“为什么搜出来的结果总数永远是 10,000?是不是数据丢了?”
这是每一个 Elasticsearch 新手在 7.x 版本之后都会遇到的常见疑问。而在得知“这是 ES 的默认性能优化”后,绝大多数人的第一反应往往是抗拒:“我不想要优化,我要精准的数字!老板要看,前端分页也要用。”
于是,在许多项目的代码库里,我们都能看到这样一行“补丁”:
"track_total_hits": true
数字终于准了,变成了 854,321,大家都很满意。但没人注意到,就在这行代码生效的瞬间,集群的 CPU 占用率可能直接翻倍,查询延迟从 20ms 劣化到了 500ms。
为什么一个简单的“计数”,会成为拖垮集群性能的隐形杀手?今天,我们不谈玄学,从 Lucene 底层原理层面,为你揭秘这背后的代价,并分享在云栈社区中关于此类性能调优的实践讨论。
现象:消失的“尾部数据”
在 ES 7.0 之前,查询默认会算出精确总数。但在 7.0 之后,默认的响应体变成了这样:
"hits": {
"total": {
"value": 10000,
"relation": "gte" // 注意:Greater Than or Equal to (大于等于)
},
...
}
这不仅是一个数字的变化,更是搜索引擎检索逻辑的根本性范式转移:从“找出所有匹配文档”进化为“只找出最有价值的 Top N”。
深度解析:Block-Max WAND 算法的智慧
要理解为什么“数不准”能带来性能飞跃,必须深入 Lucene 的底层,了解 Block-Max WAND (BMW) 算法。
1. 倒排索引的物理结构:Block
在 Lucene 的倒排索引(Inverted Index)中,一个 Term(词项)对应的 Postings List(文档 ID 列表)并不是一整条长链,而是被切分成了多个 Block(块) ,通常包含 128 个文档 ID。
关键点在于:每个 Block 都有一个 Block Header,里面记录了这个块的元数据,其中最重要的一个是:Max Score(块内最大分数):即这个 Block 里所有文档中,能产生的最高相关性得分是多少。
2. 竞速机制:Min Competitive Score
当 ES 执行查询(比如查询“手机”)并索要 Top 10 结果时,它会维护一个 最小竞争分数(Min Competitive Score)。
- 刚开始,Top 10 没满,最小竞争分数是 0。
- 随着扫描进行,找到了 10 个文档,第 10 名的分数是 5.0。
- 此时,最小竞争分数变成了 5.0。意味着:任何分数低于 5.0 的文档,连进决赛圈的资格都没有。
3. “隔山打牛”的跳跃优化
接下来,神奇的事情发生了。当遍历指针来到下一个 Block(假设包含 ID 1000-1127)时,算法不需要解压这个 Block,也不需要计算具体的文档分数,而是直接看 Block Header:
算法拷问: “这个 Block 的 Max Score 是多少?”
Block 回答: “最高只能得 4.5 分。”
算法判断: “现在的门槛(Min Competitive Score)已经是 5.0 了。你这个 Block 里的文档全是低分文档,整个 Block 直接跳过!”
结果: ES 可能直接跳过了数百万个低分文档。
代价: 因为跳过了,ES 根本不知道刚才那个 Block 里有几个文档匹配(虽然分低,但确实匹配)。所以,它无法给出精确的总数。
隐形陷阱:为什么关了 track_total_hits 依然慢?
你以为把 track_total_hits 设为 false 就万事大吉了?别天真了。在某些特定场景下,即使你显式关闭了计数,ES 依然无法使用 Block-Max WAND 进行剪枝,查询性能依然会很差。
这就好比你告诉司机“不用数路边有几棵树(不计数)”,但你同时又下令“把路边每棵树的叶子都摘一片下来(聚合)”。司机虽然不用数数,但他依然得停在每一棵树下。
1. 聚合(Aggregations):WAND 的天敌
WAND 算法的核心奥义是 “Skipping(跳过)”。而 聚合(Aggregations) 的核心诉求是 “Traversing(遍历)”。
如果你在查询中包含任何聚合(例如 terms、avg、date_histogram),ES 必须访问所有匹配的文档来计算统计值。
- 冲突点:你不能跳过一个 Block,因为那个被跳过的 Block 里可能包含聚合所需的数据。
- 结果:WAND 优化被迫关闭,全量扫描不可避免。
2. 排序与分数的纠结(Sort + track_scores)
Block-Max WAND 依赖于 Max Score 来进行跳跃。
- 场景:你按时间排序 (
sort: [{"timestamp": "desc"}])。
- 陷阱:如果你手滑加了
track_scores: true(或者某些 Client 默认开启)。
- 后果:虽然是按时间排序,但因为你强行索要
_score,ES 必须对每个文档计算分数,导致无法利用 BKD Tree 的索引顺序进行快速跳跃,也难以通过 WAND 进行分数剪枝(因为排序不是按分数排的)。
代价:track_total_hits 如何摧毁性能
口说无凭,数据为证。我们在 Serverless 8.17 环境下,创建一个6分片1副本的索引,写入约 2 亿条 脱敏文档,总计约30G数据,查询qps控制在30 。用实测结果向你展示——track_total_hits 取不同值时的CU消耗及响应时长:
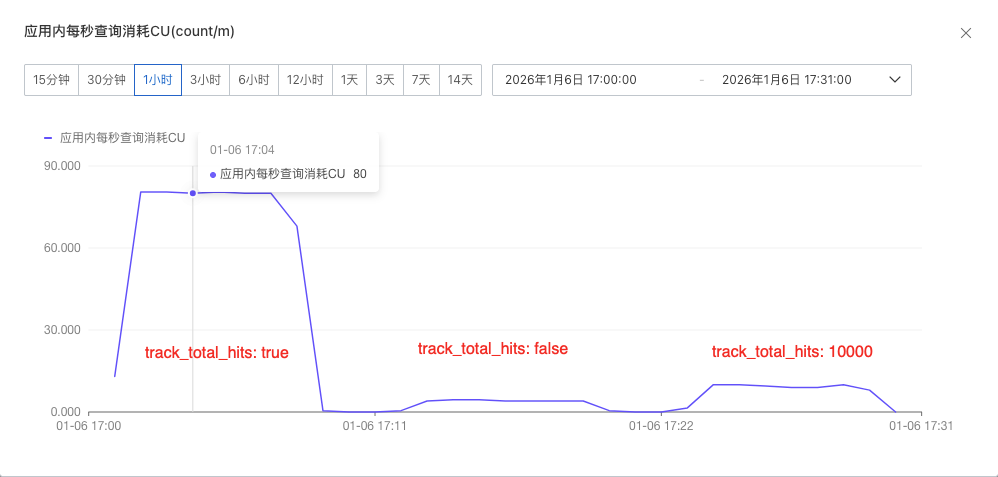
CPU 资源消耗对比(true,false,10000)
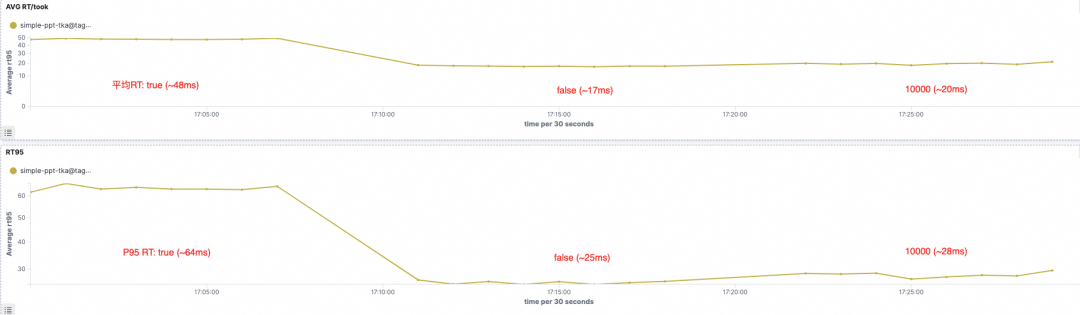
平均耗时和 P95 耗时对比(true,false,10000)
当你加上 "track_total_hits": true 时,你实际上是在对底层引擎下达一道“死命令”:“禁用 Block-Max WAND 优化,禁止跳过任何一个 Block。”这带来的性能崩塌是显著的。
1. CPU 的燃烧(计算密集)
- 优化模式:只解压和计算高分 Block。
- 强制计数:必须 解压所有 匹配的 Block(使用 Frame Of Reference 编码),并对 每一个 文档 ID 进行解码和比对。
- 量级差异:如果查询匹配 1 亿条数据,原本只需计算 Top 1000 的分数,现在必须计算 1 亿次。CPU 消耗可能增加几个数量级。
2. I/O 的雪崩(访存密集)
- 优化模式:低分 Block(通常是历史冷数据)直接跳过,不需要从磁盘读取。
- 强制计数:强制读取所有 Block。
- 后果:这会导致大量的 随机 I/O。更致命的是,这些本该沉睡的冷数据被加载到内存中,会 污染 Page Cache,把真正热点的数据(比如最近 5 分钟的日志)挤出去。
- 现象:你会发现,为了查一个总数,整个集群的写入性能和热查询性能都下降了。
决策矩阵:到底什么时候该用?
我们需要建立一个清晰的决策标准,而不是盲目地设为 true。
| 场景 |
track_total_hits 设置 |
理由 |
| C 端搜索 / App 列表 |
false 或 10000(默认) |
用户只翻前几页。显示“10,000+”完全满足体验,性能最优。 |
| 高频业务接口 (QPS > 100) |
false |
绝对禁止开启。高并发下开启全量计数是集群雪崩的导火索。 |
| 后台管理 / 审核列表 |
true(慎用) |
运营人员并发低,且必须知道确切的“待办数量”。 |
| 数据大盘 / 趋势图 |
false(使用聚合) |
不要用 hits.total 画图!请使用 date_histogram 或 cardinality 聚合。 |
| 数据导出 |
false |
导出任务应使用 Scroll API 或 Point in Time (PIT) API,这些 API 针对全量遍历做了优化,不需要实时计算总数。 |
Serverless 下的治理之道
在自建集群中,很难限制开发者的代码行为。但在 阿里云 ES Serverless 中,可以通过配置进行防御性治理。
1. 软限制:"Track Total Hits上限"
你可以通过 ES Serverless 控制台—开启功能设置,给查询加上一道“保护锁”:
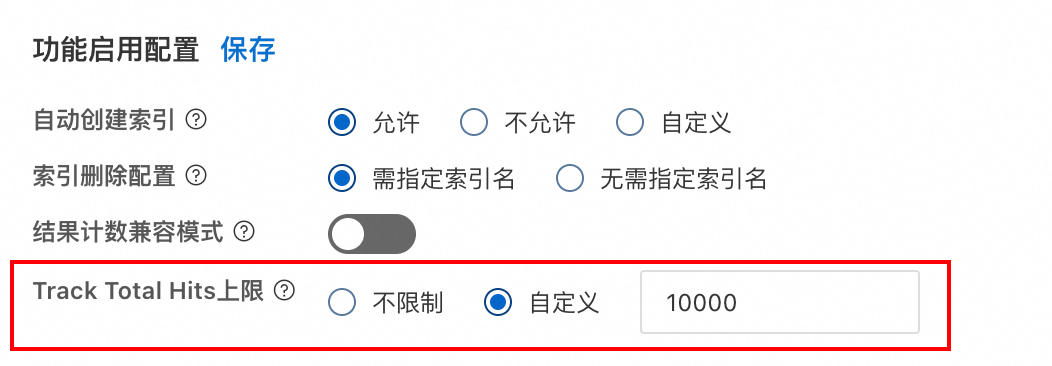
- 效果:一旦设置,即使客户端请求中带了
"track_total_hits": true,服务端也会 强制忽略,只计算到 10,000。
- 价值:从根源上防止了某个实习生的一行代码搞挂整个生产集群。
2. 拥抱“模糊的正确”
在云原生时代,算力是按量计费的(CU)。“无意义的精确计数” = “直接烧钱”。利用 Serverless 的弹性与治理能力,将算力集中在真正产生业务价值的 Top N 搜索上,才是降本增效的关键。
附录:代码与实操
1. 正确的查询姿势 (DSL)
场景 A:只要 Top 10 (性能最快)
GET /logs/_search
{
"query": { "match": { "message": "error" } },
"size": 10,
"track_total_hits": false // 显式关闭,连 10000 都不数,最快
}
场景 B:需要精确计数 (Java Client)
SearchRequest searchRequest = new SearchRequest("logs");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.matchQuery("message", "error"));
// ⚠️ 警告:仅在必要时开启,注意性能损耗
sourceBuilder.trackTotalHits(true);
// 或者设置一个具体的上限,例如 5万
// sourceBuilder.trackTotalHitsUpTo(50000);
searchRequest.source(sourceBuilder);
2. 高效替代方案:Cardinality 聚合
如果你只是想知道“大概有多少条日志”,不要用 track_total_hits,请用 HyperLogLog 算法:
GET /logs/_search
{
"size": 0,
"aggs": {
"total_count_approx": {
"cardinality": {
"field": "_id", // 或者其他高基数主键
"precision_threshold": 10000
}
}
}
}
- 优点:性能极快,内存占用极低。
- 缺点:有约 5% 以内的误差。

 发表于 2026-1-25 22:47:46
|
查看: 190|
回复: 0
发表于 2026-1-25 22:47:46
|
查看: 190|
回复: 0
