在大型语言模型推理服务走向实际应用的过程中,推理框架的核心价值已不仅仅是“能运行”,更在于如何在算力、吞吐和延迟之间找到最佳平衡点。SGLang 作为备受关注的开源推理框架,不仅兼顾了交互式与批量处理,其调度器(Scheduler)的设计更是实现高性能的关键。
本文将结合源码,深入剖析 SGLang 调度器的工作流程、批处理策略及资源调度逻辑,为开发者优化实际应用提供参考。
什么是Scheduler?
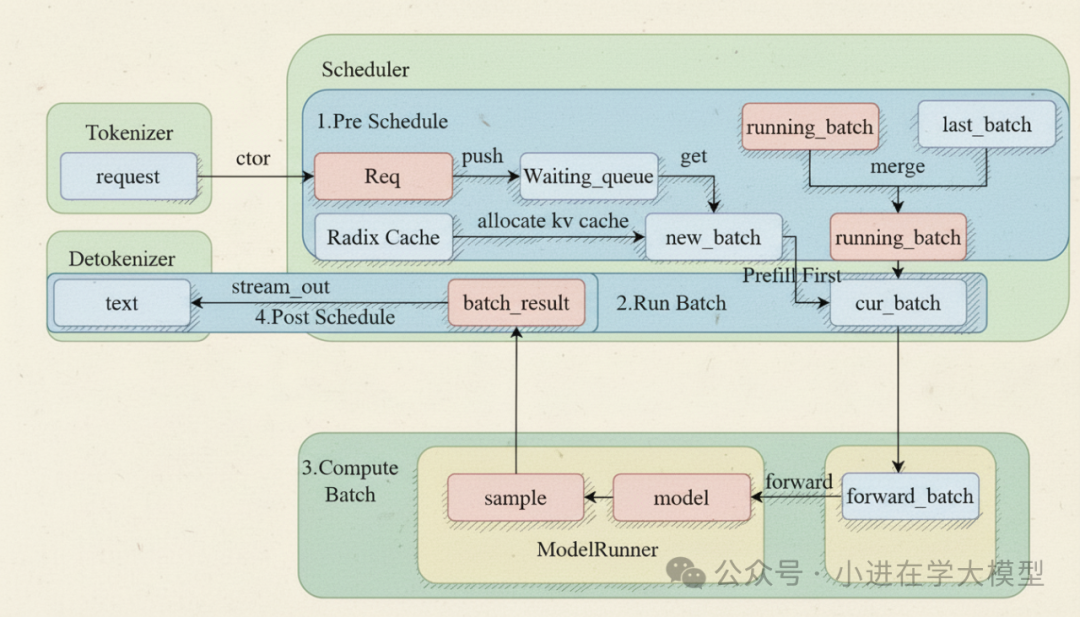
Scheduler 是 SGLang 框架的核心调度器,扮演着整个高性能 LLM 推理引擎的“大脑”角色。它负责管理和调度所有进入系统的请求,以最高效的方式利用 GPU 资源。
可以将其比喻为一个繁忙机场的空中交通管制塔台:需要决定哪些“飞机”(请求)可以“起飞”(进入预填充/Prefill阶段),哪些可以“着陆”(生成下一个token/Decode阶段),同时确保“跑道”(GPU)始终被高效利用。
核心功能和目标
该调度器旨在实现一个高性能的LLM推理后端系统,主要目标包括:
- 高吞吐量:通过连续批处理等技术,最大化单位时间内处理的token数量。
- 低延迟:尽快响应用户请求,尤其优化流式输出场景。
- 高资源利用率:确保GPU尽可能处于满负荷工作状态,减少空闲。
- 灵活性与可扩展性:支持多种并行策略(TP, PP, DP)、模型架构及高级功能(如投机解码、LoRA)。
关键组件与设计模式
调度器由多个协同工作的组件构成:
- Scheduler 类:核心控制器,管理状态(等待队列、运行批次等)并运行主事件循环。
- 请求分发器 (_request_dispatcher):采用基于类型的分发器设计模式,根据请求类型调用相应处理函数,结构清晰易于扩展。
- TpModelWorker / TpModelWorkerClient:实际的GPU执行单元。
TpModelWorkerClient支持CPU/GPU计算重叠,是高性能流水线的关键。
- KV缓存管理器 (RadixCache, HiRadixCache):性能优化的基石。通过前缀树(Trie)实现请求间的KV缓存前缀共享,大幅节省计算与显存。
HiRadixCache进一步支持将不常用缓存转移至CPU内存。
- 调度策略 (SchedulePolicy):将调度决策逻辑(如类SRTF策略)分离,便于更换算法。
- 调度批次 (ScheduleBatch):一个数据类,封装了将被GPU处理的一批请求及其所有元数据。
核心工作流程:事件循环
脚本定义了三种事件循环以适应不同策略:
event_loop_normal():简单的串行循环,适用于不支持计算重叠的简单场景。event_loop_overlap() (默认):高性能关键模式。实现经典流水线以重叠CPU处理与GPU计算,有效隐藏延迟,让GPU持续工作。这种优化对于构建高并发的后端系统至关重要。event_loop_pp():专为流水线并行设计,管理微批次在不同PP阶段的GPU间流动。
关键技术与高级特性
调度器集成了多种LLM推理前沿技术:
- 连续批处理与Prefill-Decode分离:动态混合新Prefill请求与正在Decode的请求,避免传统批处理因请求长度不一造成的GPU空闲。
- 分块预填充:将长提示分块处理,穿插执行其他请求的Decode,提高系统响应公平性。
- 投机性解码:使用小“草稿模型”生成多个候选词元,再由大模型一次性验证,加速Decode阶段。
- 计算资源解耦:允许将计算密集的Prefill和访存密集的Decode部署在不同特性的GPU集群上,实现极致成本效益。
- 约束生成:通过
grammar_backend支持JSON Schema等语法约束,确保输出格式合规。
- 动态LoRA与在线权重更新:支持运行时动态加载/卸载LoRA适配器及更新模型权重,适用于多租户和持续学习场景。
- 强大监控:包含看门狗线程、内置性能分析支持以及详细日志指标收集。
Scheduler初始化详解
下面分模块解析其初始化步骤:
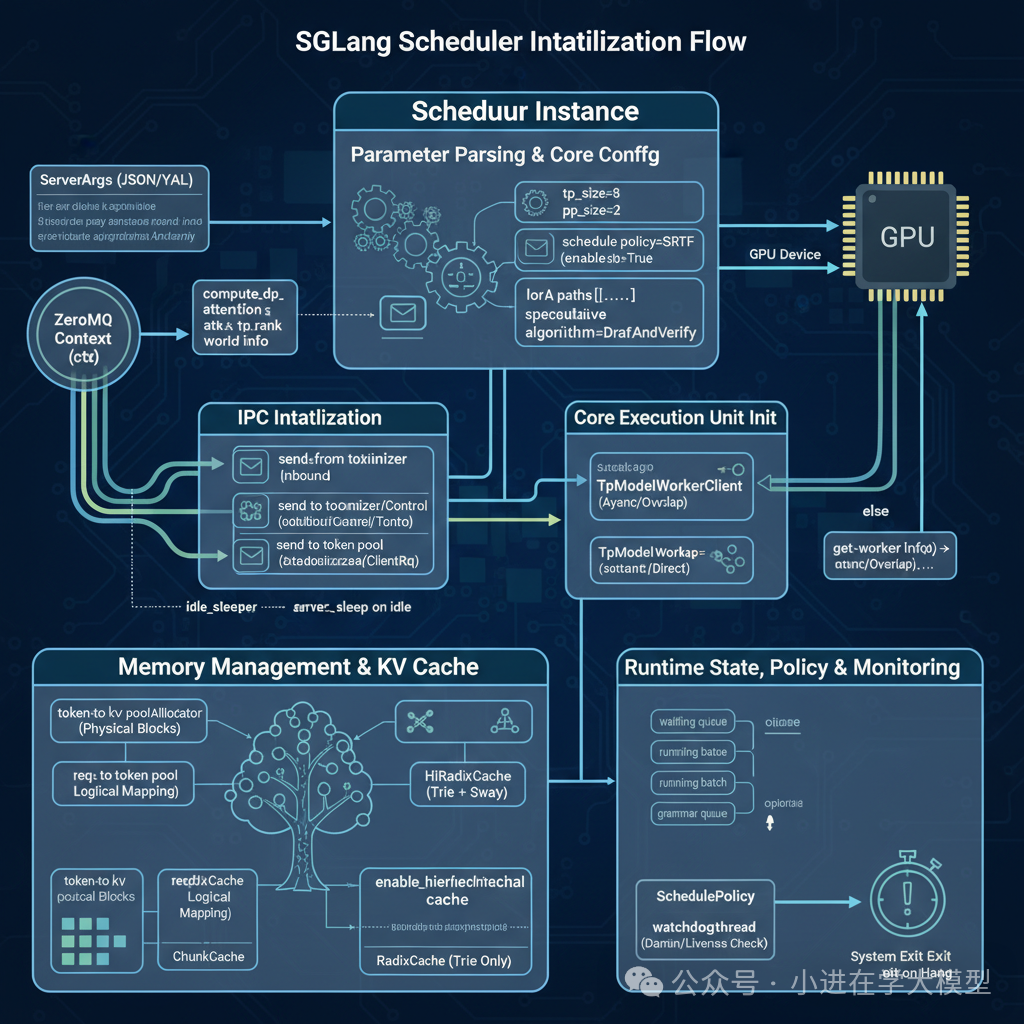
1. 参数解析与核心配置
初始化过程将ServerArgs中的配置持久化为实例属性,包括并行规模(TP/PP/DP)、调度策略、是否启用重叠计算等。其中compute_dp_attention_world_info函数体现了系统对复杂并行方案(如DP-Attention)的适应性。
2. 进程间通信初始化
使用ZeroMQ建立与TokenizerManager、DetokenizerManager等管理进程的通信管道。仅特定进程(pp_rank=0, attn_tp_rank=0)负责外部通信,避免了竞争。
3. 核心执行单元初始化
根据enable_overlap配置选择TpModelWorker或TpModelWorkerClient。后者是实现计算重叠的关键。通过tp_worker.get_worker_info()同步获取GPU显存限制等权威信息,是正确调度的前提。
4. 内存管理与KV缓存
调用init_memory_pool_and_cache建立高效的KV缓存管理系统,这是SGLang性能的基石:
token_to_kv_pool_allocator:管理物理KV缓存块的分配。req_to_token_pool:管理请求到物理块的逻辑映射。tree_cache (核心特性):
RadixCache:使用基数树组织缓存,实现请求间相同前缀的KV缓存复用。HiRadixCache:支持将“冷”数据交换到CPU内存的分层缓存。
5. 运行时状态、策略与监控
初始化动态数据结构与辅助工具:
- 状态队列:
waiting_queue、running_batch、grammar_queue是连续批处理算法的核心。
- SchedulePolicy:将调度逻辑从主循环解耦。
- watchdog_thread:启动后台看门狗线程,监控系统是否卡死,提升生产环境健壮性。
事件循环:系统的“心跳”
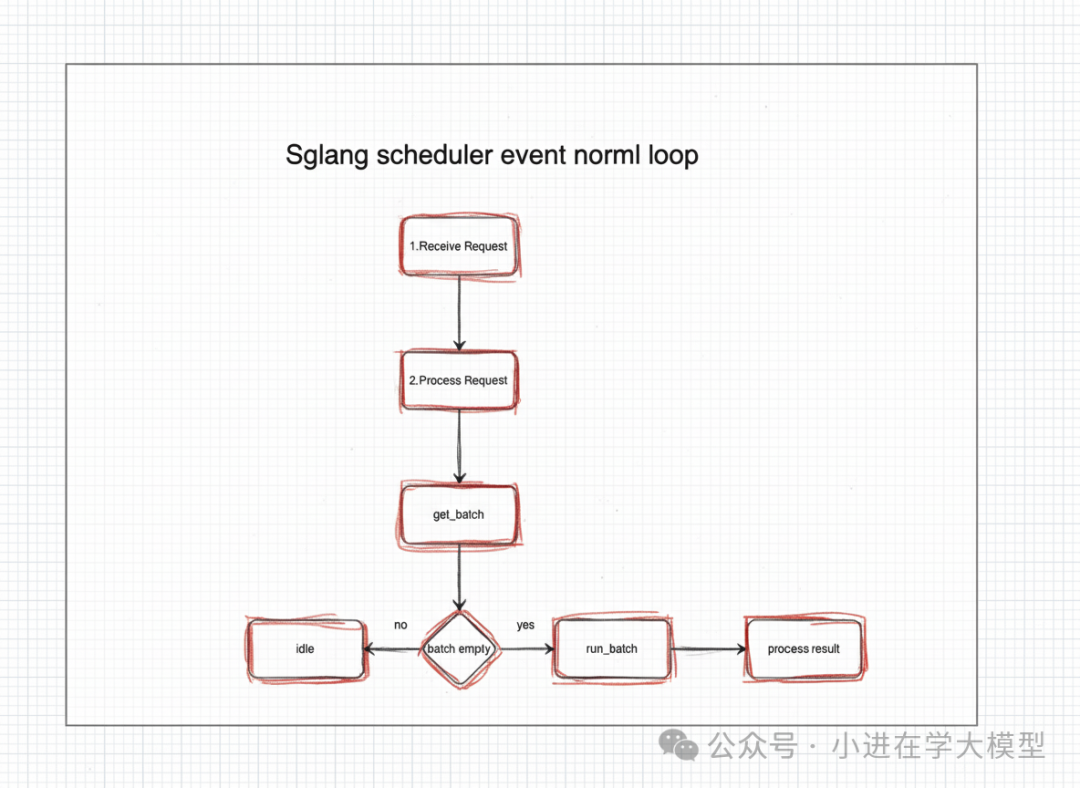
以event_loop_normal为例,其核心逻辑如下:
def event_loop_normal(self):
while True:
# 1. 接收请求
recv_reqs = self.recv_requests()
# 2. 处理输入请求
self.process_input_requests(recv_reqs)
# 3. 决定下一批要运行的请求
batch = self.get_next_batch_to_run()
self.cur_batch = batch
if batch:
# 4. 运行这批请求(模型生成)
result = self.run_batch(batch)
# 5. 处理生成结果
self.process_batch_result(batch, result)
else:
# 服务器空闲时的操作
self.maybe_sleep_on_idle()
self.last_batch = batch
流程简述:
- 接收与处理请求:通过ZMQ接收请求,并由
_request_dispatcher按类型分发处理。
- 调度决策:
get_next_batch_to_run是调度算法的“大脑”,决定下一个运行批次。
- 模型生成:
run_batch将任务委托给tp_worker在GPU上执行前向传播。
- 结果处理:更新请求状态、处理流式输出、释放已完成请求的资源。
recv_requests 函数分析
该函数是调度器与外界及内部分布式进程沟通的桥梁,核心是接收请求并在并行进程间同步状态。
它通过分层逻辑处理复杂并行模式:
- 分层接收:根据
pp_rank判断从外部接收还是从上一个流水线阶段接收。
- 指定领导者:仅
attn_tp_rank=0的进程执行实际I/O。
- 条件广播:根据是否启用
DP-Attention及TP size,选择合适的策略将请求同步给所有需要的伙伴进程。
get_next_batch_to_run:调度决策核心
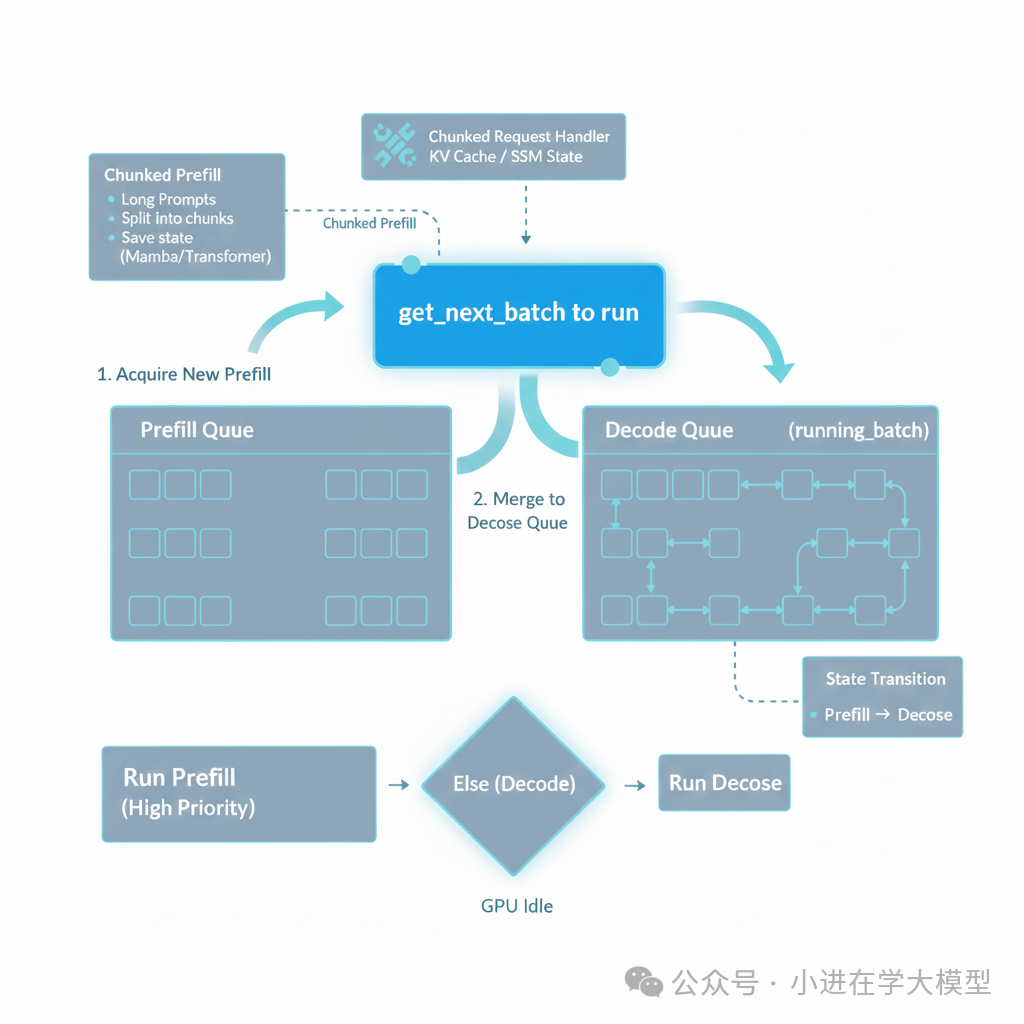
此函数遵循“Prefill优先”策略,决定下一个推理步执行什么,是连续批处理的核心。
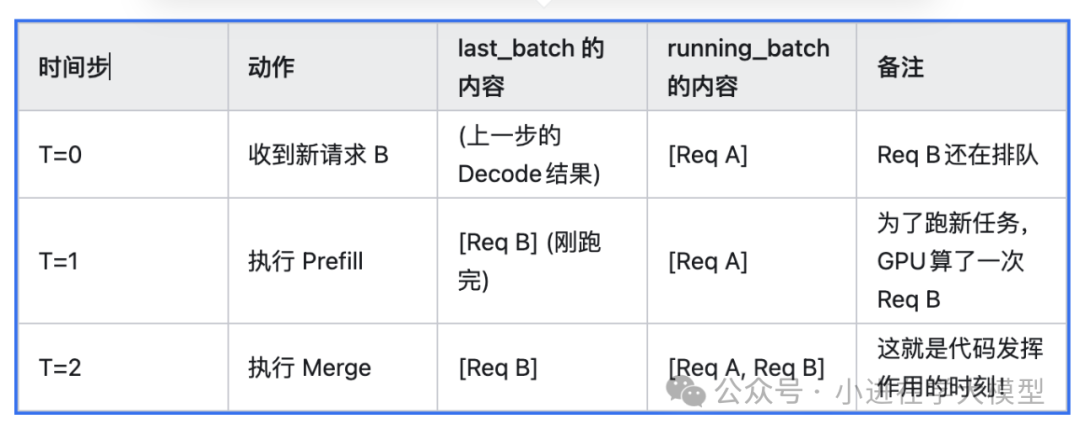
整体流程与last_batch的作用
last_batch特指上一个时间步刚刚跑完Prefill的请求批次。其生命周期示例如下:
- T=0:新请求
Req B到达,进入wait_queue。running_batch中有正在解码的Req A。
- T=1:调度器决定先执行
Req B的Prefill。执行后,包含Req B的批次被赋给self.last_batch。
- T=2:在
get_next_batch_to_run中,将last_batch(Req B)合并到running_batch(Req A)中。
- 后续:GPU同时为
Req A生成下一个token,并为Req B生成第一个token。
last_batch.is_empty()为True的情况,通常意味着上一轮Prefill的请求全部没有资格进入Decode,例如:
- 分块预填充被移出:长提示被分块,当前块完成后需等待下一块,不能立即解码。
- 请求被取消:用户断开连接,请求被标记为
FINISHED_ABORT并在过滤时移除。
merge_batch的作用
merge_batch实现了连续批处理的关键步骤:将刚完成Prefill的新请求合并到正在解码的队列中。
get_new_batch_prefill:筛选与准入控制
该函数负责从waiting_queue筛选请求加入Prefill批次,设立多重检查关卡:
- LoRA资源限制:检查候选请求的LoRA适配器总数是否超标。
- 并发数量限制:检查是否超过系统最大并发处理能力。
- 满员与抢占:若批次已满,则根据配置决定是否用高优先级请求进行抢占。
- 内存分配尝试:通过
adder.add_one_req模拟添加,检查Token数量与显存(KV Cache)是否充足。
决策流:依次检查LoRA兼容性、并发槽位、缓存数据准备情况,最后进行实质的显存/Token配额检查。任何一环不通过则停止添加。
通过上述精细的调度机制,SGLang能够高效管理GPU资源,显著提升作为LLM推理框架的吞吐量与响应速度,为复杂场景下的模型部署提供了强大的底层支持。
 发表于 2025-12-15 02:26:57
|
查看: 261|
回复: 0
发表于 2025-12-15 02:26:57
|
查看: 261|
回复: 0
