
foreach my $hour (sort { $a <=> $b } keys %hour_count) {
printf “%02d:00-%02d:59 %d次\n”, $hour, $hour, $hour_count{$hour};
}
该脚本不仅能准确统计IP,还能轻松扩展出分小时访问趋势。得益于内置的Time::Piece等模块,Perl在时间和字符串处理上比依赖外部命令的Shell脚本更具优势,跨平台兼容性更好。
Perl拥有极其丰富的模块生态(CPAN),几乎能找到任何你需要的工具。

场景三:构建可靠的系统监控与报警
监控服务器内存使用率并在超阈值时触发报警是常见的自动化需求。一个简单的Shell脚本实现可能如下:
#!/bin/bash
MEM_THRESHOLD=80
USED_MEM=$(free -m | grep Mem | awk ‘{print $3/$2*100}‘ | cut -d. -f1)
if [ $USED_MEM -gt $MEM_THRESHOLD ]; then
echo “内存使用率超过阈值!当前:$USED_MEM%” | mail -s “内存报警” admin@example.com
fi
此脚本的兼容性较差(free命令输出格式可能因发行版而异),且错误处理机制薄弱。使用Perl配合CPAN模块,可以构建更健壮的监控脚本:
#!/usr/bin/perl
use strict;
use warnings;
use Net::SMTP; # 邮件发送模块
# 配置参数
my $MEM_THRESHOLD = 80;
my $SMTP_SERVER = ‘smtp.example.com’;
my $FROM = ‘monitor@example.com’;
my $TO = ‘admin@example.com’;
# 解析内存信息
my $mem_info = `free -m`;
my ($total_mem, $used_mem) = $mem_info =~ /Mem:\s+(\d+)\s+(\d+)/;
my $used_rate = sprintf(“%.0f”, $used_mem / $total_mem * 100);
# 报警逻辑
if ($used_rate > $MEM_THRESHOLD) {
my $smtp = Net::SMTP->new($SMTP_SERVER, Timeout => 10)
or die “连接SMTP服务器失败: $!”;
$smtp->mail($FROM);
$smtp->to($TO);
$smtp->data();
$smtp->datasend(“Subject: 内存使用率报警\n”);
$smtp->datasend(“当前内存使用率:$used_rate%\n”);
$smtp->datasend(“总内存:$total_mem MB,已用:$used_mem MB\n”);
$smtp->dataend();
$smtp->quit();
print “报警邮件已发送\n”;
} else {
print “内存状态正常,使用率:$used_rate%\n”;
}
Perl脚本通过正则直接提取数据,避免了管道命令的格式解析问题。Net::SMTP等模块提供了比系统mail命令更稳定、功能更全的通信能力,方便集成身份验证。当需要增加对网络/系统中CPU、磁盘等指标的监控时,代码结构也更容易扩展和复用。
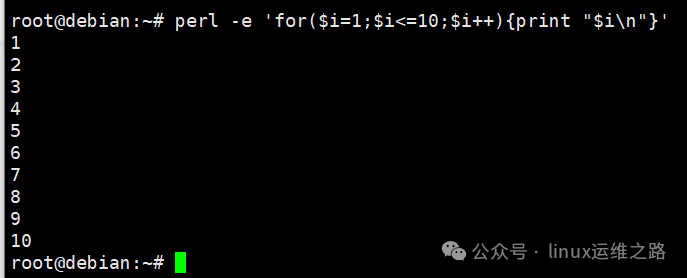
Perl的另一个优势是其普遍性:它是多数Linux发行版和Unix-like系统预装的解释器。其“一行式”命令模式能快速解决许多临时性任务,语法灵活。例如,用类似C语言的风格循环输出数字:
perl -e ‘for($i=1;$i<=10;$i++){print “$i\n”}’
综上所述,Perl这位“运维老伙计”正重新进入开发者视野。如果你时常受限于Shell脚本的复杂转义与功能局限,重新审视并学习Perl或许会带来惊喜。它在文本处理、日志解析、系统管理等领域,依然是一把趁手的“效率利器”。当然,其高度灵活的语法也要求开发者注重代码规范,以保障脚本的长期可维护性。
 发表于 2025-12-14 20:29:59
|
查看: 225|
回复: 0
发表于 2025-12-14 20:29:59
|
查看: 225|
回复: 0
