在大规模AI模型训练中,单机单GPU的方案已无法满足巨量模型对算力与内存的需求。随着模型参数持续攀升,分布式训练成为技术发展的必然方向,而支撑其高效运行的核心基础,正是分布式训练通信原语。
本文将详细阐释这些通信原语的定义,梳理主流通信模式,并结合实例帮助读者理解其在大模型训练中的关键作用与优化价值。
扩展阅读:解构大模型训练软件栈:分层架构、核心组件与协同机制
什么是分布式训练通信原语?
“通信原语”并非特指某一款框架或接口,而是各类分布式系统中一组高度抽象、可复用的基础通信与协同操作集合。它定义了训练过程中,多设备、多进程之间如何实现数据交互、状态同步与一致性维护。
无论你采用PyTorch、TensorFlow还是JAX框架,也无论部署数据并行、模型并行还是混合并行策略,其底层实现都依赖于这些通信原语的高效执行。简言之,通信原语的性能直接决定了分布式训练效率的上限。
主流分布式训练通信原语详解
基于实际训练中最常见的通信模式,我们归纳出八大核心通信原语,分别是:Broadcast(广播)、Scatter(散射)、Gather(汇聚)、AllGather(全汇聚)、Reduce(归约)、ReduceScatter(归约散射)、AllReduce(全归约)以及All-to-All(全交换)。
1. Broadcast(广播)
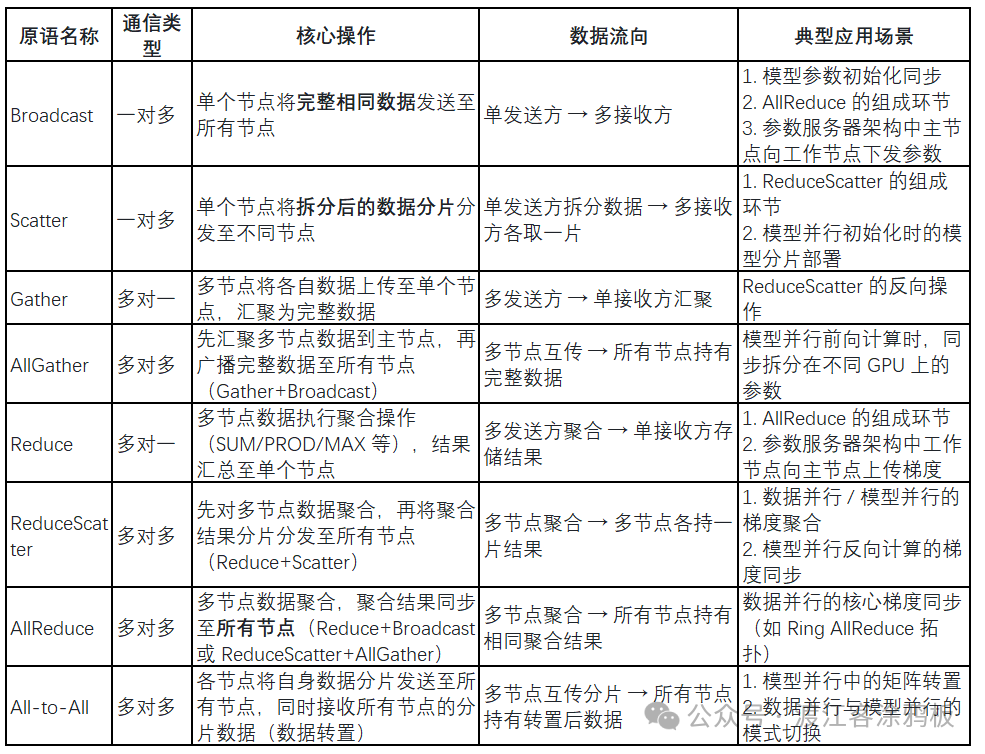
广播是一种一对多的通信原语,即由单个发送方向多个接收方传输相同的数据。在集群中,一个节点(或GPU)会将自身数据同步至其他所有节点。
例如,将GPU0的数据A同步到GPU1、GPU2与GPU3。
广播的典型应用场景包括:
- 并行训练的参数初始化:确保所有GPU的初始参数完全一致。
- 作为AllReduce操作的组成环节:在“Reduce+Broadcast”实现方式中。
- 参数服务器架构:主节点通过Broadcast向工作节点下发参数。
2. Scatter(散射)
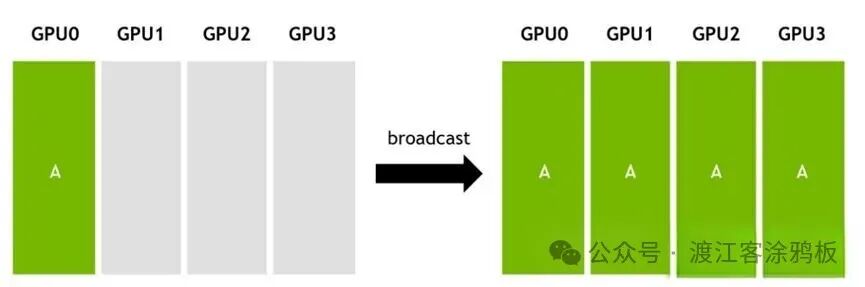
Scatter同样属于一对多通信,但它与Broadcast有本质区别:
- Broadcast:向所有节点发送完整的相同数据。
- Scatter:将数据拆分成分片,并分发至不同节点,每个节点获得独一无二的一部分。
举个例子,将一份完整数据拆分为A、B、C、D四个分片,再分发:
DATA-A → GPU0
DATA-B → GPU1
DATA-C → GPU2
DATA-D → GPU3
Scatter的逆操作是Gather(汇聚),其典型应用场景包括:
- 作为ReduceScatter(归约散射)组合操作的核心环节。
- 模型并行初始化:将模型的不同层或张量分片部署到不同的GPU上。
3. Gather(汇聚)
Gather是一种多对一的通信原语,由多个数据发送方向单个接收方传输数据,实现集群内多节点数据向单一节点的归集。
所有节点将各自数据上传至主节点,例如:
GPU0 上传 DATA-A
GPU1 上传 DATA-B
GPU2 上传 DATA-C
GPU3 上传 DATA-D
最终,主节点会整合得到完整的 DATA-ABCD 数据集。Gather是Scatter的逆操作,主要作为ReduceScatter等组合操作的组成部分。
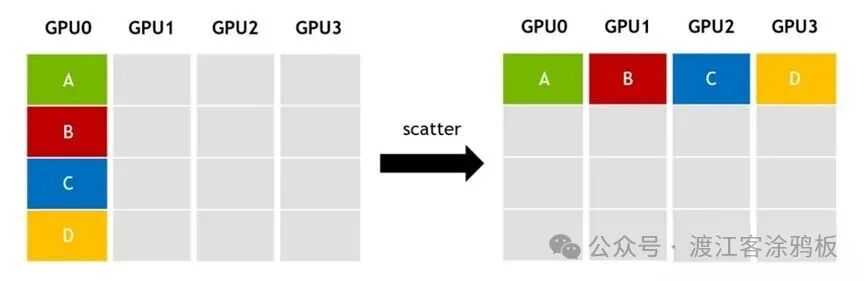
4. AllGather(全汇聚)
AllGather是一种多对多的通信原语,可实现多GPU间的同步式全量数据归集。该操作可看作“Gather + Broadcast”的组合流程:
- 先将所有节点的数据归集到主节点(Gather操作)。
- 再将整合后的完整数据同步至所有节点(Broadcast操作)。
最终结果是,集群内每一个节点都会持有完整的数据集。
AllGather的典型应用场景包括:
- 模型并行前向计算:需要先将拆分在不同GPU上的参数同步到单卡,才能开展计算。
5. Reduce(归约)
Reduce是一种多对一的通信原语,用于将多节点数据执行特定的归约运算后,将结果汇总至单个节点。
常见的归约运算类型包括:
- 求和(SUM)
- 求积(PROD)
- 求最大/最小值(MAX/MIN)
- 逻辑与/或(LAND/LOR)
- 按位与/或/异或(BAND/BOR/BXOR)
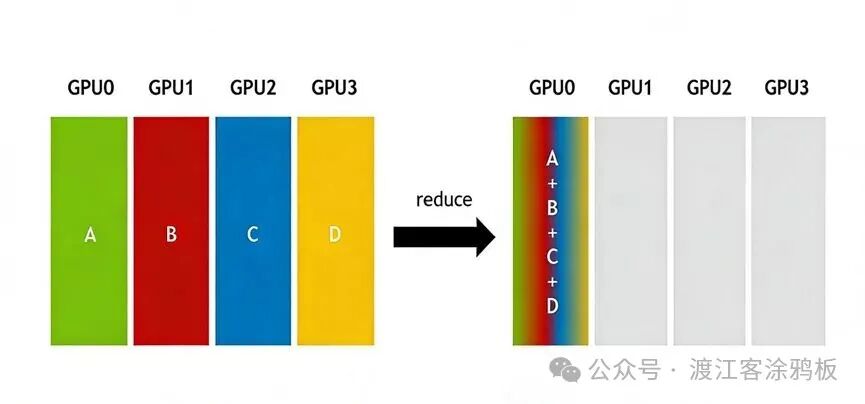
这些运算通常需要GPU或加速器硬件对相应算子提供支持,以实现高性能执行。其典型应用场景包括:
- 作为AllReduce(全归约)操作的核心环节。
- 参数服务器架构:工作节点通过Reduce操作将梯度聚合回传给主节点。
6. ReduceScatter(归约散射)
ReduceScatter是一种多对多的通信原语。在集群所有节点上,它会先对指定维度的数据执行归约(Reduce)运算,再将运算结果分片分发(Scatter)至各个节点。
从流程上看,它等价于“先Reduce,后Scatter”。
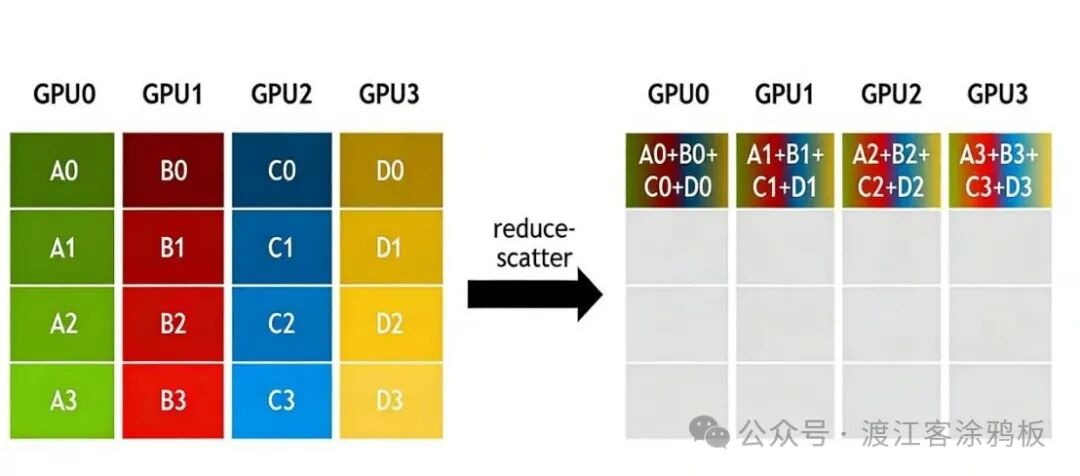
ReduceScatter是一种“先归约、后分发”的多对多数据操作,其典型应用场景包括:
- 同时适用于数据并行与模型并行训练。
- 数据并行中“ReduceScatter + AllGather”组合操作的核心环节。
- 模型并行反向计算中的梯度同步步骤。
7. AllReduce(全归约)
AllReduce是一种多对多的通信原语,也是深度学习分布式训练中最核心的操作之一。它会在集群所有节点上执行相同的归约运算,并将最终的运算结果同步至每一个节点。
AllReduce可以通过两种经典方式实现:
- 主节点模式:在主节点上执行“Reduce + Broadcast”。
- 无主节点模式:执行“ReduceScatter + AllGather”(例如Ring AllReduce拓扑)。
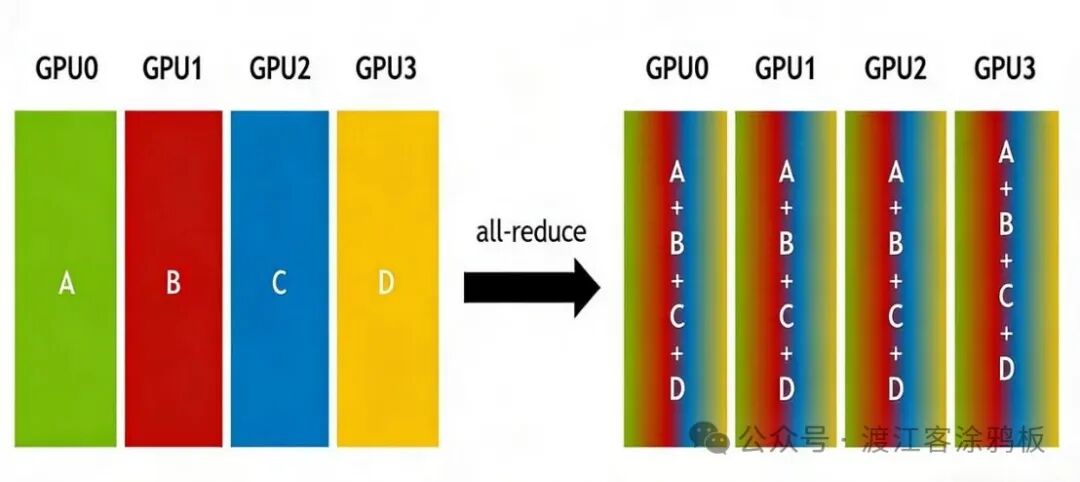
AllReduce的典型应用场景非常明确:
- 数据并行训练的核心:用于同步所有GPU计算出的梯度。
8. All-to-All(全交换)
在All-to-All操作中,每个节点会将自身数据分片发送至集群所有节点,同时接收来自所有其他节点的分片数据。All-to-All可看作是AllGather的拓展形式,二者核心区别在于:
- AllGather:不同节点从某一指定节点获取相同的数据。
- All-to-All:不同节点从某一指定节点获取不同的数据。本质上,这是一种数据转置操作。
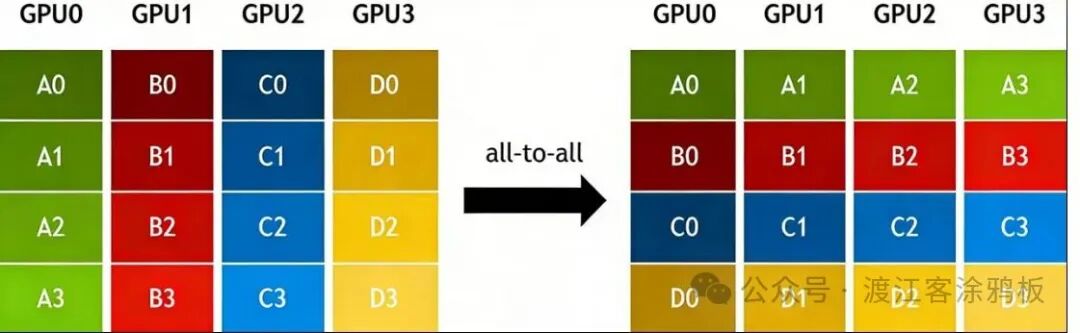
All-to-All的典型应用场景包括:
- 模型并行中的矩阵转置操作。
- 数据并行与模型并行模式切换过程中的数据重分布。
从通信原语到通信库:以NCCL为例
抽象的通信原语需要高性能的库来实现,NVIDIA集合通信库(NCCL)就是一个典型代表。NCCL是一款面向GPU间通信的优化库,具备拓扑感知能力,可便捷集成至各类应用中。
NCCL实现了前述的所有集合通信原语,包括AllReduce、Broadcast、Reduce、AllGather、ReduceScatter、AlltoAll等。此外,它还支持点对点收发通信,用以灵活构建Scatter、Gather等操作。
在传统CUDA编程中,集合通信可能需要组合多个内存拷贝与计算内核来实现。而NCCL将每一种集合通信原语封装为高度优化的独立内核,实现了通信与计算的一体化处理,从而达成更高效的同步并显著降低资源开销。
结束语
在分布式深度学习训练中,训练框架通常不会直接操控底层复杂的通信网络,而是借助像NCCL这样的高性能通信库来完成参数同步、梯度归约等关键操作。这些通信库能够有效屏蔽硬件细节,大幅提升训练效率。
实际部署中,网络互联模式多样(如InfiniBand、RoCE、NVLink),这就要求通信库必须与硬件厂商的SDK深度集成,并进行针对性优化。同时,还需根据实际的网络拓扑与集群布局,选择最适配的通信策略与算法。
理解这些基础的通信原语,是优化分布式训练性能、进行问题排查的起点。希望本文的梳理能帮助你构建起清晰的知识框架。对分布式训练、大模型技术栈等话题感兴趣的开发者,欢迎在云栈社区交流探讨。
参考资料:naddod.com
 发表于 2026-1-31 02:59:12
|
查看: 284|
回复: 0
发表于 2026-1-31 02:59:12
|
查看: 284|
回复: 0
