DeepCode 是由香港大学 Data Intelligence Lab 开源的多智能体开发平台,支持 Paper2Code、Text2Web、Text2Backend 等能力,可以把研究论文、自然语言需求、URL 与各类技术文档,自动转化为可部署的生产级代码(含前端、后端、算法实现、测试和文档)。
痛点场景
- 论文复现太费人力:一篇算法复杂的顶会论文,从公式到工程实现往往需要数周时间。研究者常把精力耗费在“造轮子”上,而非模型与实验设计的思考。
- 从想法到原型的周期太长:即便是构建一个最小可行产品(MVP),从需求分析到前后端开发、测试部署,通常也需要数周。
- 重复性编码工作过多:大量的表单页面、增删改查接口、通用脚本编写占据了开发者本应用于创新性工作的宝贵精力。
- 复杂技术文档难以高效转化:技术规范、设计说明书等信息丰富但结构松散,人工提取和同步容易出现信息丢失或理解偏差。
DeepCode 的目标是:让AI多智能体系统接管繁琐、重复、结构化的开发工作,让开发者专注于“做什么”,而非“怎么写出来”。
核心功能
1. Paper2Code:论文到代码的自动实现引擎
- 从研究论文中抽取算法逻辑、数学模型和关键公式。
- 结合多模态文档分析引擎,自动选择合适的数据结构与实现方式。
- 官方在 OpenAI 的 PaperBench 基准测试中,要求从20篇 ICML 2024 论文“从零复现”代码,DeepCode 能够生成可直接运行的实现。
2. Text2Web:自然语言描述到前端页面
- 输入:一句话或一段文本描述的界面需求。
- 输出:完整的前端代码(含结构、样式、交互逻辑)。
- 目标:快速搭建视觉美观、响应式的页面原型,可直接用于评审或对接真实后端。
3. Text2Backend:从需求到后端服务
- 从自然语言需求出发,自动生成路由API接口、数据库表结构及基础业务逻辑代码。
- 强调生成高效、可扩展的后端实现,极大减少手写框架和样板代码的时间,特别适合快速搭建Python或Node.js后端原型。
4. Research-to-Production Pipeline:研究到生产的完整流水线
- 统一入口处理 PDF、DOC、PPTX、TXT、HTML、URL 等多种格式输入。
- 多模态文档分析引擎负责内容分段、结构识别和关键信息抽取,并将其转化为可操作的实现规范。
- 最终输出是可部署的完整代码仓库,包含测试与文档。
5. Natural Language Code Synthesis:上下文感知的代码生成
- 使用在精选代码仓库上微调过的语言模型。
- 确保生成的代码在整个项目层面保持架构一致性,支持多种编程语言和框架。
6. Automated Prototyping Engine:自动脚手架与原型生成
- 自动生成包含数据库 Schema、RESTful API 和前端 UI 组件骨架的完整应用结构。
- 利用依赖分析,从一开始就构建可扩展的架构。
7. Quality Assurance Automation:自动化质量保障
- 集成静态分析、单元测试生成与文档生成。
- 使用 AST 分析辅助检查代码正确性,并引入性质测试等方法,保障生成代码的质量。
8. CodeRAG Integration System:面向代码的 RAG 检索增强
- 将语义向量检索与依赖图分析结合,理解大规模代码库的结构关系。
- 自动发现合适的开源库、可复用模式及相关代码片段,使生成的代码更贴合工程生态。
9. Multi-Interface Framework:Web + CLI + REST API 一体化
- 提供 RESTful API,便于集成到现有系统或 CI/CD 流水线。
- 内置 CLI(面向自动化)和 Web 界面(面向非工程角色),支持实时代码流式输出与交互调试。
10. Smart Document Segmentation(v1.2.0):大文档智能切分
- 针对超出 LLM Token 限制的大型文档,根据内容结构与语义自动分段,保留关键引用关系。
- 小文档则使用传统处理路径,实现兼容与性能的平衡。
技术架构
整体架构流程图

多智能体角色分工(部分)
| Agent 名 |
主要职责 |
| Central Orchestrating Agent |
统筹整个工作流、分配任务 |
| Intent Understanding Agent |
深度语义分析,提取功能需求与技术约束 |
| Document Parsing Agent |
解析复杂技术文档和论文,提取实现规范 |
| Code Planning Agent |
进行架构设计、技术栈优化与模块化设计 |
| Code Generation Agent |
综合信息生成可执行代码、测试与文档 |
MCP 工具矩阵
DeepCode 基于 Model Context Protocol (MCP) 标准,将外部工具统一管理,形成了一个高度自动化的“工具宇宙”,包括:
- brave / bocha-mcp:搜索引擎,用于实时信息检索。
- filesystem / fetch:本地文件系统管理与网页内容抓取。
- github-downloader:克隆并下载 GitHub 仓库供分析。
- code-implementation:核心的代码实现工具。
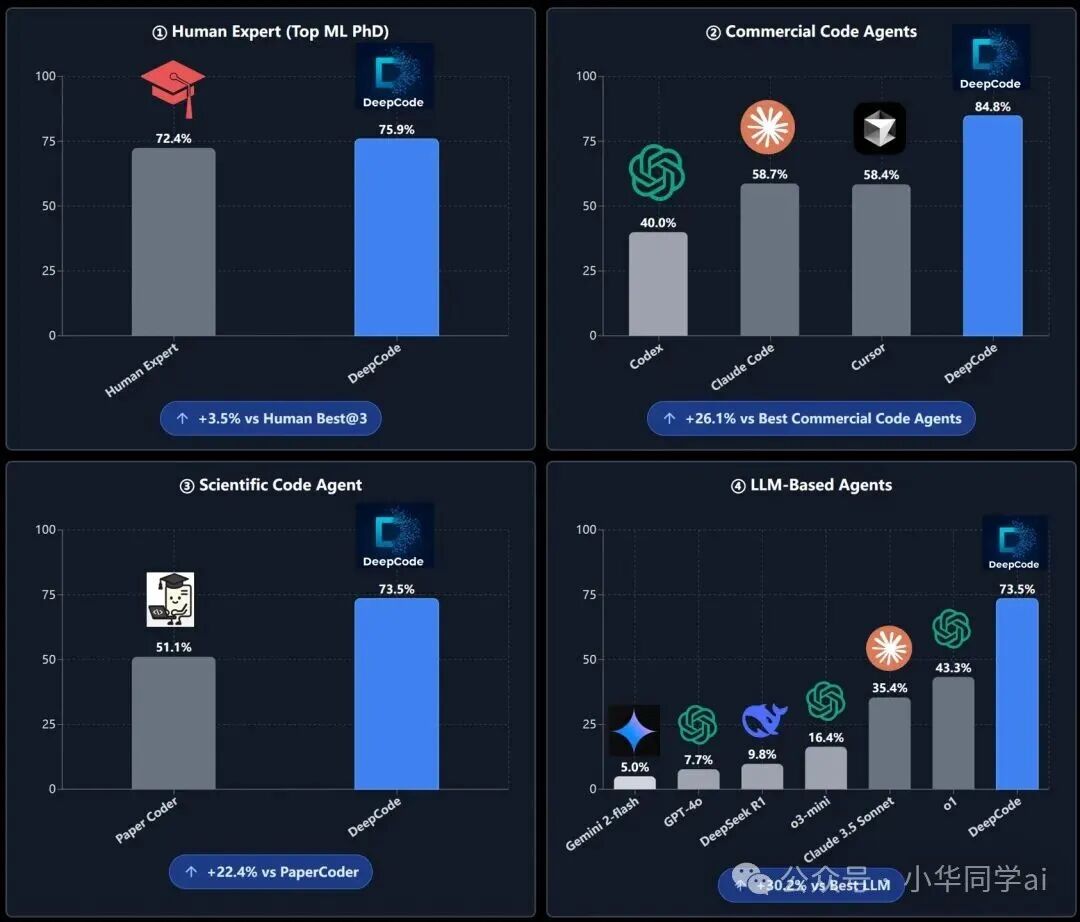
性能对比
DeepCode 在 OpenAI PaperBench 上的测试结果表现优异:
- 对比人类专家:在论文复现任务上达到 75.9% 的完成度,优于顶级 ML PhD 的 72.4%。
- 对比商业代码代理:在5篇论文子集上达到 84.8%,显著高于 Cursor、Claude Code 等工具。
- 对比科学代码代理:以 73.5% 优于专注论文复现的 PaperCoder (51.1%)。
- 对比通用 LLM Agent 方案:大幅领先于 Claude 3.5 Sonnet 或 o1 模型搭配基础Agent的方案。
其优势主要源于多智能体架构、CodeRAG检索与完整工程流水线的协同,而非单纯依赖更大的底层模型。
快速上手
步骤一:安装与配置
- 安装包:
pip install deepcode-hku
- 下载配置文件并配置 API Key(OpenAI/Anthropic/Google 等):
curl -O https://raw.githubusercontent.com/HKUDS/DeepCode/main/mcp_agent.config.yaml
curl -O https://raw.githubusercontent.com/HKUDS/DeepCode/main/mcp_agent.secrets.yaml
# 编辑 mcp_agent.secrets.yaml 填入您的 API Key
步骤二:启动应用
步骤三:生成代码
- Input:在Web界面或CLI中,上传论文PDF、输入自然语言需求或粘贴URL。
- Processing:系统自动解析文档、规划项目、检索代码并生成实现。
- Output:获得包含完整代码、测试和文档的可部署工程结构。
应用场景
- 学术论文快速复现:上传顶会论文PDF,获取可直接运行和调优的算法初版实现。
- 算法工程化落地:将研究人员的公式和伪代码,自动转换为模块化、可测试的生产级代码。
- 快速原型搭建:产品人员用自然语言描述需求,自动生成前端页面或后端API原型,工程师进行深度优化。
- 文档驱动开发:直接解析第三方API或技术文档,生成对应的调用代码和封装层。
- 教学与学习:学生可将算法描述与DeepCode生成的结果对比,深入理解实现细节与工程实践。
总结
DeepCode 通过 多智能体协作、CodeRAG检索增强 与 MCP工具矩阵,构建了一条从文档到产出的自动化流水线。它不仅在论文复现任务上媲美甚至超越人类专家和商业工具,更能覆盖前端、后端全栈代码的自动生成,为研究人员、工程师及学习者提供了一个强大的效率工具,将开发者从重复的样板代码中解放出来,聚焦于更具创造性的核心工作。
项目地址
https://github.com/HKUDS/DeepCode
|  发表于 2025-12-14 21:42:54
|
查看: 296|
回复: 0
发表于 2025-12-14 21:42:54
|
查看: 296|
回复: 0
