排查Linux网络问题时,你是否经历过“网卡流量异常但应用层无数据”,或是“网络延迟突增却找不到根源”的困境?这些问题的症结,往往深埋在数据包从网卡到内核的传输链路中。作为连接硬件与应用的核心桥梁,Linux协议栈管理着数据包接收、解析与转发的全过程。从数据链路层的帧校验,到网络层的路由决策,再到传输层的端口分发,每一步都深刻影响着网络的稳定性与性能。
许多开发者对应用层接口较为熟悉,但对内核中“数据如何穿越协议栈”的细节了解有限,导致问题排查时往往只能盲目调整参数。本文将深入解析数据包从物理网卡进入内核,直至交付给应用程序的完整路径,拆解协议栈各层的核心处理逻辑,并探讨性能优化的关键点,帮助你建立清晰的技术链路认知,为精准定位网络问题、优化传输性能奠定坚实基础。
一、Linux协议栈基础架构
1.1 协议栈分层架构解析
Linux协议栈是操作系统内核中实现网络通信的核心组件,它遵循经典的TCP/IP参考模型,将复杂的网络功能清晰地划分为四个逻辑层次,各司其职,协同工作。
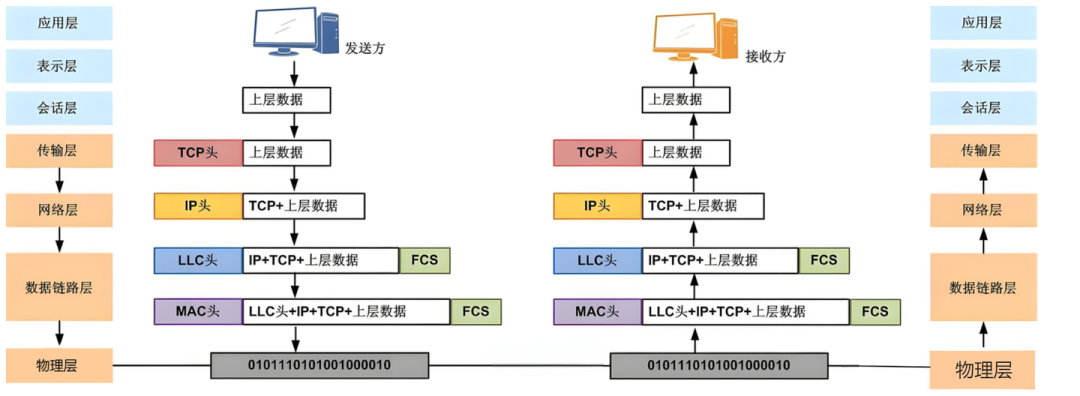
数据链路层是网络通信的起点,负责物理网络帧的封装与解析。常见的以太网(Ethernet)协议工作在局域网内,通过MAC地址寻址,确保数据帧准确送达目标设备。该层还会进行CRC(循环冗余校验)等操作,以保障数据的完整性。
网络层以IP协议为核心,扮演着“网络交通指挥员”的角色。其主要任务是路由寻址,根据目标IP地址为数据包规划最佳路径。此外,它还负责数据包的分片与重组(当数据大小超过链路MTU时),并支持IPv4与IPv6双栈协议。ICMP协议作为其辅助,用于反馈网络状态与控制信息。
传输层提供端到端的通信服务。TCP协议实现了面向连接的可靠传输,包含流量控制、拥塞控制等复杂机制,确保数据有序、无误地送达。UDP协议则提供无连接的快速传输服务,牺牲部分可靠性以换取更低的延迟,适用于实时性要求高的场景。
应用层通过Socket接口为上层应用程序(如HTTP、FTP)提供服务。它屏蔽了下层协议的复杂细节,使开发者能够专注于业务逻辑的实现。深入了解Linux系统的底层网络机制,是进行高效网络编程和运维的基础。
1.2 协议栈的核心作用
Linux协议栈作为连接硬件与应用的桥梁,主要承担三大核心功能:
- 协议适配:它统一了不同网络硬件(如以太网卡、Wi-Fi模块)的交互接口。无论底层硬件如何差异,协议栈都能提供标准化的处理流程,极大提高了系统的兼容性与可扩展性。
- 数据处理:它完成了数据在各协议层间的封装与解封装。数据发送时,自上而下逐层添加协议头(如TCP头、IP头、以太网头);数据接收时,则自下而上逐层剥离并解析这些头部信息,实现跨层的信息传递与正确交付。
- 资源管理:它负责调度网络带宽、内核缓冲区(如
sk_buff)等关键资源。在多任务并发通信的场景下,协议栈需要合理分配资源,避免某个应用独占带宽或耗尽缓冲区,保障整个系统网络通信的高效与稳定。
1.3 数据包接收处理流程示例
以接收一个数据包为例,其在内核中的完整旅程可概括为以下关键步骤:
- DMA写入:网卡通过DMA(直接内存访问)技术,将接收到的数据包直接写入内核预分配的缓冲区(
sk_buff),无需CPU干预,完成后触发硬件中断(IRQ)。
- 中断处理:CPU响应中断,调用网卡驱动的中断处理程序。该程序通常只做最少的工作(如禁用网卡中断、调度软中断),便将数据包交由
NET_RX_SOFTIRQ类型的软中断进行延迟处理,以快速释放CPU。
- 协议栈解析:在软中断上下文中,协议栈开始逐层处理数据包:
- 数据链路层:校验帧的合法性(长度、CRC等)。
- 网络层:解析IP头部,检查校验和,进行路由决策(判断是发给本机还是需要转发)。
- 传输层:解析TCP/UDP头部,根据端口号查找对应的Socket,并维护连接状态(如TCP的序列号、滑动窗口)。
- 交付应用:协议栈处理完毕后,数据包从内核空间拷贝至用户空间的应用程序缓冲区,最终通过
recv()等系统调用返回给应用程序。
这一流程中,中断响应、协议栈解析与内存拷贝是主要的耗时环节,也是性能优化的核心切入点。以下是一个简化的C++模拟代码,展示了这一流程的核心逻辑:
#include <iostream>
#include <cstdint>
#include <vector>
#include <queue>
#include <mutex>
#include <condition_variable>
#include <thread>
#include <cstring>
// 网络常量定义
const uint32_t PACKET_BUFFER_SIZE = 1500; // 以太网MTU:1500字节
const uint32_t MAX_QUEUE_SIZE = 1024; // 软中断队列最大长度
// 数据包结构体
struct Packet {
uint8_t data[PACKET_BUFFER_SIZE];
uint32_t length;
uint32_t dst_ip; // 目的IP地址(网络字节序)
uint16_t dst_port; // 目的端口
uint8_t proto; // 传输层协议(TCP=6,UDP=17)
Packet() : length(0), dst_ip(0), dst_port(0), proto(0) {
memset(data, 0, PACKET_BUFFER_SIZE);
}
};
// 内核缓冲区
struct KernelBuffer {
std::queue<Packet> buffer;
std::mutex mtx;
std::condition_variable cv;
} kernel_buf;
// 软中断队列(NET_RX类型)
struct SoftirqQueue {
std::queue<Packet> queue;
std::mutex mtx;
std::condition_variable cv;
bool stop = false;
} net_rx_queue;
// 应用程序缓冲区
struct AppBuffer {
std::queue<Packet> buffer;
std::mutex mtx;
std::condition_variable cv;
} app_buf;
// 1. 网卡DMA操作:直接写入内核缓冲区
void nic_dma_write(const uint8_t* raw_data, uint32_t len) {
std::lock_guard<std::mutex> lock(kernel_buf.mtx);
Packet pkt;
memcpy(pkt.data, raw_data, len);
pkt.length = len;
kernel_buf.buffer.push(pkt);
std::cout << "[DMA] 数据包写入内核缓冲区,长度:" << len << "字节" << std::endl;
kernel_buf.cv.notify_one();
}
// 2. 硬件中断处理:触发软中断延迟处理
void nic_irq_handler() {
std::unique_lock<std::mutex> lock(kernel_buf.mtx);
kernel_buf.cv.wait(lock, []() { return !kernel_buf.buffer.empty(); });
Packet pkt = kernel_buf.buffer.front();
kernel_buf.buffer.pop();
lock.unlock();
std::lock_guard<std::mutex> irq_lock(net_rx_queue.mtx);
net_rx_queue.queue.push(pkt);
std::cout << "[硬中断IRQ] 响应网卡中断,数据包移交软中断NET_RX队列" << std::endl;
net_rx_queue.cv.notify_one();
}
// 3. 软中断处理:协议栈解析
void net_rx_softirq_handler() {
while (true) {
std::unique_lock<std::mutex> lock(net_rx_queue.mtx);
net_rx_queue.cv.wait(lock, []() { return !net_rx_queue.queue.empty() || net_rx_queue.stop; });
if (net_rx_queue.stop && net_rx_queue.queue.empty()) break;
Packet pkt = net_rx_queue.queue.front();
net_rx_queue.queue.pop();
lock.unlock();
std::cout << "[软中断NET_RX] 开始协议栈解析数据包" << std::endl;
// 3.1 数据链路层:简化版帧长度校验
if (pkt.length < 14) { // 以太网帧头至少14字节
std::cerr << "[数据链路层] 帧长度非法,丢弃数据包" << std::endl;
continue;
}
std::cout << "[数据链路层] 帧校验通过" << std::endl;
// 3.2 网络层:简化版IP地址解析
pkt.dst_ip = *(uint32_t*)(pkt.data + 30); // IPv4头中目的IP偏移
std::cout << "[网络层] 解析目的IP:" << ((pkt.dst_ip >> 24) & 0xFF) << "."
<< ((pkt.dst_ip >> 16) & 0xFF) << "."
<< ((pkt.dst_ip >> 8) & 0xFF) << "."
<< (pkt.dst_ip & 0xFF) << std::endl;
// 3.3 传输层:解析端口与协议
pkt.proto = *(uint8_t*)(pkt.data + 23); // IPv4协议字段
if (pkt.proto == 6) { // TCP
pkt.dst_port = *(uint16_t*)(pkt.data + 42); // TCP目的端口偏移
std::cout << "[传输层] 解析TCP目的端口:" << ntohs(pkt.dst_port) << std::endl;
} else if (pkt.proto == 17) { // UDP
pkt.dst_port = *(uint16_t*)(pkt.data + 42); // UDP目的端口偏移
std::cout << "[传输层] 解析UDP目的端口:" << ntohs(pkt.dst_port) << std::endl;
} else {
std::cerr << "[传输层] 不支持的协议类型,丢弃数据包" << std::endl;
continue;
}
// 4. 内存拷贝:内核缓冲区 -> 应用缓冲区
std::lock_guard<std::mutex> app_lock(app_buf.mtx);
app_buf.buffer.push(pkt);
std::cout << "[内存拷贝] 数据包从内核缓冲区拷贝至应用缓冲区,长度:" << pkt.length << "字节" << std::endl;
app_buf.cv.notify_one();
}
}
// 5. 应用程序:通过Socket接口读取
void app_socket_read() {
while (true) {
std::unique_lock<std::mutex> lock(app_buf.mtx);
app_buf.cv.wait(lock, []() { return !app_buf.buffer.empty(); });
Packet pkt = app_buf.buffer.front();
app_buf.buffer.pop();
lock.unlock();
std::cout << "[应用程序] 通过Socket接口接收数据包,目的IP:" << ((pkt.dst_ip >> 24) & 0xFF) << "."
<< ((pkt.dst_ip >> 16) & 0xFF) << "."
<< ((pkt.dst_ip >> 8) & 0xFF) << "."
<< (pkt.dst_ip & 0xFF) << ",目的端口:" << ntohs(pkt.dst_port) << std::endl;
std::cout << "===================================== 数据包处理完成 =====================================" << std::endl;
break; // 简化演示,只处理一个包
}
}
// 模拟生成测试数据包
void generate_test_packet(uint8_t* data, uint32_t& len) {
len = 100;
memset(data, 0, len);
// 填充以太网帧头(14字节)
data[12] = 0x08; data[13] = 0x00; // 类型:IPv4
// 填充IPv4头
data[14] = 0x45; // 版本+头部长度
data[23] = 0x06; // 协议:TCP
*(uint32_t*)(data + 30) = htonl(0xc0a80101); // 目的IP:192.168.1.1
// 填充TCP头
*(uint16_t*)(data + 42) = htons(80); // 目的端口:80
}
int main() {
std::thread softirq_thread(net_rx_softirq_handler);
std::thread app_thread(app_socket_read);
uint8_t test_data[PACKET_BUFFER_SIZE];
uint32_t pkt_len;
generate_test_packet(test_data, pkt_len);
nic_dma_write(test_data, pkt_len); // 1. DMA写入
nic_irq_handler(); // 2. 触发硬件中断
app_thread.join();
{
std::lock_guard<std::mutex> lock(net_rx_queue.mtx);
net_rx_queue.stop = true;
net_rx_queue.cv.notify_one();
}
softirq_thread.join();
return 0;
}
二、数据包的完整旅程:发送与接收
2.1 发送流程:自上而下的封装
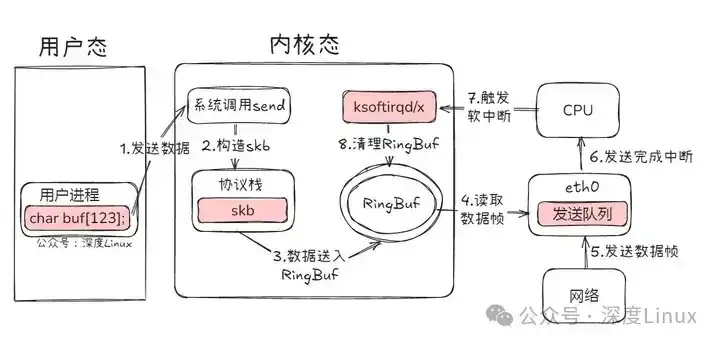
数据包的发送是一个逐层封装的过程,始于应用程序,终于物理网卡。
- 应用层调用:应用程序通过
send()或write()等系统调用,将数据写入对应的Socket缓冲区。
- 传输层处理:
- TCP:将应用数据按MSS(最大报文段长度)分割成多个段(Segment),为每个段添加TCP头部(包含源/目的端口、序列号、确认号、窗口大小等)。
- UDP:为整个数据报添加一个简单的8字节UDP头部(包含源/目的端口、长度、校验和)。
- 网络层处理:接收来自传输层的段或数据报,添加IP头部(包含源/目的IP地址、TTL、协议号等)。根据目标IP地址查询路由表,确定下一跳地址。如果数据包大小超过出口链路的MTU,则进行IP分片。
- 数据链路层处理:添加数据链路层头部(如以太网头部,包含源/目的MAC地址、帧类型)。通常需要通过ARP协议获取下一跳IP地址对应的MAC地址。最后添加帧尾(如CRC校验码)。
- 物理层发送:网卡驱动将封装好的帧放入发送队列,由网卡硬件将其转换为电信号或光信号发送到物理链路上。
一个简单的C++ Socket发送示例:
#include <sys/socket.h>
#include <arpa/inet.h>
#include <cstring>
#include <iostream>
#include <unistd.h>
int main() {
int sock = socket(AF_INET, SOCK_STREAM, 0);
if (sock == -1) {
std::cerr << "Socket creation failed" << std::endl;
return 1;
}
sockaddr_in server_addr;
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(80);
if (inet_pton(AF_INET, "192.168.1.100", &server_addr.sin_addr) <= 0) {
std::cerr << "Invalid address" << std::endl;
close(sock);
return 1;
}
if (connect(sock, (struct sockaddr*)&server_addr, sizeof(server_addr)) == -1) {
std::cerr << "Connection failed" << std::endl;
close(sock);
return 1;
}
const char* data = "Hello, Server!";
ssize_t sent_bytes = send(sock, data, strlen(data), 0);
if (sent_bytes == -1) {
std::cerr << "Send failed" << std::endl;
} else {
std::cout << "Sent " << sent_bytes << " bytes" << std::endl;
}
close(sock);
return 0;
}
2.2 接收流程:自下而上的解封装
接收流程是发送流程的逆过程,但引入了中断、软中断等异步处理机制。
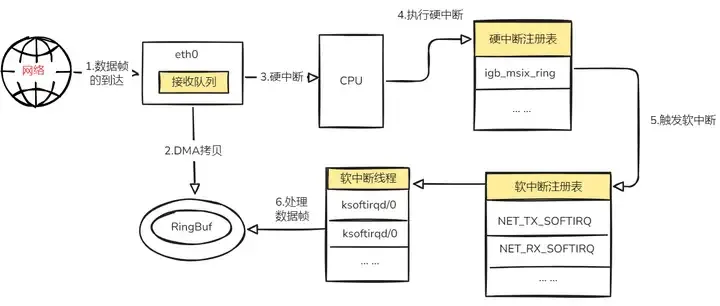
- 网卡接收与DMA:网卡从物理链路接收到信号,将其还原为数据帧,并通过DMA直接写入内核驱动预分配的接收环形缓冲区(ring buffer)。
- 硬中断与软中断调度:网卡产生硬件中断(IRQ),CPU响应中断,执行网卡驱动的中断处理程序。该程序通常只是记录一个标志,然后触发一个
NET_RX_SOFTIRQ软中断,随后退出。这样避免了CPU长时间处于中断上下文。
- 软中断处理(协议栈入口):内核在合适的时机(如中断返回前、
ksoftirqd内核线程)处理软中断。NET_RX_SOFTIRQ的处理函数从环形缓冲区中取出数据帧,并为其分配一个sk_buff结构,开始协议栈的解封装。
- 协议栈逐层处理:
- 数据链路层:校验帧的CRC,检查帧长度,解析帧类型(如0x0800表示IPv4),剥离链路层头部。
- 网络层:校验IP头部校验和,检查目标IP是否为本机(是则上传,否则根据路由表转发),处理IP分片重组,剥离IP头部。
- 传输层:根据IP头中的协议字段(6为TCP,17为UDP)调用相应的处理函数。校验传输层头部,根据目标端口号找到对应的Socket,并将数据放入该Socket的接收缓冲区。对于TCP,还需处理序列号、确认、滑动窗口等复杂状态。
- 应用层读取:应用程序调用
recv()或read()时,数据从Socket接收缓冲区拷贝到用户态缓冲区,系统调用返回。
三、内核核心数据结构与性能机制
3.1 核心数据结构:sk_buff 与 net_device
sk_buff(socket buffer):这是Linux网络子系统中最重要的数据结构,代表一个数据包在内核中的存在形式。它是一个复杂的结构体,关键特性包括:
- 灵活的数据区管理:通过
head, data, tail, end四个指针,可以在不移动数据的情况下,在头部添加或删除协议头(使用skb_push/skb_pull),或在尾部添加数据(skb_put)。这高效支持了协议栈的封装/解封装操作。
- 分层头部指针:包含
mac_header, network_header, transport_header等指针,直接指向各层协议头在数据区中的位置,避免了协议处理时重复计算偏移量。
- 引用计数与克隆:
users字段作为引用计数,支持多个地方同时持有同一个sk_buff的引用(如多个网卡需要转发同一数据包时)。cloned标志指示该缓冲区是否为克隆副本,用于实现写时复制(Copy-On-Write),优化内存使用。
net_device:代表一个网络接口的抽象。它包含了网络设备的所有信息:
- 设备信息:名称(eth0)、MAC地址、MTU、接口状态(up/down)。
- 操作函数集:指向驱动实现的函数指针,如
ndo_start_xmit(发送数据包)、ndo_open(打开设备)、ndo_stop(关闭设备)。
- 统计信息:收发包计数、错误计数等。
- NAPI相关字段:如轮询列表、权重等,用于支持NAPI混合中断与轮询的机制。
3.2 关键性能机制
- 中断与软中断:为了避免高流量下频繁的硬件中断导致CPU效率低下(“活锁”),Linux将网络处理分为两阶段。硬中断只做最紧急的工作(如调度软中断),耗时的协议栈处理在软中断上下文中进行。软中断可以被其他中断抢占,但也可能被
ksoftirqd内核线程接管,防止其饿死用户进程。
- NAPI(New API):这是对传统中断模型的优化,适用于高速网卡。在NAPI模式下,当第一个数据包到达触发中断后,驱动会关闭中断,并将设备加入一个轮询列表。内核在软中断中轮询该列表上的所有设备,批量处理它们的数据包,直到处理完毕或达到时间/数量预算,才重新开启中断。这在高包速率下显著减少了中断次数,提升了吞吐量。
- 零拷贝(Zero-copy)技术:
- sendfile 系统调用:在文件服务器场景中,
sendfile()可以直接将文件内容从磁盘(页缓存)通过DMA拷贝到网卡缓冲区,避免数据在内核空间和用户空间之间的来回拷贝。
- TCP_CORK / MSG_MORE:这些Socket选项允许应用将多个小的
write()调用合并成一个大的数据包发送,减少协议栈头部开销和系统调用次数。
- 用户态协议栈与DPDK:这属于更激进的优化,完全绕过内核协议栈,由用户态程序直接操作网卡。但这需要专用的驱动和重写网络逻辑,复杂度极高,常用于对性能有极致要求的场景(如电信核心网)。
深入理解这些机制,对于从事Linux运维和DevOps工作,特别是处理高并发网络服务时至关重要。
四、实战:网络排查与内核调试
4.1 抓包与协议分析工具
- tcpdump:命令行抓包利器,语法强大,适合在服务器上快速捕获和分析。
- 示例:
tcpdump -i eth0 -n 'tcp port 80 and host 192.168.1.1' 捕获eth0上与192.168.1.1之间端口80的TCP流量。
- Wireshark:图形化工具,提供强大的协议解码和统计分析功能,适合深度分析复杂问题。
- 基于eBPF的现代工具(bcc/bpftrace):可以在内核中动态插入追踪点,以极低的开销获取深层信息,例如追踪
sk_buff的分配/释放、特定内核函数的调用延时等。eBPF技术正在成为Linux可观测性领域的核心。
4.2 内核调试与状态查看
- 网络状态统计:
netstat -s 或 nstat:查看各协议层(IP、TCP、UDP等)的全局统计信息,如重传数、错误数。ss -tanp:查看当前所有TCP连接的状态、进程信息,比传统的netstat更快速、信息更全。
- 网卡与驱动信息:
ethtool -S eth0:查看指定网卡的详细硬件统计信息(各队列收发包、丢包等)。ethtool -k eth0:查看和修改网卡的特性参数(如是否开启GRO、TSO等卸载功能)。
- 内核追踪:
perf trace:可以追踪系统调用和部分内核函数的调用链,帮助定位延迟。trace-cmd / ftrace:Linux内核内置的追踪框架,可以跟踪内核函数调用、调度事件等。
4.3 典型故障分析:TCP三次握手失败(SYN重传)
当客户端发送SYN包后迟迟收不到SYN-ACK应答,会触发SYN重传。使用tcpdump抓包可观察到这一现象。排查思路如下:
- 检查连通性:使用
ping检查基础IP层连通性。
- 检查对端状态:对端服务是否监听(
netstat -tlnp),防火墙是否放行(iptables -L -n)。
- 检查内核参数:
net.ipv4.tcp_syn_retries:控制SYN包的重试次数。net.ipv4.tcp_max_syn_backlog:半连接队列(SYN_RECV状态)的最大长度。如果服务器瞬间收到大量SYN而来不及处理,新到的SYN会被丢弃。net.ipv4.tcp_syncookies:一种防御SYN Flood攻击的机制,在队列满时启用。
- 使用内核调试工具:通过
dropwatch或perf监控内核丢包点,确认SYN包是在协议栈的哪个环节被丢弃。
以下是一个模拟的排查脚本示例,展示了检查内核参数和系统日志的思路:
#include <iostream>
#include <fstream>
#include <string>
#include <cstdlib>
const std::string TCP_SYN_RETRIES_PATH = "/proc/sys/net/ipv4/tcp_syn_retries";
int read_tcp_syn_retries() {
std::ifstream config_file(TCP_SYN_RETRIES_PATH);
if (!config_file.is_open()) {
std::cerr << "无法读取tcp_syn_retries配置" << std::endl;
return -1;
}
int retries;
config_file >> retries;
config_file.close();
std::cout << "当前内核 tcp_syn_retries 配置值: " << retries << std::endl;
return retries;
}
bool check_connectivity(const std::string& target_ip) {
std::string command = "ping -c 2 -W 1 " + target_ip + " > /dev/null 2>&1";
int ret = system(command.c_str());
if (ret == 0) {
std::cout << "连通性检查: 可以ping通 " << target_ip << std::endl;
return true;
} else {
std::cout << "连通性检查: 无法ping通 " << target_ip << ",请检查网络或防火墙" << std::endl;
return false;
}
}
int main() {
std::string target_server = "192.168.1.100";
std::cout << "=== TCP SYN重传问题排查 ===" << std::endl;
// 步骤1:检查基础连通性
if (!check_connectivity(target_server)) {
return 1;
}
// 步骤2:检查内核SYN重传配置
int retries = read_tcp_syn_retries();
if (retries < 5) {
std::cout << "提示:当前tcp_syn_retries(" << retries << ") 较低,在网络延迟大时可能易导致连接失败。"
<< "可考虑临时调整: echo 6 > " << TCP_SYN_RETRIES_PATH << " (需root权限)" << std::endl;
}
// 步骤3:建议进行抓包分析
std::cout << "\n建议进行抓包以获取确切信息:" << std::endl;
std::cout << "客户端执行: sudo tcpdump -i any 'host " << target_server << " and tcp port 目标端口号'" << std::endl;
std::cout << "观察是否有SYN包发出,以及对端是否有SYN-ACK响应。" << std::endl;
std::cout << "\n排查流程结束。" << std::endl;
return 0;
}
通过将理论(协议栈分层、数据结构)与实践(工具使用、故障排查)相结合,我们能够系统性地理解Linux网络的工作原理,并具备定位和解决复杂网络问题的能力。持续关注云原生领域的新工具(如基于eBPF的Cilium、Katran等),也能帮助我们应对容器化、微服务架构下的新型网络挑战。
 发表于 2025-12-17 02:28:10
|
查看: 174|
回复: 0
发表于 2025-12-17 02:28:10
|
查看: 174|
回复: 0
