目前,Google 是少数几家在 AI 产业链上实现端到端垂直整合的公司之一,其布局覆盖了从基础模型(如 Gemini)、应用产品(如 ImageFX),到云平台(Google Cloud, Vertex AI)乃至自研硬件(TPU)的完整链条。
长期以来,Google 一直致力于通过技术自研来降低对 NVIDIA GPU 的依赖,这种深厚的技术积累最终催生了如今备受瞩目的 JAX AI 栈。有趣的是,这套技术栈不仅 Google 内部广泛使用,也获得了包括 Anthropic、xAI 甚至 Apple 在内的多家头部 LLM 开发商的青睐。因此,我们非常有必要深入了解一下这套面向未来的技术体系。
什么是 JAX AI 栈?
简而言之,JAX AI 栈是一套为超大规模机器学习任务设计的端到端开源平台。其核心由以下四个关键组件构成:
1、JAX
JAX 是由 Google 主导开发的一个高性能 Python 数值计算库。它的 API 设计高度模仿 NumPy,易于上手,但其核心优势在于能够通过底层编译器,自动且高效地在 CPU、GPU 或 TPU 上执行计算,无论是单机还是分布式环境。
这一性能飞跃的关键在于 XLA (Accelerated Linear Algebra) 编译器。XLA 能够将 JAX 代码编译并优化为针对特定硬件的高效机器码。相比之下,传统的 NumPy 运算默认只能在 CPU 上运行,两者在处理大规模数据时的效率差异显著。
2、Flax
Flax 是基于 JAX 构建的神经网络库。如今,Flax 的核心是 NNX (Neural Networks for JAX),它提供了一个更简洁、直观的 API,用于创建、调试和分析 JAX 神经网络。
早期的 Flax Linen 采用纯粹的函数式、无状态编程风格。而作为继任者的 NNX,则引入了面向对象和有状态的特性,这使得习惯于 PyTorch 等框架的开发者能够以更熟悉的范式来构建和调试模型。
3、Optax
Optax 是 JAX 生态中专用于梯度处理和优化的库。它以其高度的灵活性著称,开发者可以轻松地通过链式组合,将标准优化器(如 SGD、Adam)与各种高级技巧(如梯度裁剪、权重衰减、梯度累积)结合起来。
4、Orbax
Orbax 是专门处理检查点(Checkpoint)的库,用于可靠地保存和恢复大规模训练任务的状态。它支持异步和分布式检查点,这对于动辄训练数周甚至数月的大语言模型至关重要——它确保了在硬件故障时能从最近的断点恢复,避免昂贵的算力资源浪费。
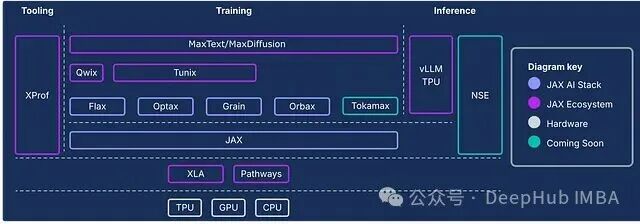
下图清晰地展示了 JAX AI 全栈的架构。除了上述四大核心,周边还有许多支持性工具和库,共同构成了一个完整的开发生态。
实战:使用 JAX 训练神经网络
JAX 在 GPU 和 TPU 上能够展现出超越 PyTorch 等框架的性能,主要得益于其即时编译(JIT)优化和 XLA 后端的高效编译。接下来,我们通过一个手写数字识别的实例,从头开始构建一个简单的神经网络,亲身体验 JAX 栈的实际开发流程。
1、环境配置
JAX AI 栈现已整合为一个元包(metapackage),安装非常简便。我们还需要 sklearn 来加载数据集,以及 matplotlib 进行结果可视化。
!uv pip install jax-ai-stack sklearn matplotlib
2、加载数据
我们使用 sklearn 自带的 UCI ML 手写数字数据集。
from sklearn.datasets import load_digits
# 加载数据集
digits = load_digits()
该数据集包含了 8 x 8 像素的手写数字图像(0-9)及其对应的标签。
print(f"Number of samples × features: {digits.data.shape}")
print(f"Number of labels: {digits.target.shape}")
"""
Number of samples × features: (1797, 64)
Number of labels: (1797,)
"""
3、数据可视化
首先,我们随机查看其中的100个样本,直观感受一下数据。
import matplotlib.pyplot as plt
fig, axes = plt.subplots(10, 10, figsize=(6, 6),
subplot_kw={'xticks':[], 'yticks':[]},
gridspec_kw=dict(hspace=0.1, wspace=0.1))
for i, ax in enumerate(axes.flat):
ax.imshow(digits.images[i], cmap='binary', interpolation='gaussian')
ax.text(0.05, 0.05, str(digits.target[i]), transform=ax.transAxes, color='green')

4、划分数据集
按照机器学习标准流程,将数据划分为训练集和测试集。
from sklearn.model_selection import train_test_split
# 划分数据集
splits = train_test_split(digits.images, digits.target, random_state=0)
5、转换为 JAX 数组
这是关键一步。在将数据输入模型前,我们需要使用 jax.numpy 将其转换为 JAX 专用的数组格式。
import jax.numpy as jnp
# 将划分好的数据转换为 JAX 数组
images_train, images_test, label_train, label_test = map(jnp.asarray, splits)
检查转换后的数据维度:
print(f"Training images shape: {images_train.shape}")
print(f"Training labels shape: {label_train.shape}")
print(f"Test images shape: {images_test.shape}")
print(f"Test labels shape: {label_test.shape}")
"""
Training images shape: (1347, 8, 8)
Training labels shape: (1347,)
Test images shape: (450, 8, 8)
Test labels shape: (450,)
"""
6、使用 Flax (NNX) 构建网络
我们使用 Flax 的 NNX 模块来构建一个简单的多层感知机(MLP),其中使用 SELU 作为激活函数。对于熟悉 PyTorch 的开发者来说,这种面向对象的定义方式会感到非常亲切。
from flax import nnx
class DigitClassifier(nnx.Module):
def __init__(self, n_features, n_hidden, n_targets, rngs):
self.n_features = n_features
self.layer_1 = nnx.Linear(n_features, n_hidden, rngs = rngs)
self.layer_2 = nnx.Linear(n_hidden, n_hidden, rngs = rngs)
self.layer_3 = nnx.Linear(n_hidden, n_targets, rngs = rngs)
def __call__(self, x):
x = x.reshape(x.shape[0], self.n_features) # 将图像展平
x = nnx.selu(self.layer_1(x))
x = nnx.selu(self.layer_2(x))
x = self.layer_3(x)
return x
7、实例化模型
JAX 采用一种显式的随机数生成器(RNG)管理方式。这里使用 nnx.Rngs(0) 初始化一个种子为 0 的 RNG 对象,它将负责管理模型中所有涉及随机性的操作(如参数初始化)。这与 PyTorch 设置全局种子的方式有所不同。
# 初始化随机数生成器
rngs = nnx.Rngs(0)
# 创建分类器实例
model = DigitClassifier(n_features=64, n_hidden=128, n_targets=10, rngs = rngs)
8、定义优化器与训练步骤
我们使用 Optax 来定义优化器和损失函数。
import jax
import optax
# 定义学习率为0.05的SGD优化器
optimizer = nnx.ModelAndOptimizer(
model, optax.sgd(learning_rate=0.05))
# 定义损失函数
def loss_fn(model, data, labels):
# 前向传播
logits = model(data)
# 计算平均交叉熵损失
loss = optax.softmax_cross_entropy_with_integer_labels(
logits=logits, labels=labels).mean()
return loss, logits
# 定义单步训练函数,并使用JIT编译加速
@nnx.jit # 使用JIT编译以提升执行速度
def training_step(model, optimizer, data, labels):
# `has_aux=True` 表示损失函数返回辅助输出(logits)
loss_gradient = nnx.grad(loss_fn, has_aux=True)
# 前向传播 + 反向传播,计算梯度
grads, logits = loss_gradient(model, data, labels)
# 使用计算出的梯度更新模型参数
optimizer.update(grads)
在这段代码中,我们运用了 JAX 的两个核心功能以实现高效计算:@nnx.jit 装饰器用于即时编译,将训练步骤函数交给 XLA 编译器进行深度优化,从而在重复执行时获得极速;nnx.grad 则用于自动微分计算梯度。Flax NNX 将这些底层变换封装成了更易用的接口。
9、执行训练循环
我们运行 500 个训练周期(epoch),并每隔 100 个周期打印一次损失值以监控训练过程。
num_epochs = 500
print_every = 100
for epoch in range(num_epochs + 1):
# 执行单步训练
training_step(model, optimizer, images_train, label_train)
# 定期评估并打印指标
if epoch % print_every == 0:
train_loss, _ = loss_fn(model, images_train, label_train)
test_loss, _ = loss_fn(model, images_test, label_test)
print(f"Epoch {epoch:3d} | Train Loss: {train_loss:.4f} | Test Loss: {test_loss:.4f}")
"""
Epoch 0 | Train Loss: 0.0044 | Test Loss: 0.1063
Epoch 100 | Train Loss: 0.0035 | Test Loss: 0.1057
Epoch 200 | Train Loss: 0.0029 | Test Loss: 0.1054
Epoch 300 | Train Loss: 0.0024 | Test Loss: 0.1052
Epoch 400 | Train Loss: 0.0021 | Test Loss: 0.1051
Epoch 500 | Train Loss: 0.0019 | Test Loss: 0.1050
"""
10、模型评估
最后,我们在测试集上评估训练好的模型的准确率。
# 在测试集上评估模型准确率
logits = model(images_test)
predictions = logits.argmax(axis=1)
correct = jnp.sum(predictions == label_test)
total = len(label_test)
accuracy = correct / total
print(f"Test Accuracy: {correct}/{total} correct ({accuracy:.2%})")
# Test Accuracy: 437/450 correct (97.11%)
对于一个结构如此简单的网络,在测试集上达到 97.11% 的准确率是一个相当不错的结果。最后,我们将部分预测结果可视化,用绿色标注正确预测,红色标注错误预测。
fig, axes = plt.subplots(10, 10, figsize=(6, 6),
subplot_kw={'xticks':[], 'yticks':[]},
gridspec_kw=dict(hspace=0.1, wspace=0.1))
for i, ax in enumerate(axes.flat):
ax.imshow(images_test[i], cmap='binary', interpolation='gaussian')
color = 'green' if predictions[i] == label_test[i] else 'red'
ax.text(0.05, 0.05, str(predictions[i]), transform=ax.transAxes, color=color)

至此,你已经成功在 JAX 生态中完成了第一个神经网络的训练全流程。虽然 JAX 及其生态有一定的学习曲线,但它为大规模机器学习任务带来的显著性能提升,使其成为值得深入研究和投入的下一代 人工智能 开发工具。
 发表于 2025-12-16 23:57:06
|
查看: 222|
回复: 0
发表于 2025-12-16 23:57:06
|
查看: 222|
回复: 0
