百万级别Token的输入是当前大型语言模型(LLMs)处理长上下文任务时面临的计算与内存瓶颈。近期,基于“上下文光学压缩”思路的DeepSeekOCR实现了10倍的Token压缩,但其高压缩率的本质真的在于“图像化”吗?
研究分析表明,高压缩率的核心其实源自Latent Tokens(潜在Token)本身——这是一种比离散文本Token信息密度更高、更高效的信息载体。基于这一洞察,研究团队提出了一种更为本质和直接的解决方案:ContextCascade Compression (C3,上下文级联压缩)。
核心路径对比
- DeepSeek OCR 路径: 文本 → 图像 → 视觉 Token → 语言模型(引入了布局、噪点、视觉编码器等无关干扰)
- C3 路径: 文本 → 文本 Latent Tokens → 语言模型(路径纯粹、可实现无损压缩)
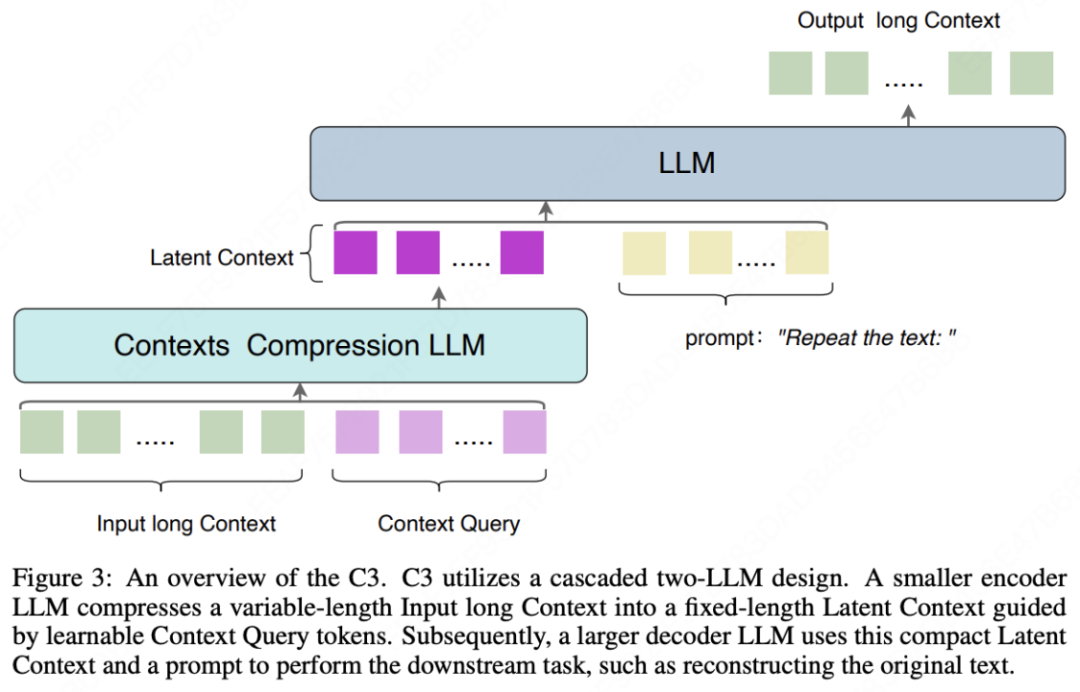
C3的核心设计是:使用一个小型LLM作为第一级压缩器,将长上下文压缩为一组固定长度的潜在token(例如32或64个),实现高比例的文本到潜在表示的压缩。随后,一个大型LLM作为第二级解码器,基于这个压缩后的上下文表示来执行实际的下游任务。这一设计也印证了近期关于「LLM本质是无损压缩器」的学术论断。
实验数据显示,在20倍压缩比下,C3的解码准确率高达98%,而对比方法的准确率约为60%。即使将压缩比提升至40倍,C3的准确率仍能保持在93%左右,展现了其在上下文压缩领域的优越性能和可行性。
模型已开源

架构解析
在深入C3之前,有必要了解DeepSeek-OCR的“视觉压缩”思路。该方法利用视觉编码器进行特征提取,但也不可避免地受限于图像布局复杂性和分辨率等问题。C3则提出了更直接的文本域压缩方案,其核心架构包括:
-
双LLM级联设计
- 小型LLM:作为压缩编码器,负责高效压缩上下文信息,算力消耗低。
- 大型LLM:作为解码器,利用其强大的推理生成能力执行最终任务。
-
压缩机制
- 引入可学习的“上下文查询”嵌入。
- 将任意长度文本压缩为固定长度的潜在token序列。
- 完全保留并利用预训练LLM内在的语言压缩能力。

性能表现
在基准测试中,C3展现出显著优势:
- 在约20倍压缩时,C3保持98.4%的精度,而对比方法降至59.1%。
- 即使在40倍的极限压缩率下(仅用32个潜在token表示),C3的重建精度仍能维持在93%以上。
独特的“渐进式遗忘”模式
研究发现C3有一个有趣特性:当压缩率过高导致信息损失时,错误并非均匀分布,而是集中在文本的末尾部分,呈现出序列性的信息衰减。这与光学压缩方法导致的“全局模糊化”不同,反而更接近人类记忆的渐进式遗忘过程。
这一特性使C3在实际应用中更具可预测性和可控性——用户可以将关键信息优先放置在文本前部,以确保其被完整保留。

测试效果
无论是在长英文文本还是复杂的中文古文上,C3均能实现近乎完美的压缩与还原。甚至对于LLM传统上难以处理的乱序文本,C3也能进行精准重建。

应用前景
- 超长上下文处理:C3可作为现有LLM的“前端压缩器”,将百万级Token的输入(如整本书籍、大型代码库)压缩至可管理的范围,大幅降低计算成本与内存开销。
- 多模态扩展:可级联轻量级视觉语言模型与LLM,由VLM充当视觉信息压缩器,用于处理富含视觉信息的长文档等场景。
- 下一代模型基础组件:C3的编码-解码架构可直接应用于扩散语言模型或潜在自回归模型,作为将可变长文本转换为固定长度潜在表示的基础模块。
C3是一个在有限资源下诞生的“小而美”的研究项目。目前其代码与模型权重均已开源,期待开源社区能够进一步探索和释放其潜在价值。 |  发表于 2025-12-14 22:03:00
|
查看: 310|
回复: 0
发表于 2025-12-14 22:03:00
|
查看: 310|
回复: 0
