在开发集成语音功能的应用时,无论是构建虚拟助手、提升无障碍访问体验,还是为多媒体内容配音,文本转语音(TTS)技术都是关键组件。对于希望拥有更高定制性和控制权的开发者而言,开源TTS引擎提供了极具吸引力的选择。本文将对当前主流的7款开源TTS引擎进行深度剖析与横向对比,并探讨其核心应用场景与集成挑战,助您为项目选出最佳方案。
文本转语音(TTS)引擎的工作原理
文本转语音引擎本质上是一种将书面文字转换为可听语音的软件系统。其核心流程通常包含两步:首先,引擎利用自然语言处理技术对输入文本进行语言学分析,理解词汇、语法乃至语义;随后,语音合成器根据分析结果生成具有特定音色、语调和节奏的语音波形。这项技术是虚拟助手、导航系统、屏幕阅读器等众多应用得以实现的基础。
7款主流开源TTS引擎详解
1. MaryTTS(多模态交互架构)
MaryTTS采用高度模块化的设计,允许开发者自由组合或替换各个处理环节,从而构建定制化的TTS系统。其架构核心包含以下组件:
- 标记语言解析器:负责解读输入文本的格式与结构。
- 处理器:执行文本标准化、音素转换等中间处理任务。
- 合成器:最终生成语音波形,并可添加韵律特征使语音更自然。
架构概览:
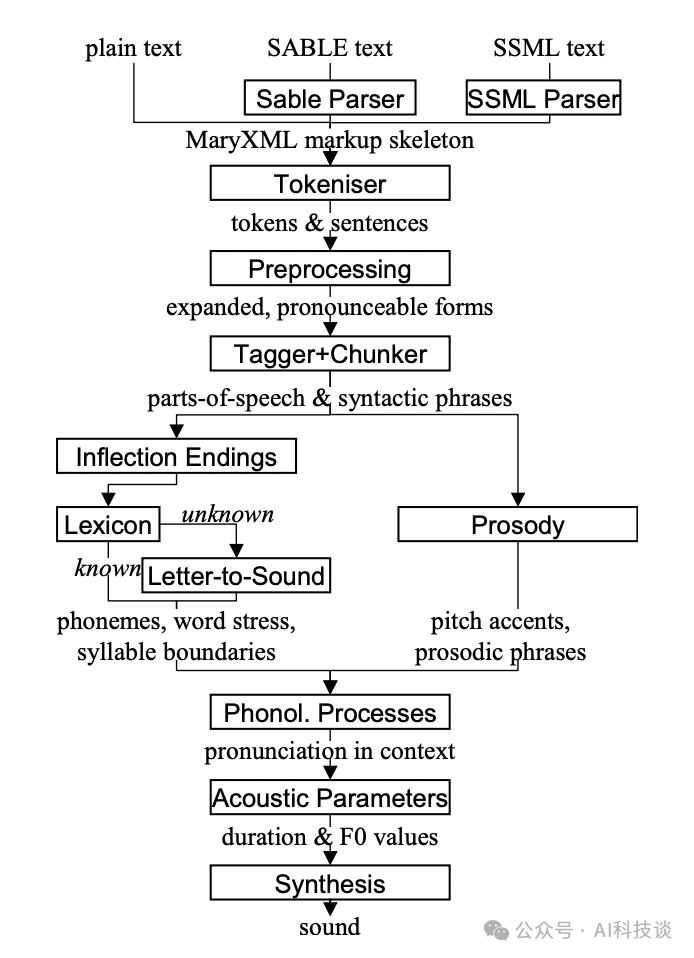
来源:MaryTTS GitHub
优点:灵活性极高,支持深度定制,便于集成到各类平台。
缺点:需要对TTS技术栈有较深理解,存在一定的学习曲线。
2. eSpeak
eSpeak以其小巧的体积和跨平台兼容性(支持Windows、Linux、macOS、Android)著称。它采用共振峰合成技术,能生成清晰但略带机械感的语音,支持多种语言。

优点:资源占用低,语言支持广泛,易于集成。
缺点:语音自然度有限,定制选项较少。
3. Festival语音合成系统
由爱丁堡大学开发,Festival提供了一个用于构建TTS系统的通用框架和丰富的示例模块,在学术界和研究领域被广泛使用。
话语结构示意图:
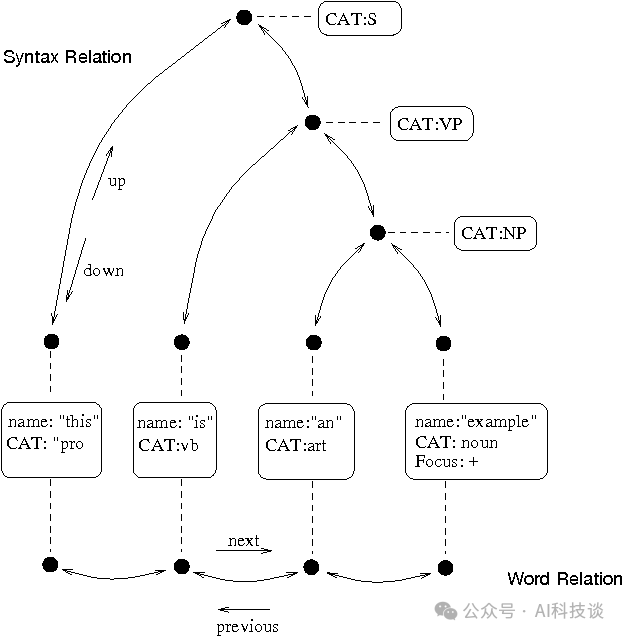
来源:Festival官方文档
优点:可定制性极强,非常适合用于语音合成的算法研究与教学。
缺点:对初学者不友好,需要一定的编程与语言学知识。
4. Mimic(由Mycroft AI开发)
Mimic系列包含两个版本:基于传统Festival系统的Mimic 1,以及采用深度神经网络、能产生更自然语音的Mimic 2。
来源:Mycroft AI
优点:兼顾传统与前沿方法,语音质量较高,支持多语言。
缺点:项目文档相对有限。
5. Mozilla TTS
这是一个基于深度学习的现代TTS引擎,采用如Tacotron、WaveNet等先进的序列到序列模型,致力于生成高度自然、接近人声的语音。
优点:利用了前沿的深度学习技术,语音合成效果出色,完全开源免费。
缺点:对训练数据依赖较强,预训练模型支持的语言相对有限。
6. Tacotron 2(NVIDIA)
Tacotron 2是一个具有影响力的神经网络模型架构,而非完整的引擎。但其开源实现为许多后续的TTS项目奠定了技术基础。它可以直接从文本生成高质量的梅尔频谱图,再转换为语音。
优点:代表了基于神经网络的语音合成的先进水平,生成的语音非常自然。
缺点:直接使用和训练模型需要较强的机器学习背景与算力支持。
7. ESPnet-TTS
作为ESPnet端到端语音处理工具包的一部分,ESPnet-TTS集成了最新的深度学习模型,同时支持语音识别与语音合成任务。
优点:设计现代,支持多种最先进的模型架构,社区活跃。
缺点:同样需要一定的技术背景进行部署与调试。
引擎横向对比与选型参考
| 引擎 |
核心技术/架构 |
核心优点 |
主要缺点 |
典型应用场景 |
| MaryTTS |
模块化架构,组件可定制 |
灵活性高,集成能力强 |
开发者学习曲线陡 |
定制化TTS系统研发、教育及辅助技术项目 |
| eSpeak |
紧凑型共振峰合成器 |
轻量、多语言、跨平台 |
语音自然度一般,功能有限 |
嵌入式系统、辅助技术、需要低资源占用的应用 |
| Festival |
通用框架与模块化设计 |
高度可定制,适合研究 |
使用复杂,需编码知识 |
学术研究、语音合成算法实验 |
| Mimic |
传统合成与神经网络结合 |
语音自然,支持多语言 |
文档支持较少 |
虚拟助手、多媒体应用等需要较好音质的场景 |
| Mozilla TTS |
深度学习序列到序列模型 |
语音自然度高,技术先进 |
预训练模型语言支持有限 |
追求高质量语音的开源项目与产品 |
| Tacotron 2 |
神经网络声学模型 |
语音生成质量顶尖 |
实施与训练门槛高 |
前沿语音合成研究与开发 |
| ESPnet-TTS |
端到端深度学习 |
模型新颖,灵活,多语言 |
需要技术专长实施 |
高级语音处理项目,尤其是多语言场景 |
TTS引擎的核心应用场景
- 虚拟助手与无障碍应用:为核心交互提供语音输出,并为视障用户朗读屏幕文本。
- 自动语音应答(IVR)与聊天机器人:使自动电话系统或聊天机器人的回复更具人性化。
- 多媒体内容配音:自动化地为视频教程、电子学习课件或营销视频生成画外音,尤其适用于多语言内容本地化。
使用开源TTS引擎面临的挑战
- 语言与音质限制:多数开源引擎在小众语言支持或语音自然度上可能不及成熟的商业方案。
- 集成与定制成本:需要投入开发资源进行集成、调试和可能的二次开发,总体拥有成本需综合评估。
- 技术支持与文档:社区驱动项目的文档质量和问题响应速度可能参差不齐。
- 性能与安全:需自行评估和优化引擎的性能,并对代码安全性保持关注。
如何为你的项目选择TTS引擎?
- 明确需求:首先确定应用场景对语音质量、实时性、语言种类的具体要求。
- 评估技术能力:权衡团队在Python、机器学习或语音技术方面的技能,选择与之匹配的引擎。
- 考量资源与成本:除了软件免费,还需计算集成开发、模型训练(如需要)和维护的投入。
- 进行原型测试:对于候选引擎,务必制作原型进行实际语音输出效果和系统集成的测试。
- 检查社区生态:活跃的社区意味着更好的问题解答、持续的更新和更丰富的预训练模型。
总结
开源TTS引擎为开发者提供了强大的工具和极大的灵活性,从经典的合成算法到前沿的深度学习模型,选择丰富。成功的关键在于透彻理解自身项目需求与技术约束,并在灵活性、开发成本与最终语音效果之间找到最佳平衡点。希望本文的对比与分析能为您在技术选型时提供清晰的指引。 |  发表于 2025-12-15 12:55:54
|
查看: 211|
回复: 0
发表于 2025-12-15 12:55:54
|
查看: 211|
回复: 0
