在 Elasticsearch 中文搜索的研发实践中,IK 分词器因其简单高效、能覆盖多数中文场景的特性,已成为电商、资讯、社区等系统的标配组件。
然而,在一些对稳定性要求极高的业务场景(如大促、热点事件期间),IK 分词器某些固有的设计机制,却可能引发意想不到的线上故障。
本文将通过一次真实线上事故的深度复盘,剖析开源 IK 分词器在架构设计上的局限性,并详细介绍阿里云 ES Serverless 如何通过创新的“索引级词典”能力,从根本上规避因热更新导致的搜索错配与数据“消失”问题。
一、一次常规热词更新引发的P0级事故
1. 事故背景
某电商平台在大促活动前夕,运营人员发现网络热词“哈基米”(泛指猫咪/宠物)的搜索量急剧攀升。由于 IK 分词器的默认词典并未收录该词,导致用户搜索“哈基米”时,查询词被切分为[哈, 基, 米]三个单字。这种分词结果使得系统召回了大量包含“哈”、“基”、“米”字的无关商品,严重拉低了搜索转化率。运营随即提出紧急需求:必须让“哈基米”作为一个整体词汇进行精确匹配。
2. 标准操作与预期
研发团队按照“标准”流程进行了变更:
- 在远程词典文件中新增了词汇“哈基米”。
- 触发集群所有节点的词典热更新。
- 通过
_analyze API 验证,确认“哈基米”已被正确识别为一个完整的 Term。
一切验证通过,变更看似成功。
3. 事故爆发
就在词典热更新完成瞬间,线上实时搜索服务出现异常:
- 新数据表现正常:刚刚上架、描述中包含“哈基米”的新商品可以被搜到。
- 旧数据彻底消失:所有在词典更新前已入库、描述中包含“哈基米”的存量商品,全部无法通过搜索找到!
原因一时间难以定位——索引未做任何改动,存量数据却突然“失效”。本次旨在提升用户体验的优化,最终导致搜索服务故障、GMV下跌,演变为一次 P0 级线上事故。

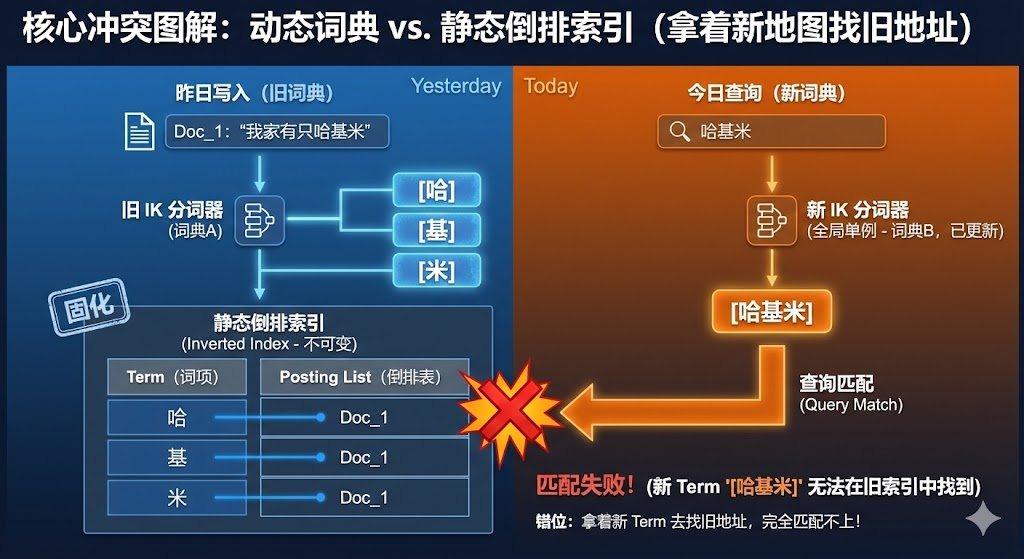
二、根源剖析:IK词典热更新的“时空错位”
上述现象并非 Elasticsearch 的 Bug,而是开源 IK 分词插件的设计机制与倒排索引的核心特性产生了不可调和的冲突。
1. 核心矛盾:动态全局词典 vs 静态倒排索引
- IK的“全局单例”机制:IK 分词器在实现上采用了节点级别全局共享词典的策略。一旦触发热更新,集群内所有节点、所有使用该分词器的索引(无论其数据何时写入)都会立即强制切换到新词典进行查询分词。这是一个影响范围极广的操作。
- ES索引的“不可变”特性:文档写入时,其文本内容经分词后生成的 Term 会被永久写入倒排索引中。这份索引是静态的,不会因后续词典的变更而改变。
冲突的本质在于:为了匹配未来的新数据(新热词)而更新了全局词典,却无意中破坏了基于旧词典建立的存量数据的查询逻辑。
2. “时空错位”过程图解
让我们清晰还原事故过程:
- 热更新前(旧词典):词汇“哈基米”未被收录,写入数据时被切分为
[哈, 基, 米] 三个单字 Term 存入倒排索引。
- 热更新后(新词典):词典加入“哈基米”后,用户搜索该词时,查询请求被解析为整体 Term
[哈基米]。
结果就是,查询时使用的 Term [哈基米] 与倒排索引中存储的旧 Term [哈, 基, 米] 完全无法匹配。这好比用今天的新地图去导航昨天布局的城市,必然无法找到目的地。
三、传统应对方案及其局限
面对词典版本与数据版本错配这一经典难题,业界通常采用以下三种方案进行“补救”,但均存在显著缺陷:
| 方案 |
思路 |
具体操作 |
优点 |
缺点 |
| 1. 休克疗法 |
低峰期热更并全量重建索引 |
更新词典后,立即对索引执行 _update_by_query 或全量数据重导。 |
逻辑简单,最终一致。 |
导致搜索短暂不可用,全量数据重洗消耗大量计算与I/O资源。 |
| 2. 同义词补丁 |
将新词映射回旧分词结果 |
配置同义词规则,如 "哈基米, 哈 基 米",使查询能匹配旧数据。 |
无需重建索引,可快速止血。 |
需同时维护词典和同义词表两套配置,增加查询复杂度与维护成本。 |
| 3. 蓝绿双集群 |
新词典建新集群,数据同步后切换流量 |
旧集群服务线上,新集群同步数据,追平后切换用户流量。 |
新旧环境完全隔离,风险低。 |
硬件成本翻倍,双写或同步下的数据一致性维护极其复杂。 |
这些传统方案都无法同时满足以下三个核心诉求:
- 无感更新:用户对后台切换过程无感知。
- 精准匹配:新热词立即生效,查询准确。
- 存量稳定:老数据的搜索结果保持绝对稳定。
四、阿里云 ES Serverless 的破局之道:索引级词典隔离
为解决开源IK“全局单例”词典的根本性冲突,阿里云 ES Serverless 对内核进行了深度改造,推出了 “集群-索引-分词器”三级词典配置体系,将词典控制权精细化。
1. 多级词典体系设计
该体系允许在不同层级配置词典,并遵循明确优先级:分词器级 > 索引级 > 集群(租户)级。
- 集群级:由平台统一管理基础词典,确保租户内基础词汇一致性,优先级最低。
- 索引级(关键):可为每个索引单独绑定专属的扩展词典和停用词典。此能力是解决“时空错位”的关键,它让词典版本与数据版本得以对齐。
- 分词器级:可为索引内某个自定义分词器配置专用词典,满足特定字段的特殊需求,优先级最高。
对于 实时热词更新 场景,“索引级词典”提供了完美方案。例如,你可以让 product_v1 索引绑定 dict_v1,product_v2 索引绑定 dict_v2。两个索引在同一集群内并行运行,互不干扰,彻底解决了新旧词典兼容性问题。
2. 无感热更新标准化流程
以上线“哈基米”为例,在阿里云 ES Serverless 上的最佳实践流程如下:
-
Step 1: 隔离运行,保持稳定
- 线上索引
product_v1(绑定别名 product_alias)继续使用旧词典 dict_v1。
- 用户查询不受任何影响,存量数据正常匹配。
-
Step 2: 构建对齐新词典的数据索引
- 创建包含“哈基米”的新词典
dict_v2。
- 新建索引
product_v2,并在创建时即绑定新词典 dict_v2。
- 通过
_reindex API 或更推荐的 T+1离线数据链路(如 DTS、ODPS、Flink等大数据处理工具),将 product_v1 的数据全量灌入 product_v2。此过程在后台静默进行。
-
Step 3: 原子切换,实现无感
- 待
product_v2 数据追平后,通过别名原子操作,将 product_alias 从 product_v1 切换到 product_v2。
- 切换瞬间完成,用户无感知。切换后,所有新查询和写入均作用于使用新词典的
product_v2。
3. 实现效果
通过“索引级词典隔离 + 原子切换”的组合方案,实现了:
- 零服务中断:整个更新和切换过程对用户透明,无查询失败或结果断层。
- 精准匹配:流量切换后,新词“哈基米”即刻生效,新旧数据均能被准确查询。
- 弹性支撑:依托 Serverless 的自动扩缩容能力,可轻松应对大促等算力峰值。

4. 内核级增强优势
除了索引级词典,阿里云 ES Serverless 还通过内核优化带来了额外收益:
- 杜绝词典脑裂:确保集群内所有节点词典强一致。
- 无感兼容升级:及时同步开源 IK 与原生 ES 的最新特性。
这些能力共同将热词更新从一项“高风险运维操作”转变为安全、稳定的常规工作。
五、附录:传统方案与Serverless方案配置实操
1. 传统“休克疗法”操作指南
假设线上索引为 product_v1。
# 1. 低峰期更新远程词典,加入“哈基米”,并触发热加载。
# 2. 执行全量更新,强制旧数据按新词典重分词
POST /product_v1/_update_by_query?refresh=true&conflicts=proceed
{
"script": {
"source": "ctx._source.content = ctx._source.content",
"lang": "painless"
}
}
# 3. 验证特定文档的分词结果
GET /product_v1/_termvectors/{文档ID}?fields=content
2. 传统“同义词补丁”操作指南
# 1. 更新索引设置,添加同义词过滤器
PUT /product_v1/_settings
{
"analysis": {
"filter": {
"my_synonym_graph": {
"type": "synonym_graph",
"synonyms": ["哈基米, 哈 基 米"]
}
},
"analyzer": {
"my_search_analyzer": {
"tokenizer": "ik_smart",
"filter": ["my_synonym_graph"]
}
}
}
}
# 2. 更新字段Mapping,指定查询时使用带同义词的分析器
PUT /product_v1/_mapping
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word", // 写入分词器不变
"search_analyzer": "my_search_analyzer" // 查询时使用同义词分析器
}
}
}
3. 阿里云 ES Serverless “索引级词典”实操
前提:已在控制台上传词典 dict-v1 和 dict-v2。
Step 1: 线上服务稳定运行
创建索引 product_v1 并绑定旧词典,写入测试数据。
PUT /product_v1
{
"settings": {
"number_of_shards": 5,
"ik.extra_dict_ids": "dict-v1"
},
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
# 绑定别名
POST /_aliases
{
"actions": [
{ "add": { "index": "product_v1", "alias": "product_alias", "is_write_index": true } }
]
}
此时搜索“哈基米”,因词典未收录,可能匹配到无关文档。
Step 2: 安全引入新词典
创建新索引 product_v2 并绑定新词典 dict-v2,然后迁移数据并切换别名。
# 创建新索引并绑定新词典
PUT /product_v2
{
"settings": {
"number_of_shards": 5,
"ik.extra_dict_ids": "dict-v2"
},
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
# 迁移数据
POST _reindex
{
"source": { "index": "product_v1" },
"dest": { "index": "product_v2" }
}
# 原子切换别名
POST /_aliases
{
"actions": [
{ "remove": { "index": "product_v1", "alias": "product_alias" } },
{ "add": { "index": "product_v2", "alias": "product_alias", "is_write_index": true } }
]
}
切换后,通过别名 product_alias 的查询将直接命中 product_v2,新词“哈基米”精准匹配,整个过程服务不间断。
六、总结
开源 IK 分词器的节点级全局词典机制,在热更新场景下与 Elasticsearch 的静态倒排索引存在天然矛盾。传统解法往往需要在业务连续性、数据准确性和运维成本之间艰难权衡。
阿里云 ES Serverless 通过创新的 “索引级词典” 架构,从根源上解决了这一矛盾,实现了词典版本与数据版本的精准对齐。该方案不仅能确保热更新过程对用户完全透明、无感知,还能保障存量数据查询的绝对稳定,是构建高可靠、易运维的现代化搜索中间件系统的优选方案。
 发表于 2025-12-17 01:44:06
|
查看: 157|
回复: 0
发表于 2025-12-17 01:44:06
|
查看: 157|
回复: 0
