目录
一、背景
二、什么是index(索引)
三、索引结构详解
- 别名
- 映射
- 字段类型
- 针对字段类型选择的几条建议
- 索引结构与关系性数据库对比
四、索引(Shard)结构-分片与副本
- 什么是Shard
- 分片数规划
- 索引与资源消耗的关系
五、总结
背景
随着Elasticsearch在业务场景中的应用日益广泛,平台对其集群的稳定性、管理和运维的压力也与日俱增。在日常运维中,我们常发现用户对ES的了解程度不一,索引创建不规范或盲目模仿他人的情况时有发生,对索引本身及其结构规划缺乏清晰认知。
为此,平台采取了一系列措施来引导用户合理规划,例如:将索引、模板的创建接入飞书审批流,由平台结合业务场景和集群情况详细沟通确定结构;又如,我们在ES内核层面开发了业务不停服的动态扩分片能力,旨在治理不合理的索引以提升集群稳定性(索引一旦创建,分片数通常不可修改)。
因此,有必要从ES索引的基础讲起,帮助大家建立从概念、原理到使用的清晰认知。本文旨在为日常使用ES的开发者提供一份详尽的规划参考。当然,文中难免包含一些主观分析,欢迎大家探讨指正。现在,让我们开始深入了解Elasticsearch的索引。
二、什么是index(索引)
下面会结合官方文档,针对索引的组成和基本结构进行逐一介绍。
基本概念
索引是具有相似特征的文档集合,类似于关系型数据库中的表。每个索引都有自己唯一的名称或别名,并可配置不同的参数与映射,以适应多样化的业务场景。
索引中的最小单位是文档。每一个文档都是一个JSON格式的数据对象,包含了实际的业务数据以及与之相关的元数据。文档可以是结构化、半结构化或非结构化的数据。在Elasticsearch中,索引被用于存储、检索与分析数据,通过对索引进行搜索与聚合操作,可以快速地定位到相关文档。
官方描述:The index is the fundamental unit of storage in Elasticsearch, a logical namespace for storing data that share similar characteristics. After you have Elasticsearch deployed, you’ll get started by creating an index to store your data.
翻译:索引是Elasticsearch中存储数据的基本单位,是一个逻辑命名空间,用于存储具有相似特性的数据。在部署Elasticsearch后,您将通过创建索引来存储数据。
An index is a collection of documents uniquely identified by a name or an alias. This unique name is important because it’s used to target the index in search queries and other operations.
翻译:索引是一种文档集合,通过名称或别名唯一标识。这个唯一名称非常重要,因为它用于在搜索查询和其他操作中定位索引。
三、索引结构详解
一个完整的索引定义通常包含三个核心部分:别名、映射和设置。你是否清楚每部分的具体作用?
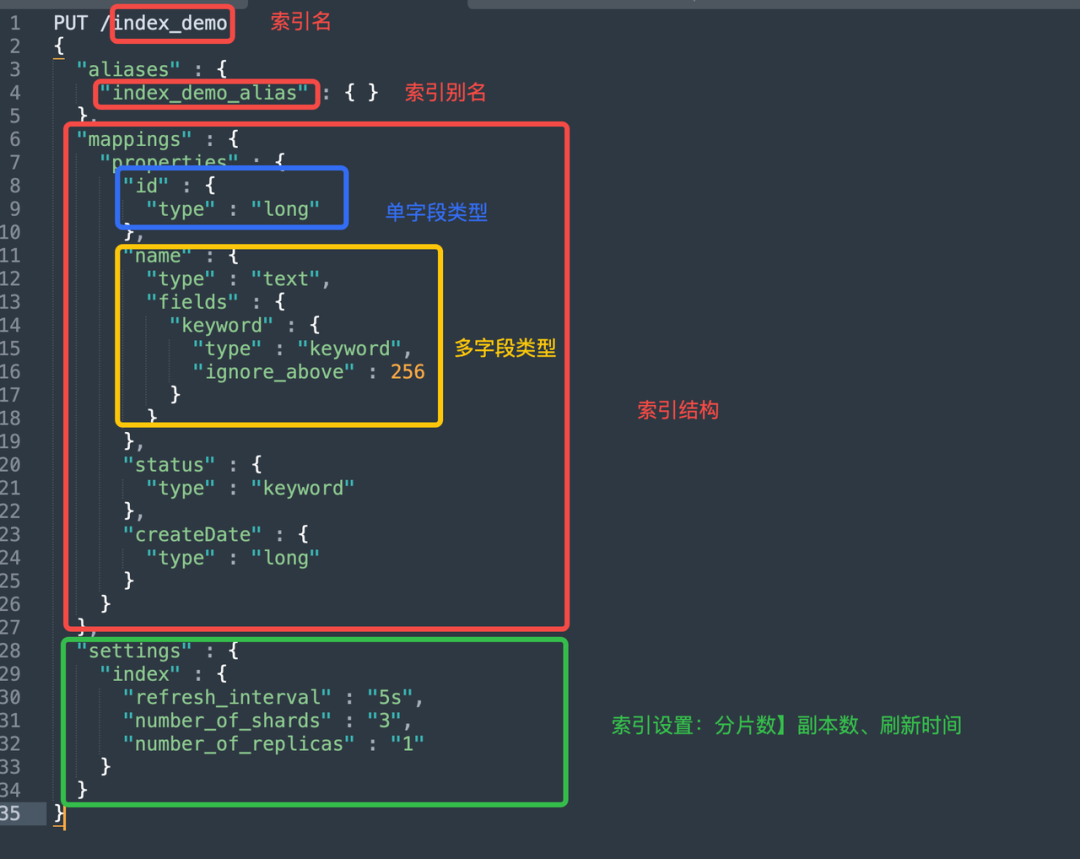
PUT /index_demo
{
“aliases” : {
“index_demo_alias” : { }
},
“mappings” : {
“properties” : {
“id” : {
“type” : “long”
},
“name” : {
“type” : “text”,
“fields” : {
“keyword” : {
“type” : “keyword”,
“ignore_above” : 256
}
}
},
“status” : {
“type” : “keyword”
},
“createDate” : {
“type” : “long”
}
}
},
“settings” : {
“index” : {
“refresh_interval” : “5s”,
“number_of_shards” : “3”,
“number_of_replicas” : “1”
}
}
}
ignore_above属性说明:
ignore_above的默认值通常为256个字符,这意味着任何超过256个字符的字符串将不会被索引或存储。- 该参数仅适用于
keyword类型的字段,因为这些字段主要用于过滤、排序和聚合操作,不需要进行全文搜索。
ignore_above的值以字符为单位计算,包括英文字符和汉字。例如,一个汉字和一个英文字符都算作一个字符。- 性能优化:通过限制字段长度,可以减少索引大小和查询时间,从而提高性能。
- 避免资源浪费:对于包含大量数据的字段,如日志文件中的长字符串,可以通过
ignore_above避免不必要的存储和索引。
官方描述:Strings longer than the ignore_above setting will not be indexed or stored. For arrays of strings, ignore_above will be applied for each array element separately and string elements longer than ignore_above will not be indexed or stored.
别名
别名是存储在集群状态中的轻量级对象,由主节点管理。它的开销仅仅是集群状态映射中的一个额外键,因此维护数千个别名也不会对集群产生显著的负面影响。
官方原话:An alias points to one or more indices or data streams. Most Elasticsearch APIs accept an alias in place of a data stream or index name.
Aliases enable you to:
- Query multiple indices/data streams together with a single name
- Change which indices/data streams your application uses in real time
- Reindex data without downtime
翻译:别名可以指向一个或多个索引或数据流。大多数Elasticsearch API接受别名代替数据流或索引名称。别名的功能包括:
- 使用单一名称查询多个索引/数据流;
- 实时更改应用程序使用的索引/数据流;
- 在不中断服务的情况下进行扩分片。
可以看到,别名主要有以上三个作用。平台强烈建议为每个索引添加别名(动态扩分片功能依赖别名)。虽然别名可以在索引创建后随时添加,但平台仍建议在创建索引时就指定好别名,以避免在需要动态扩分片时,再去修改代码和重新部署应用。
添加别名的几种方式
1. 创建索引时指定别名
PUT /test_index
{
“settings” : {
“number_of_shards” : 1,
“number_of_replicas” : 1
},
“aliases”:{“test_alias”:{}},
“mappings” : {
“properties” : {
“field1” : {
“type” : “text”
},
“createdAt”: {
“type”: “date”,
“format”: “yyyy-MM-dd HH:mm:ss”
}
}
}
}
2. 为已存在的索引添加别名
POST /_aliases
{
“actions”: [
{
“add”: {
“index”: “test_index”, # 索引名
“alias”: “test_alias” # 别名
}
}
]
}
3. 别名更换
别名更换是实现零停机动态扩分片的关键。
POST /_aliases
{
“actions”: [
{
“add”: {
“index”: “existing_index”,
“alias”: “test_alias” # 别名
},
“remove”: {
“index”: “old_index”,
“alias”: “old_test_alias” # 别名
}
}
]
}
映射
在建立索引时,需要定义文档的数据结构,这种结构称为映射。映射定义了每个字段的类型和属性。字段类型一旦设定,通常不能更改,因为Elasticsearch已经根据定义的类型建立了特定的索引结构。
不过,Elasticsearch允许向映射中新增字段。同时,它也提供了自动映射功能:当写入数据时,如果某个字段没有预定义类型,ES会根据字段值的特性自动推断其类型并进行映射。
字段类型
字段类型是定义数据如何存储和索引的核心概念,它直接影响字段的搜索、排序和聚合行为。这里重点介绍日常中最常用的三种字段类型:text、keyword和数值类型。
Text
text字段类型是用于全文搜索的核心类型。它会通过分析器将文本拆分为单个词项,并存储为倒排索引,非常适合非结构化文本的搜索。然而,也正是因为经过了分析处理,它不适用于直接的排序和聚合操作。
1. 特点
- 全文搜索:主要用于存储和索引可读的文本内容,如文章正文、产品描述等。这些字段会被分析器处理,拆分为词项以便进行模糊匹配。
- 分词处理:支持不同的分词器,可以根据语言和需求选择策略。分词结果构成倒排索引,实现快速检索。
- 不适用于排序和聚合:由于原始字符串被分词,无法直接用于精确排序或聚合。若需要此类操作,通常需结合
keyword类型。
- 支持多字段映射:可以通过多字段映射,让同一个字段同时拥有
text类型(用于搜索)和keyword类型(用于排序/聚合)。
2. 使用场景
- 全文搜索:搜索引擎、商品搜索、内容平台等需要模糊匹配的场景。
- 文本分析:结合TF-IDF、BM25等算法进行文本相似度计算。
- 日志分析:搜索和分析日志文件中的文本信息。
- 内容管理:存储和搜索文档、博客等富文本内容。
3. 官方建议
Use a field as both text and keyword
Sometimes it is useful to have both a full text (text) and a keyword (keyword) version of the same field: one for full text search and the other for aggregations and sorting. This can be achieved with multi-fields.
通过多字段映射同时使用text和keyword类型,可以实现全文搜索和精确匹配的双重需求。
4. 平台建议
- 明确业务场景。如果不需要进行模糊搜索,应直接设置为
keyword类型,以避免分词带来的额外存储和计算开销,减轻系统压力。
Keyword
keyword字段类型用于存储和索引结构化数据。它将字段值作为一个完整的词项进行存储,不进行任何分词处理。
1. 特点
- 不进行分词:字段值被原样存储到倒排索引中,保持完整性。
- 精确匹配:专为精确匹配查询设计,如查找特定ID、状态码、邮箱等。
- 提示:在
term查询中可结合case_insensitive属性实现不区分大小写的搜索,但terms查询不支持此属性。
- 支持排序和聚合:可以直接用于排序和聚合操作。
- 存储效率高:由于无需分词,存储开销相对较低,适合存储大量具有唯一性或枚举值的字段。
2. 使用场景
- 精确查询:ID、订单号、状态码、标签等需要完全匹配的场景。
- 排序和聚合:按用户ID排序、按商品类目统计数量等。
- 标签和分类:用户画像标签、产品分类等结构化数据。
- 唯一性字符串:商品SPU ID、ISBN号等。
Numeric
数值类型,包括long、integer、short、byte、double、float等。
1. 特点
- 整数类型:适合范围查询、排序和聚合。在满足需求的前提下,优先选择范围较小的类型(如
integer)以节省空间和提升性能。
- 浮点类型:用于需要高精度计算的场景。若数据范围大或精度要求不高,可考虑使用
scaled_float类型并设置合适的scale因子。
- 选择合适的类型:根据数据实际范围选择最贴切的类型,避免资源浪费。
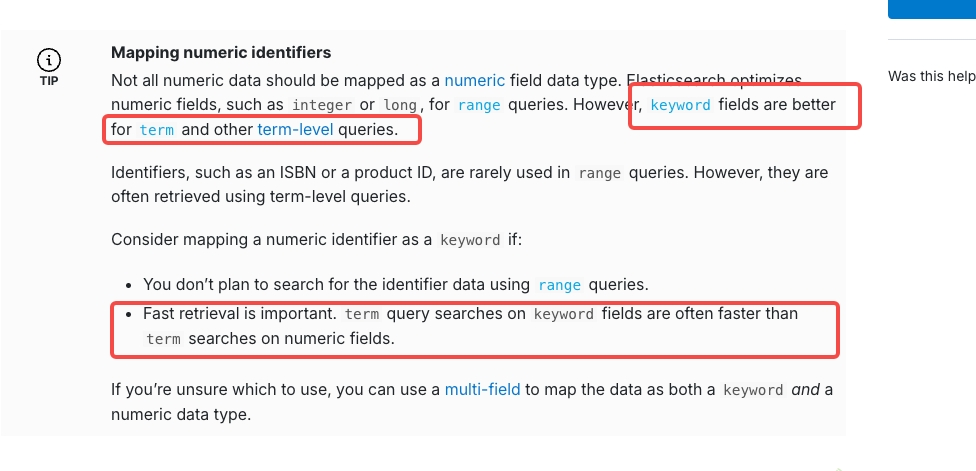
提示
如果业务场景明确,建议用keyword替代数值类型字段,因为keyword在term查询中性能更优。如果不确定,可采用多字段映射来兼顾。
针对字段类型选择的几条建议
- 针对原本计划使用
Text和数值类型的字段,在不需要模糊搜索或范围查询时,尽量改用keyword类型,以提升查询速度。
- 在不完全确定未来查询需求的情况下,为字段设置多字段类型,同时包含
keyword。
- 枚举类型字段,若无特殊业务要求,统一使用
keyword类型。
- 如果业务上不需要范围查询,优先使用
keyword类型(它同样支持聚合和排序)。
- 对
keyword字段进行模糊查询(通配符)性能较差,若有此需求,建议使用wildcard字段类型来获得更高的模糊查询性能。
- 尽量避免对
text字段进行聚合查询,因为其fielddata会大量占用内存。如有聚合需求,请使用keyword类型的子字段。
- 若需中文分词,不要使用默认分词器。推荐使用
ik_smart,ik_max_word会产生更多(可能重复的)分词,需谨慎评估使用。
- 时间字段不要使用
keyword(除非是纯点查)。推荐使用date或long类型,它们支持高效的范围查询。建议时间精度精确到分钟,有助于提高查询效率。
keyword类型不适用于通配符模糊查询,此类场景建议使用wildcard类型。

- 查询条件中使用
now等相对时间时,无法有效利用缓存,应尽量替换为绝对时间值。
- ES默认允许的字段数上限为1000,但建议实际字段数不要超过100。对于不需要建立索引的字段,不要写入ES。
- 将不需要被搜索的字段的
index属性设置为false,避免分词和索引,减少不必要的运算。
- 不建议或禁止在每次写入后立即执行显式的
refresh操作。refresh会带来较高的磁盘IO和CPU消耗,频繁操作甚至可能导致ES节点不稳定。
- (持续补充中...)
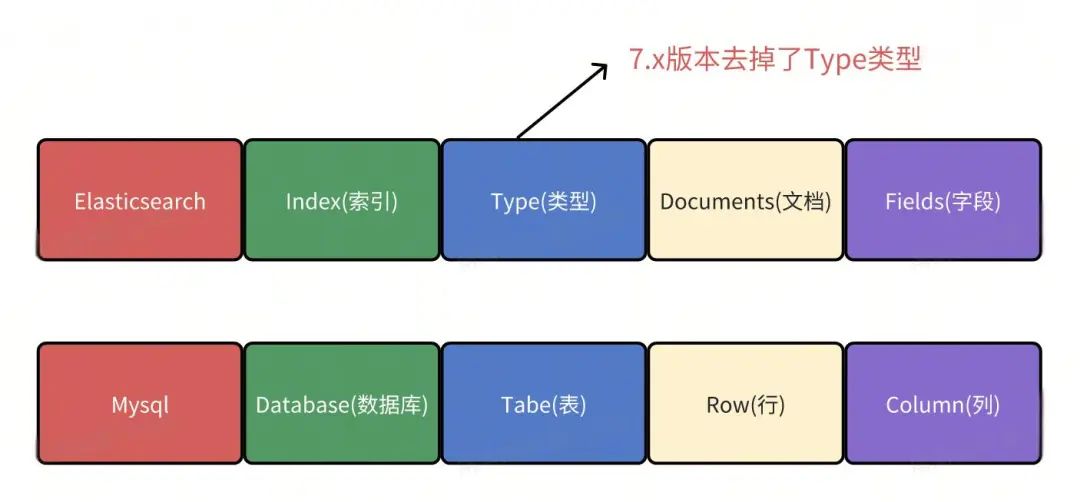
索引结构与关系性数据库对比
为了帮助理解,可以将Elasticsearch的核心概念与关系型数据库(如MySQL)进行类比:
四、索引(Shard)结构-分片与副本
什么是Shard
基本概念
分片是索引内管理文档的基本数据单元,是一个逻辑概念。ES内部会按照一定的路由规则(通常是文档_id的哈希值对主分片数取模),将文档分配到不同的存储单元中,这些存储单元就是分片。你可以将其类比为MySQL中的分表。
一个Elasticsearch索引由一个或多个分片组成。每个分片本质上是一个完整的Lucene索引。当ES执行搜索时,它会将查询发送到索引下的每一个分片(即每个Lucene索引),然后合并所有分片的结果,形成最终的全局结果集。
分片划分
分片分为主分片和副本分片。
- 主分片:索引的基本数据存储单元。每个索引被水平拆分为多个主分片,每个分片都是独立的,包含一部分索引的数据和结构。主分片可以在集群的不同节点间分布,以实现数据扩展和负载均衡。
- 副本分片:主分片的完整拷贝,主要用于数据冗余和高可用。在节点数充足的情况下,副本分片与对应的主分片不会分配在同一个节点上。
注意:单个分片内可存储的文档条数上限为 2,147,483,519。
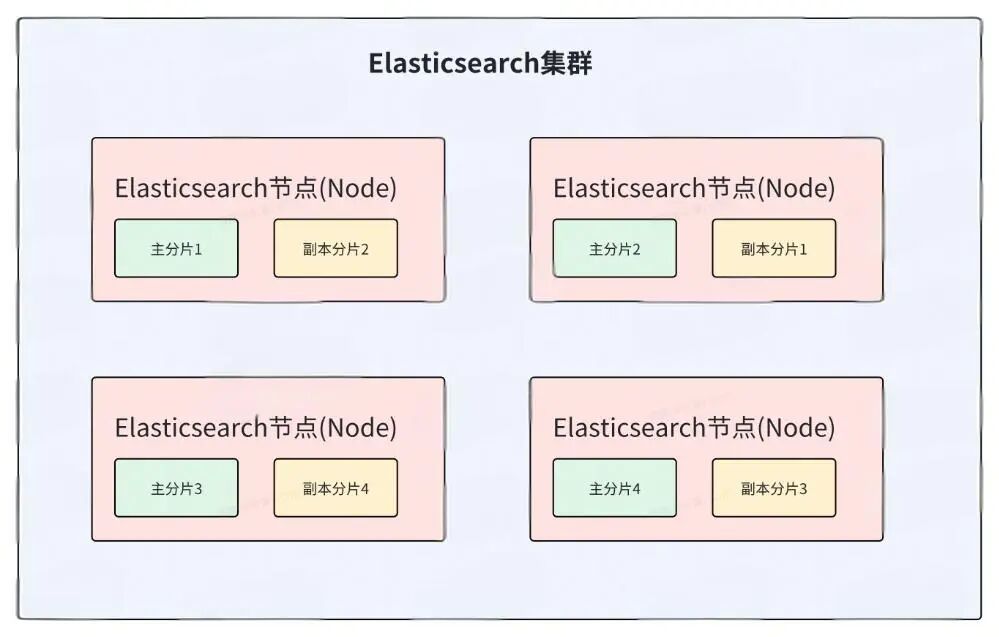
分片的功能
1. 主分片
- 数据存储与写入:所有文档通过路由算法(如
hash(_id) % number_of_primary_shards)分配到特定的主分片,由该主分片处理索引、更新、删除等写操作。
- 扩展性:通过增加节点和分布分片,实现数据的水平扩展。
- 不可变性:主分片数量在索引创建时通过
number_of_shards 参数设定,一旦创建便无法直接修改(需要重建索引或使用如重索引等迁移方案)。
2. 副本分片
- 高可用性:当某个主分片所在的节点发生故障时,其对应的一个副本分片会自动晋升为主分片,确保服务不中断、数据不丢失。
- 读取负载均衡:副本分片可以并行处理查询请求,显著提升集群的读吞吐量和性能。
- 动态调整:副本分片数量通过
number_of_replicas 参数控制,可以根据读写压力动态增加或减少。
分片数规划
我们已经了解了分片的基本概念和功能。在日常ES运维中,发现不少同学对分片数量的设置缺乏概念,常常直接照搬他人的配置,这是一种严重的误区。在实际业务中,我们必须做好分片(包括主副)数量的规划,以避免慢查询、数据倾斜、磁盘空间浪费等问题。
当索引分片数量过多时,会对ES性能产生负面影响。每个分片都需要消耗一定的内存来存储索引元数据和缓存,导致总内存占用激增。此外,当查询或写入涉及多个分片时,ES需要在节点间进行大量的数据协调和传输,增加网络开销,从而可能降低查询和写入性能。因此,分片数量的选择必须慎重。
索引在不同场景下,其分片设置策略也各不相同。下面我们从四个典型场景来探讨如何规划。
读场景
在偏重读的业务中,建议将单个分片的大小控制在20GB~40GB,并尽量减少主分片数量。这有助于降低“热点”问题。因为分片过多时,容易出现“长尾”子请求——部分子请求可能因节点异常、GC停顿或网络抖动而延迟响应,拖慢整个查询。
同时,过多的子请求并不能线性提升数据节点的请求吞吐,反而可能无法充分利用CPU。在减少主分片数的前提下,可以适当增加副本数,利用副本并行处理查询,从而有效提升整体的查询吞吐量。
写场景
在写入密集型的场景下,建议将单个分片的大小控制在10GB~20GB。较小的分片在数据写入上更有优势。小分片需要维护的Segment数量远少于大分片,在数据刷新(Refresh)落盘和段合并(Merge)时效率更高。由于数据量更少,写入时数据能更快地缓存到内存中,并通过refresh_interval参数更频繁、快速地持久化到磁盘。
日志存储场景
- 需要预估每日写入集群的总数据量,结合数据节点数量来评估索引的分片数量。
- 考虑日志存储后是否还需要进行查询和聚合分析。合理大小的分片有利于提高查询效率。
- 根据日志保留策略,采用按天、周或月滚动生成新索引的模式。并利用ILM(索引生命周期管理)策略,自动化管理日志索引的整个生命周期(热、温、冷、删除)。
- 为节约存储成本,在此类场景下建议将副本数设置为0。
小数据量索引业务场景
对于数据量很小的索引,增加分片数通常不会带来性能提升,反而可能产生负面影响。
首先,增加分片数会加大集群的管理开销,包括维护分片状态、备份恢复等。对于小数据量索引,这些开销可能超过其带来的微薄收益。
其次,分片数过多可能导致数据分布不均,影响查询性能。如果某些分片数据过少,其查询性能可能成为瓶颈。此外,跨多个分片的查询需要进行结果合并,也会增加额外耗时。
因此,对于数据量较小的索引,建议将主分片数设置为1或2,以避免不必要的开销和性能问题。如果希望提升查询性能,可以通过增加副本数、优化查询语句或引入缓存来实现。
通用场景
- 提前规划:根据业务场景预估数据总量和增长趋势,提前做好分片数量规划(切记,索引创建后主分片数无法直接修改)。
- 分片数量:参考公式:
主分片数 ≈ 总数据量 / 单分片容量上限。官方建议单分片容量在10-50GB之间,文档数最好在1亿条以内(日志场景可放宽至50-100GB)。
> 注意:平台强烈建议(或要求)将分片数设置为ES数据节点数量的整数倍,以实现更均衡的数据分布。
- 副本数量:增加副本数可以提升读性能和高可用性,但会降低写入速度(因为需要同步到更多副本)。需根据读写比例权衡。
- 时序数据:对于时序类或数据量持续增长的索引,应结合索引生命周期管理(ILM)和索引模板,采用滚动索引的方式进行管理。
- 路由选择:平台不建议使用自定义
routing值进行分片路由。默认使用文档_id即可。自定义routing容易导致数据倾斜,且ES内部需要额外的计算逻辑,在高写入场景下可能带来性能损耗。
- 控制总量:分片不是越多越好。过多的分片会加剧集群元数据管理的压力,影响整体性能。更多关于数据库与中间件的深度配置和调优讨论,可以在社区中找到。
- 分摊压力:设置
index.routing.allocation.total_shards_per_node 参数,将索引的分片压力均匀分摊到多个节点上。
- 该参数可以限制单个节点上允许存放的该索引的分片总数,有助于提高集群的可用性和稳定性,避免某个节点因负载过重而影响整个集群。
index.routing.allocation.total_shards_per_node 是一个索引级别的设置,可以在创建索引时指定,或对已有索引进行动态更新。语法如下:
PUT <index_name>/_settings
{
“index.routing.allocation.total_shards_per_node”:<number_of_shards>
}
其中,<index_name>为索引名,<number_of_shards>表示每个节点上该索引允许的最大分片数(主副分片之和)。
持续调整索分片
集群分片的调整并非一劳永逸。随着业务发展,新业务接入或原有业务规模突变,都需要我们持续关注并动态调整分片策略。
索引与资源消耗的关系
合理的索引规划不仅关乎性能,也直接影响集群的资源消耗和稳定性。
分片数量与内存消耗
每个分片都是一个独立的Lucene索引,需要维护自己的倒排索引、缓存等内存数据结构。分片数量过多会导致:
- 内存占用激增:每个分片即使数据量小,也会占用约10-30MB的固定内存(用于元数据等)。数千个分片可能轻松消耗掉数十GB内存。
- 文件句柄耗尽:集群总分片数过多会占用大量文件描述符,可能引发“too many open files”错误。
- CPU热点:分片在节点间分配不均,会导致部分节点CPU负载过高,形成性能瓶颈。
Segment碎片化
每个分片由多个Segment(段)文件组成。Segment数量过多会:
- 增加IO压力:查询时需要扫描更多的Segment文件,增加磁盘IO。
- 占用堆内存:每个Segment的元数据需要加载到堆内存中,数百万个Segment可能占用数GB的堆空间。
- 影响GC效率:频繁的Segment合并(Merge)操作会生成大量临时对象,可能触发更频繁的Full GC。
五、总结
创建一个合理的Elasticsearch索引,需要综合考量业务场景、字段类型选择、分词需求,并根据数据规模与增长趋势来确定分片与副本的数量。索引结构的合理性直接决定了集群的长期稳定性和性能表现。因此,我们应养成习惯,将索引设计作为技术方案评审的关键一环,仔细打磨,从而为线上系统的稳定运行打下坚实基础。
你在工作中遇到的ES稳定性问题或使用困惑,都欢迎到 云栈社区 与广大开发者一起探讨,寻找最佳实践。更多关于系统运维与DevOps的实战经验,也可以在社区的相关板块进行深入交流。
 发表于 2026-1-16 16:53:40
|
查看: 170|
回复: 0
发表于 2026-1-16 16:53:40
|
查看: 170|
回复: 0
