提到 GPU 深度学习加速,就绕不开 cuBLAS——NVIDIA 最重要的基础数学库,而其中的 GEMM(通用矩阵乘法)更是 AI 训练、推理的核心操作。很多人不知道,cuBLAS 内置了 5000 个 GEMM 核芯,还搭载了一套专属推荐系统,能在运行时自动选出最优核芯。这套选择逻辑,正是 NVIDIA GPU 性能强悍的关键秘密,也是众多开发者在云栈社区讨论高性能计算时的热点话题。
一、核芯选择的难题:组合爆炸式的配置空间
cuBLAS 要面对的核心问题,是组合爆炸。光看 cuBLASLt 的定义就足够惊人:
- 635 种分块(tile)尺寸
- 38 种流水线阶段配置
- 52 种集群形状
- 4 种归约方案
在此基础上,还要叠加数据类型(从 FP4 到 FP64 全覆盖)、矩阵存储布局(NN/NT/TN/TT 四种组合)、融合后处理操作(偏置加法、ReLU、GELU 等)。把这些参数自由组合后,单种 GPU 架构下,合法的核芯配置就达到数百万种。手动为每一种计算场景挑选最优核芯,根本不现实。
二、NVIDIA 的解法:训练专属推荐系统
面对海量配置,NVIDIA 没有采用穷举,而是打造了机器学习推荐模型:
- 采集不同精度、矩阵形状、存储布局、后处理方式下的核芯运行耗时数据;
- 训练模型,建立「计算场景特征→最优核芯」的映射关系;
- 运行时输入矩阵尺寸、流多处理器数量、共享内存、计算强度等参数,微秒级完成核芯调度。
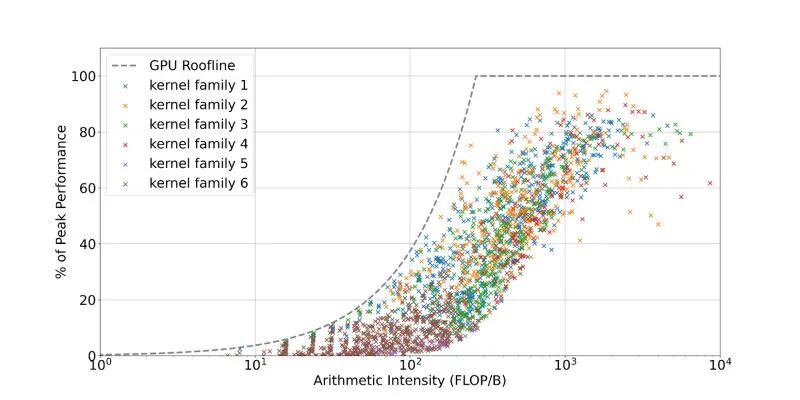
这套系统效果十分出色:在全场景下,推荐结果能达到理论峰值算力的 93%(几何平均),兼顾了速度与性能。
三、93% 的短板:长尾场景下的性能损耗
93% 的性能表现看似优秀,却在长尾特殊场景中暴露问题。vLLM 团队测试发现:在 H100 显卡上执行 272×4096 × 4096×14336 的 BF16 矩阵乘法时,cuBLAS 默认推荐的核芯,比最优方案慢了 43%。
解决方案是切换到 cuBLASLt:它不再只返回 1 个最优推荐,而是提供多达 100 个排序候选。同时 cuBLAS 与 cuBLASLt 的核芯库有重叠但不完全一致,最终 cuBLASLt 选出的最优核芯,比 cuBLAS 默认选择快了 26%,完美弥补了性能缺口。
四、底层支撑:nvMatmulHeuristics 解析模型
无论是 cuBLAS 还是 cuBLASLt,底层都依赖 nvMatmulHeuristics——NVIDIA 去年开源的核心工具,部分替代了机器学习方案,采用解析式性能模型:
无需机器学习训练,纯理论建模即可完成筛选。实测效果惊人:
Llama 3 405B 模型场景:从数千候选中筛选 16 个,150 分钟达到 96% 峰值算力(穷举需 700 + 分钟);
B200 显卡 + DeepSeek-R1 场景:直接逼近 99% 峰值算力。
五、核心结论:矩阵乘法没有唯一最优解
NVIDIA cuBLAS 预装了训练好的启发式推荐算法,但矩阵乘法的世界里,不存在唯一的“最佳答案”。谁能在运行时精准、快速地选出最快核芯,谁就能掌控所有 AI 框架的默认性能上限。这也是为什么如今大模型推理框架,都在持续优化 GEMM 核芯调度策略——哪怕提升几个百分点,都能直接转化为实实在在的速度优势。理解这套底层机制,对于使用 C++ 进行高性能计算编程的开发者而言至关重要。
更多冷知识
|  发表于 2026-3-15 17:36:33
|
查看: 191|
回复: 0
发表于 2026-3-15 17:36:33
|
查看: 191|
回复: 0
