PostgreSQL 以固定大小的数据块(Page)作为数据存储的基本单位,默认大小为 8 KB。当执行数据更新或插入操作时,PostgreSQL 并不会立即将这些变更写入物理磁盘,而是先将相关的数据页从磁盘加载到共享内存(Shared Buffers)中,并在内存中完成修改。此时,该内存中的页面版本已经比磁盘上的版本更新,因此被标记为“脏页”。
在向客户端返回操作成功之前,PostgreSQL 会首先将此次变更的记录写入预写日志(Write-Ahead Log,WAL),这一机制确保了即使在数据库发生崩溃时,也能通过重放WAL来恢复数据一致性。而实际的数据文件(即脏页的最终归宿)并不会立即更新,只有在特定的时机,如检查点(Checkpoint) 触发或由后台写进程执行刷新时,这些脏页才会被同步写回磁盘。
在此之前,脏页会持续驻留在共享内存中。其刷盘机制主要由以下三个部分协同完成:
- 后台写进程(Background Writer,BGWriter):这是一个常驻后台的进程,其核心职责是周期性地将部分脏页写入磁盘,以维持共享缓冲区中有足够数量的干净页面可供使用。
- 检查点进程(Checkpointer):当满足特定条件(例如达到
checkpoint_timeout 设置的时间,或 WAL 大小超过 max_wal_size)时,检查点进程会启动,并将所有脏页刷新到磁盘,这是一个相对集中且可能产生较大I/O压力的操作。
- 后端进程(Backend):在极端情况下,例如共享缓冲区几乎被脏页占满且后台进程来不及清理时,执行用户查询的后端进程可能会被迫自行执行写盘操作,这会导致当前查询被阻塞,对性能产生直接影响。
理解并合理调控脏页的刷新时机与方式,是优化 PostgreSQL 数据库性能 与稳定性的关键所在。
脏页为何影响性能
脏页机制虽然提升了写入效率,但若管理不当,会从多个维度对数据库性能造成负面影响:
1. 检查点期间的 I/O 峰值
检查点发生时,系统需要将所有累积的脏页一次性写入磁盘。如果脏页数量庞大,就会在短时间内产生剧烈的磁盘 I/O 压力,从而挤占正常查询的 I/O 资源,导致整体性能骤降。checkpoint_timeout(检查点时间间隔)、checkpoint_completion_target(检查点完成目标)和 max_wal_size(最大WAL大小)等参数共同决定了检查点的触发频率和刷盘节奏。
2. 后端写入带来的查询阻塞
当共享缓冲区中脏页过多,而后台写进程(BGWriter)清理速度跟不上时,后端进程将不得不介入写盘。这种“紧急写入”会直接阻塞正在执行该查询的进程,导致用户体验到的响应时间变长。理想状态下,应通过合理的参数配置,确保绝大多数脏页由 BGWriter 平稳写出。
3. 吞吐量与崩溃恢复时间的权衡
减少脏页刷新频率(例如,设置较长的 checkpoint_timeout)可以降低运行时 I/O 开销,提升吞吐量。但副作用是数据库崩溃后需要回放更大量的 WAL 日志才能恢复,延长了恢复时间。反之,频繁刷新脏页能加快恢复速度,却可能牺牲运行时性能。这需要根据业务对可用性和性能的侧重点进行权衡。
PostgreSQL 管理脏页的核心机制
后台写进程(Background Writer,BGWriter)
BGWriter 是一个独立的后台进程,其设计目标是在系统空闲时持续、平缓地写出脏页,从而避免脏页在检查点时集中爆发。其主要行为包括:
- 当共享缓冲区中可用的干净页面数量低于某个阈值时,主动写出部分脏页。
- 它可能在一个检查点周期内多次写出同一个被反复修改的页面,从而增加总写入量。
BGWriter 的行为由 postgresql.conf 中的一系列参数控制,合理的配置是 后端架构 调优的重要环节:
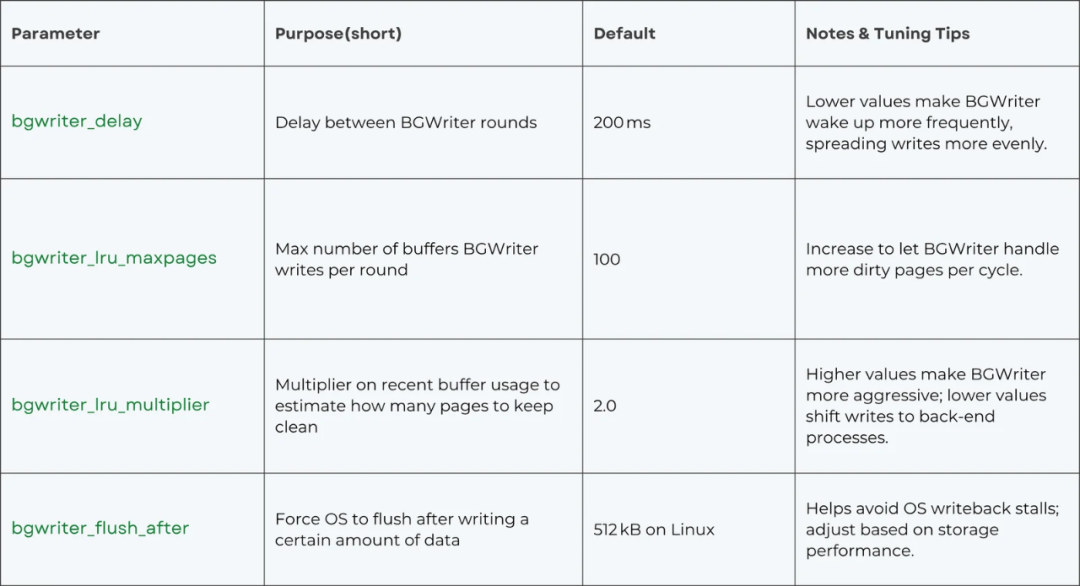
调优建议:
通过查看 pg_stat_bgwriter 视图,如果发现 buffers_backend(后端写盘数)较高,通常意味着 BGWriter 不够积极,可以尝试提高 bgwriter_lru_maxpages 和 bgwriter_lru_multiplier 的值。反之,如果BGWriter本身导致了过高的I/O,则应适当调低这些参数。
检查点(Checkpointer)
检查点是一个强制性的同步点,在此刻所有脏页都必须落盘,并在 WAL 中标记一个恢复位置。通过调整检查点参数,可以将密集的 I/O 压力分散到一个更长的时间窗口内:
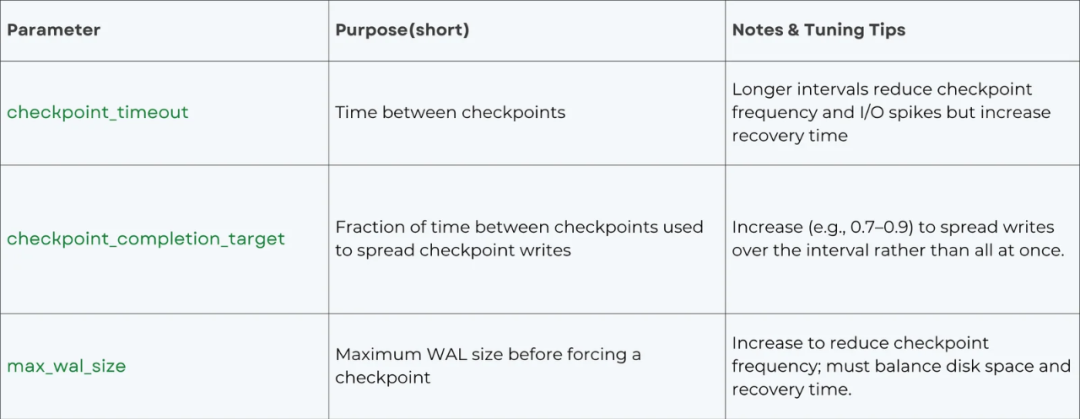
增大 checkpoint_timeout 和 max_wal_size 可以减少检查点频率;提高 checkpoint_completion_target(例如设为 0.9)可以指示系统在90%的检查点间隔时间内完成刷盘,从而平滑写入曲线。
共享缓冲区(Shared Buffers)
shared_buffers 参数定义了 PostgreSQL 用于缓存数据页(包括干净页和脏页)的专用内存大小。它直接影响数据页在内存中的驻留时间以及写盘的频率。
- 设置过小:缓存命中率低,页面频繁进出,可能增加后端写盘的概率。
- 设置过大:单次检查点需要刷新的脏页数量可能非常巨大,导致明显的 I/O 峰值。
通用建议是设置为物理内存的 25% 左右作为起点,并根据负载特征进行调整。增大 shared_buffers 时,通常也需要相应增大 max_wal_size。
自动清理(Autovacuum)的影响
自动清理进程在执行 VACUUM 或 VACUUM FREEZE 操作时,也会修改数据页并产生脏页。需要确保 autovacuum 的触发阈值和成本限制设置合理,使其既能有效防止表膨胀和事务ID回绕,又不会因过于激进而产生大量额外的写入 I/O。在 SSD 等高速存储上,可以适当提高 autovacuum_vacuum_cost_limit 以加速清理过程。
面向性能的调优实践
1. 监控先行
通过查询 pg_stat_bgwriter 视图获取关键指标,作为调优依据:
buffers_checkpoint:由检查点写出的页面数。buffers_clean:由 BGWriter 写出的页面数。buffers_backend:由后端进程写出的页面数。
调优的核心目标之一就是最小化 buffers_backend。
2. 配置共享缓冲区
以物理内存的 25% 为起点。对于读多写少的场景,可以适当调高以提升缓存命中率;对于写入密集、检查点I/O波动大的场景,可能需要略微调低以平滑写入。
3. 调整后台写进程(BGWriter)参数
bgwriter_delay:降低此值(如 100ms)可提高BGWriter的活跃度。bgwriter_lru_maxpages 与 bgwriter_lru_multiplier:在高写入负载下,提高这两个值(例如分别设为 500 和 3.0)可以让BGWriter每次唤醒时处理更多脏页。bgwriter_flush_after:设置为与存储设备最佳写入粒度匹配的值(SSD建议512KB-1MB)。
4. 优化检查点行为
checkpoint_timeout:适当增大至 30min 或 1h,减少触发频率。checkpoint_completion_target:提高至 0.8 或 0.9,让写入更平滑。max_wal_size:根据 shared_buffers 和写入负载增大,避免因WAL写满而触发紧急检查点。
5. 杜绝后端写入
持续监控 buffers_backend。若其值持续增长,应优先考虑扩大 shared_buffers 或增强 BGWriter 的写盘能力(调整上述参数),这是降低查询延迟的关键。
6. 操作系统层优化
- Linux 内核参数:调整
vm.dirty_background_ratio 和 vm.dirty_ratio,避免操作系统内核层累积过多脏页后突发写回,干扰数据库的 I/O 模式。
- 大页支持:在内存充足的服务器上,考虑启用 Huge Pages 并关闭 Transparent Huge Pages (THP),这可以减少内存管理开销,对于运维大规模数据库实例尤其有益。
7. 持续迭代评估
数据库负载是动态变化的。应结合 pg_stat_activity、pg_stat_bgwriter 以及 PostgreSQL 高版本引入的 pg_stat_io 等性能视图,持续观察调优效果,并进行微调。
总结
“脏页”是 PostgreSQL 利用内存缓冲写入、提升性能的核心机制。它通过延迟写盘合并 I/O 操作,并依赖 WAL 保证持久性。然而,不当的参数配置会导致脏页堆积,进而引发检查点 I/O 风暴或后端进程阻塞。
深入理解共享缓冲区、后台写进程、检查点与 WAL 的协同工作原理,并审慎调优 shared_buffers、bgwriter_* 系列参数以及检查点相关参数,是驾驭这一机制、在保障数据可靠性的同时实现平稳高性能数据库服务的关键。
 发表于 2025-12-16 23:40:36
|
查看: 217|
回复: 0
发表于 2025-12-16 23:40:36
|
查看: 217|
回复: 0
