状态管理是Apache Flink实现有状态流处理的核心,而其容错保障则依赖于Checkpoint机制。本文将深入Flink源码,详细拆解一次Checkpoint从JobManager触发、TaskManager执行到最终JobManager确认的全过程,并分析Exactly-Once与At-Least-Once两种语义下非Source节点的处理差异。
核心流程回顾
一次完整的Checkpoint由CheckpointCoordinator协调触发。Source节点收到请求后,持久化自身状态并向所有下游广播一个特殊标记——Barrier。下游节点接收到来自所有上游的Barrier后,同样会持久化状态并继续向下游传递Barrier。当整个DAG图中所有任务都完成状态快照后,CheckpointCoordinator会将此次检查点的元数据信息持久化,标志着一次成功的Checkpoint。
JobManager端:触发流程
作业在ExecutionGraph生成后,会调用executionGraph.enableCheckpointing方法,此方法创建了核心协调者CheckpointCoordinator并注册相关监听器。当作业进入RUNNING状态,Coordinator会部署一个周期性调度任务(ScheduledTrigger)来触发Checkpoint。
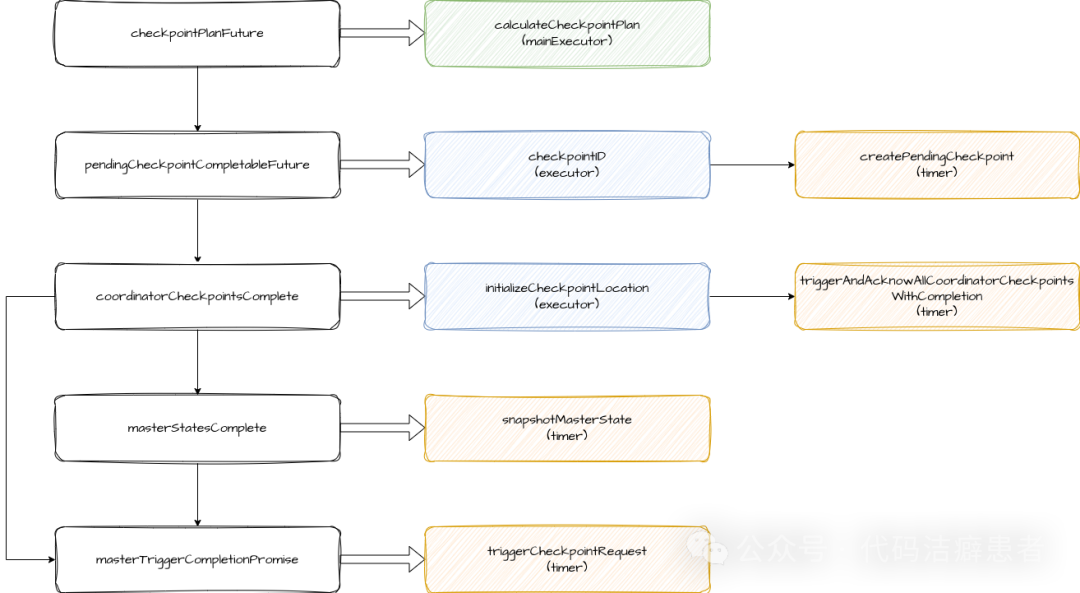
触发逻辑的核心位于CheckpointCoordinator.startTriggeringCheckpoint方法,它利用多个CompletableFuture进行异步编排:
- checkpointPlanFuture:生成Checkpoint执行计划,其中包含
tasksToTrigger(所有Source任务)、tasksToWaitFor和tasksToCommitTo集合。
- pendingCheckpointCompletableFuture:生成递增的CheckpointID并创建
PendingCheckpoint对象,用于跟踪所有待完成的任务。
- coordinatorCheckpointsComplete:初始化存储路径,并触发所有
OperatorCoordinator的状态快照。
- masterStatesComplete:触发所有Master Hook,用于收集JobManager级别的状态。
- masterTriggerCompletionPromise:在上述Future完成后执行,其核心任务是调用
triggerCheckpointRequest向各个TaskManager发送触发指令。
至此,JobManager完成了触发指令的下发。为了保障这类复杂分布式系统的协调逻辑可靠运行,异步编排和状态跟踪至关重要。
TaskManager端:执行流程
TaskExecutor接收到触发指令后,核心逻辑在SubtaskCheckpointCoordinatorImpl.checkpointState方法中展开,主要分为以下步骤:
- 检查Checkpoint是否已被取消,若是则广播取消消息。
- 执行前置准备操作(通常为空实现)。
- 向下游广播Barrier消息。
- 注册对齐计时器,超时则转为非对齐(Unaligned)Checkpoint。
- 通知状态写入器(StateWriter)输出通道已完成写入,并提交状态句柄。
- 异步执行状态写入并上报结果。
Barrier的广播
Barrier消息包含Checkpoint ID、时间戳以及CheckpointOptions(对齐类型、Checkpoint类型、存储地址等参数)。生成后,通过operatorChain.broadcastEvent方法广播至下游所有ResultSubpartition。
状态的写入
SubtaskCheckpointCoordinatorImpl.takeSnapshotSync方法负责构建OperatorSnapshotFutures,它包含四个RunnableFuture,分别对应不同类型状态的写入:
keyedStateManagedFuturekeyedStateRawFutureoperatorStateManagedFutureoperatorStateRawFuture
底层会为每个Operator设置对应的State Future。设置完成后,在finishAndReportAsync方法中创建AsyncCheckpointRunnable线程异步获取快照结果,并将最终信息上报回JobManager的CheckpointCoordinator。

JobManager端:确认流程
TaskManager通过RPC调用checkpointCoordinatorGateway.acknowledgeCheckpoint上报结果后,流程回到JobManager。确认流程主要完成两件事:
- 状态转换与清理:将
PendingCheckpoint转换为CompletedCheckpoint,在此过程中会清理过期的Checkpoint并持久化元数据。
- 通知提交:向所有需要提交(commit)的任务发送Checkpoint完成的通知。大部分任务无特殊逻辑,但部分Source或Sink算子可能会利用此通知提交外部事务。
至此,一次涉及JobManager和Source节点的Checkpoint核心流程完成。下面我们分析非Source节点如何处理Barrier。
非Source节点:Barrier处理流程
非Source节点处理Barrier的入口与处理普通数据相同,均为StreamTask.processInput方法。流程会根据配置的语义选择不同的BarrierHandler:
SingleCheckpointBarrierHandler:负责EXACTLY_ONCE语义。CheckpointBarrierTracker:负责AT_LEAST_ONCE语义。
EXACTLY_ONCE 处理逻辑
- 单输入通道:立即触发Checkpoint。
- 多输入通道:
- a) 收到第一个Barrier:开始对齐,并阻塞该通道。
- b) 收到非首尾Barrier:仅阻塞该通道。
- c) 收到最后一个Barrier:触发Checkpoint,并取消所有通道的阻塞。
AT_LEAST_ONCE 处理逻辑
- 单输入通道:立即触发Checkpoint。
- 多输入通道:
- a) 收到第一个Barrier:更新当前Checkpoint ID,标记开始对齐(不阻塞通道)。
- b) 收到非首尾Barrier:仅进行计数。
- c) 收到最后一个Barrier:触发Checkpoint。
无论哪种语义,最终的触发逻辑都会调用performCheckpoint方法,与Source节点的执行流程汇合。
总结
本文系统梳理了Flink Checkpoint的源码执行链路。整个过程始于JobManager中CheckpointCoordinator的周期性调度,通过RPC触发各个TaskManager。Source节点作为起点,广播Barrier并持久化状态;下游节点根据配置的语义进行Barrier对齐与状态快照。所有状态快照完成后,信息汇总至Coordinator,由其完成元数据持久化并通知任务提交。作为大数据流处理框架的基石,Checkpoint机制确保了Flink在分布式环境下的容错与状态一致性。下篇我们将深入状态后端,分析状态数据的具体写入逻辑。 |  发表于 2025-12-16 23:54:27
|
查看: 224|
回复: 0
发表于 2025-12-16 23:54:27
|
查看: 224|
回复: 0
