在完成一个RAG项目后,我对技术演进进行了总结,并整理了外部变化和演化方向,发现其中涉及的新范式、生态演变和检索策略值得深入探讨。
RAG相关新范式
动态检索(AgenticRAG)
主要是在检索侧做的改进:
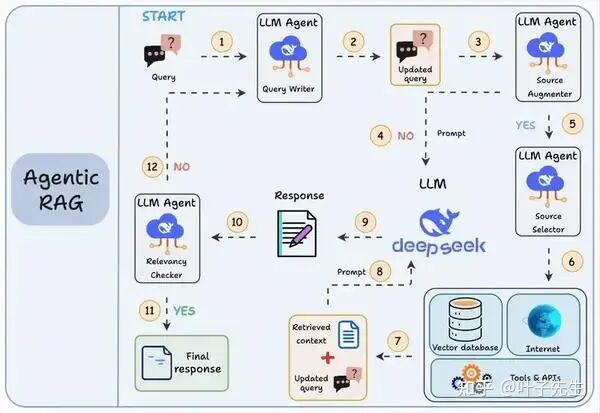
AgenticRAG 实际就是把向量数据库(知识库)作为 agent 的一个 tool,交由 agent 判断是否使用。由 agent 自己决定检索什么、检索多少,以做到动态检索。在此基础上还会增加横向扩展,比如多 retrieve agents 嵌套,通过多个检索 agent 给一个上级 agent 提供信息。相关的设计还有很多,但核心都是围绕“动态检索”这一思想进行设计的。
重点:解决传统 RAG 中的单来源、强制执行、一次交付的问题。
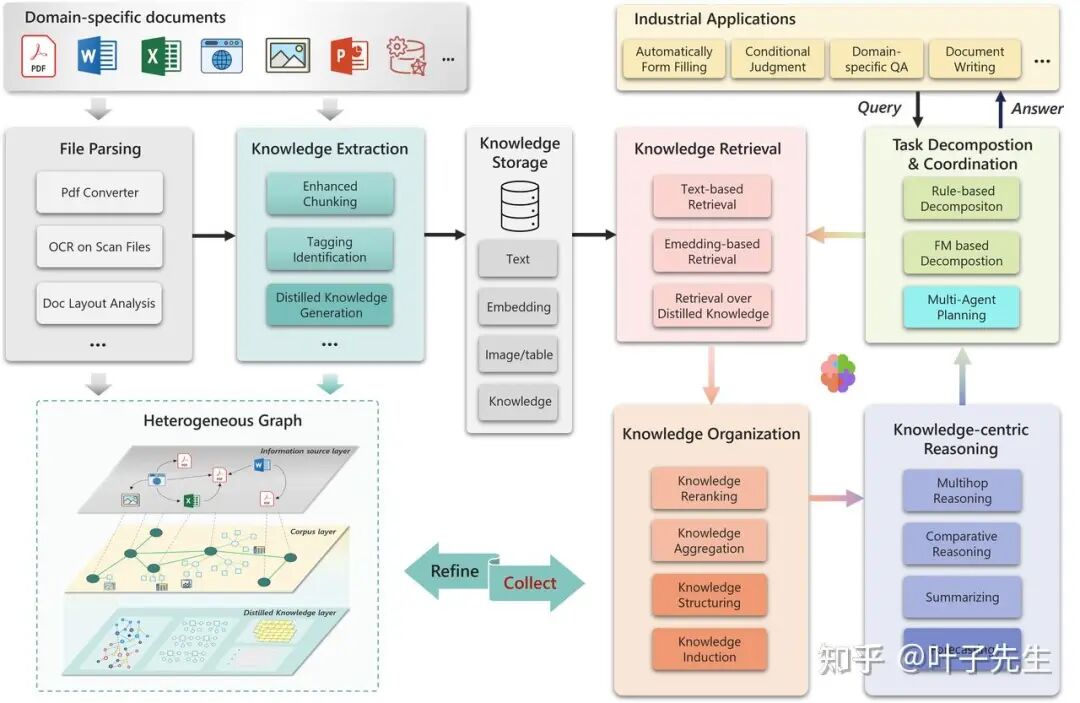
数据侧增强(PikeRAG、GraphRAG)
主要是在存储侧做的改进:
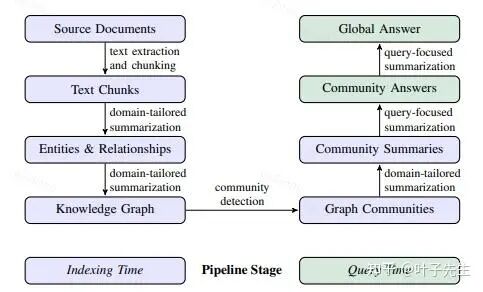
GraphRAG 采用两种方法:
- Local Search:局部检索在检索时依靠向量检索找到绝对实体,之后依靠 graph 在图中寻找它的相关关系,最后给大模型实体细节、关联实体细节及它们的关系。
- Global Search:全局检索在构建时通过聚类算法(如 Leiden 算法)将数据聚类为不同社区,然后靠 LLM 给社区做描述;检索时如果是全局检索,则不去寻找实体而是寻找社区及其描述,将相关社区描述汇总作为上下文,主要解决概括性问题。
GraphRAG 早期有成本问题,后续更新了 2.X 版本,引入了非 LLM 的实体抽取模型,以缓解成本。类似思想的轻量级方案还有 LightRAG。
PIKE-RAG:主要采用 atom_decompose 方法,在数据构建时对每段数据做增强。简单来说,通过大模型抽取实体和关系(类似 GraphRAG 的 Local Search),同时生成同语义但不同表述的回答作为辅助,最终在检索侧提高召回率和精确率。
这两个框架本质都是在存储侧做增强,并引入图结构以解决多跳问题和全局性问题。
重点:在输入数据层面做增强,强调检索的“关系”和“视野”。
纯多模态(ColPail)
抛弃 OCR,视觉即索引:
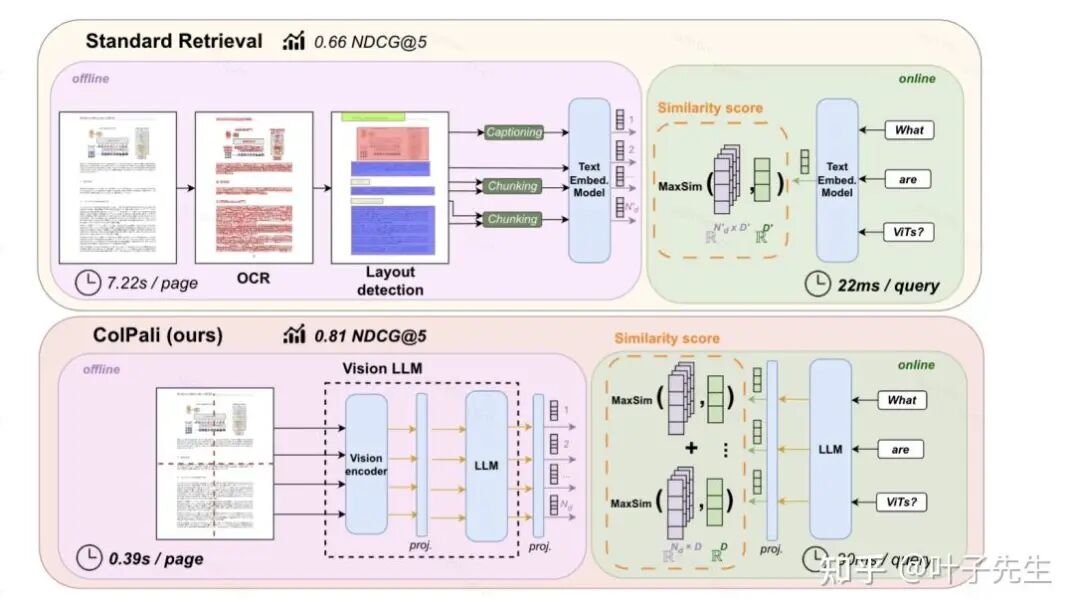
不再沿用传统的文字提取加 embedding 思路,而是直接在原始数据(如图片、PDF)上处理,切成小块并生成视觉向量。检索时,将 query 转为元 token,对每个词计算图的最大相似度,最后召回原始文本(或图像)块,给 VLM 作为上下文。
这种方式优缺点明显:
- 优点:在多模态场景下表现强,能直接处理表格、图片等。
- 缺陷:架构改变大,在线生态一般;元 token 切分在中文处理上较复杂;对输入数据有要求,如纯文本数据无法直接处理。
重点:直接依靠图进行整个 RAG 流程,具有天然多模态优势。
实际业界对图片的处理更多采用:
- 靠 VLLM 转为描述后走正常文本召回,然后给出原始数据。
- 结对处理,直接关联最近或最相关的多模态向量作为一对,召回时带回关联文本块。
长上下文(OP-RAG)
随着模型上下文长度增加,不再需要切分过碎的文本块。许多方法直接将全文或长片段返回,效果优于碎块。检索时依靠类似父子索引精确定位。相关研究如 OP-RAG 阐述了这种做法的可行性和有效性。
重点:模型能力增强,碎块作为检索单元的必要性降低。
生态地位的演变
从 2023 到 2025 年,RAG 技术的定位从保障大模型生成可靠性、解决幻觉的框架,演变为 agent 的 tool,成为上下文保障中不可或缺的工具。
核心变动包括:
- 由静态转向动态:模型能力增强,不再需要被动检索,而是由 agent 按需动态决定检索。
- agent 长期记忆的核心:扩展为 agent 的个性化长期记忆库,不限于文档知识库。
- 多模态势头:VLM 能力增强和成本降低,使 RAG 支持多模态场景。
- 数据结构堆叠与架构复杂性上升:定制化检索策略增多,引入知识图谱等手段解决全局性问题。
复杂检索策略
简单的混合检索(如 BM25 + 向量)在许多业务场景已足够,但数据维度增多或检索方向变化时,单一策略可能不足。外部项目已采用高度定制化检索策略,例如对特定字段建立额外索引、引入布尔过滤,或结合意图识别动态选择策略。重排(SR)和查询重写(QR)也属于复杂检索策略的一环。
意图识别
意图识别已成为 RAG 工业项目的标配,用于根据不同 query 选择检索策略和数据集。
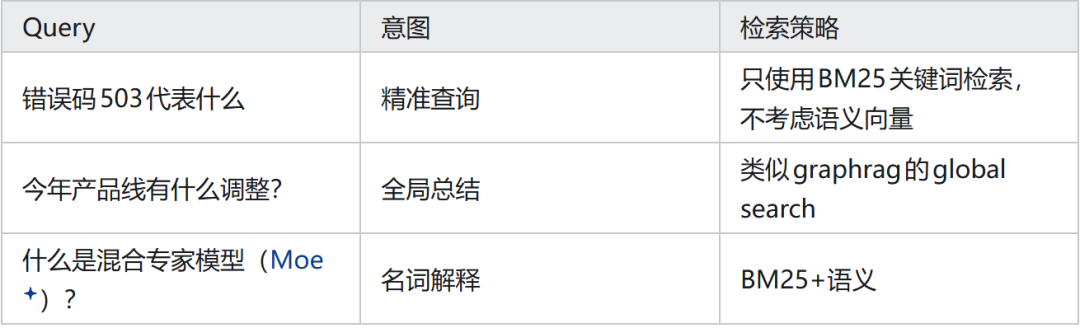
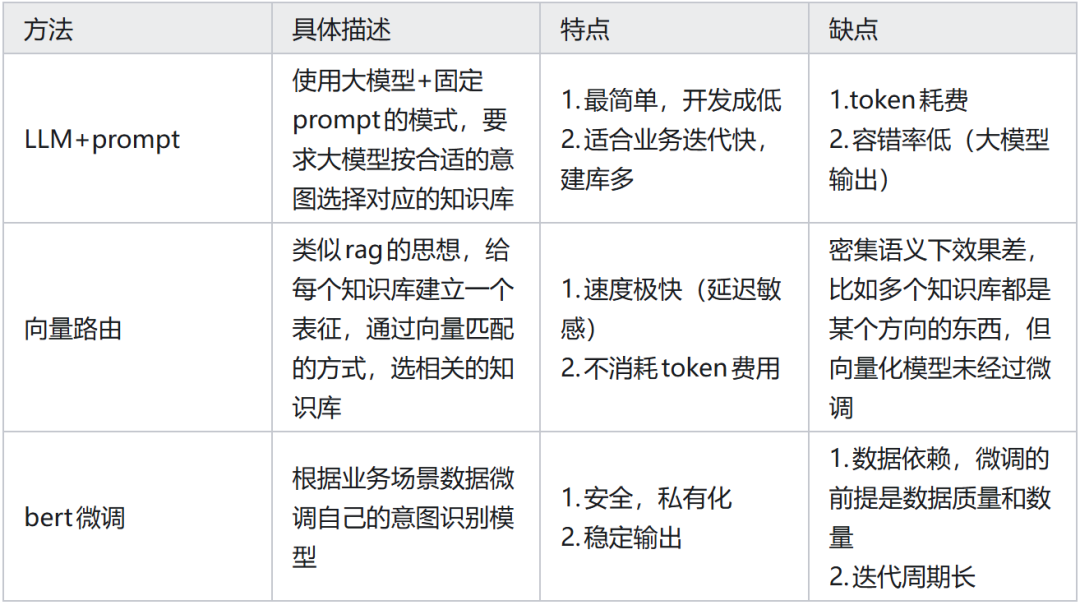
这部分与 agent 的 tool call 相似但有区别,主要在于容错率不同,可区分为软硬路由。实际落地不一定依赖单一意图识别模型,可能采用多种方法。
评测的重要性
从业务角度看,评测变得越来越关键,因为 RAG 系统规模扩大,评测成为验证和改进的核心。
RAG 评测的核心目的包括:
- 上线前验证系统的有效性,识别问题并改进。
- 在交付场景中证明系统的可靠性和效果。
- 对私域数据,重点关注安全性和敏感性。
评测是推进业务闭环的核心,只有建立有效的评测机制,才能持续优化架构、算法和数据,而非仅依赖业务需求或用户体验。
作者:叶子先生,已获授权发布。来源:https://zhuanlan.zhihu.com/p/1980034461144994052
 发表于 2025-12-14 20:27:21
|
查看: 188|
回复: 0
发表于 2025-12-14 20:27:21
|
查看: 188|
回复: 0
