
微软近日开源了VibeVoice模型,它能够在64K的上下文窗口中,合成长达90分钟且最多包含4名说话人的语音。其生成的语音音色丰富、语调自然,并能有效模拟真实的对话氛围。目前,「VibeVoice-Realtime TTS:实时语音合成服务」的教程已上线HyperAI官网(hyper.ai),可供开发者便捷体验。
当前,文本转语音(TTS)技术已在为单说话人生成高保真、自然的短语音方面取得显著进展。然而,在面向播客、多角色有声书等场景时,如何可扩展地合成高质量的长格式、多说话人对话音频,仍然是业界面临的主要挑战。
传统方法通常将独立合成的语句进行拼接,但这难以实现自然的对话轮转和基于上下文的内容生成。尽管已有一些针对多说话人长会话语音生成的研究,但它们大多未开源,或在生成音频的长度与稳定性上存在局限。
为此,微软推出了开源的VibeVoice,旨在攻克可扩展的长格式、多说话人语音合成难题。该模型采用基于下一token扩散(next-token diffusion)的方法来合成语音,这是一种通过扩散自回归生成潜在向量以建模连续数据的统一框架。
研究团队为此首创了一种新颖的连续语音分词器。与当前流行的Encodec模型相比,它在保持相近性能的前提下,将数据压缩效率提升了80倍,实现了高达3200倍的压缩率(对应7.5 Hz帧率)。这大幅提升了处理长序列时的计算效率,同时保障了音频的保真度。
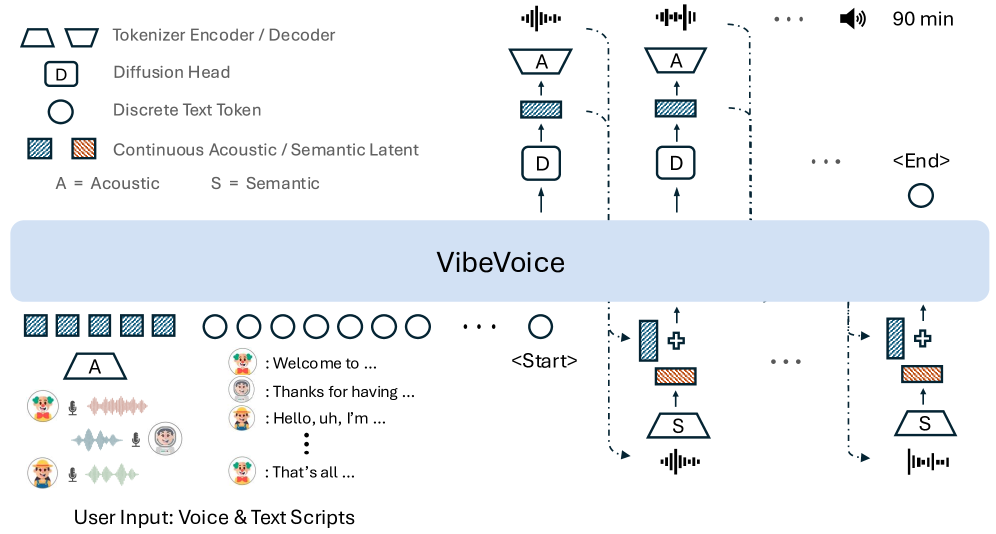
尽管架构简洁,VibeVoice却展现出强大的能力。它不仅能在长上下文中生成包含多角色的超长语音,其音色、语调也更趋自然,并能捕捉对话的动态氛围。在跨语言应用中,它也表现出较强的迁移能力,综合性能据称已超越现有的开源与专有对话模型。

为了直观感受其效果,我们使用VibeVoice生成了了一段时长约1分20秒的新年祝福音频。生成结果明显摆脱了单一的“机械音”,呈现出饱满、有层次的音色,并具备一定的情绪张力,听起来亲切而生动。
「VibeVoice-Realtime TTS:实时语音合成服务」的教程已上线,您可以通过HyperAI平台一键部署并体验。这为研究者和开发者快速尝试前沿的人工智能语音合成技术提供了便利。
Demo 运行步骤
- 访问 hyper.ai 首页,在教程版块找到并选择「VibeVoice-Realtime TTS:实时语音合成服务」,然后点击「在线运行此教程」。
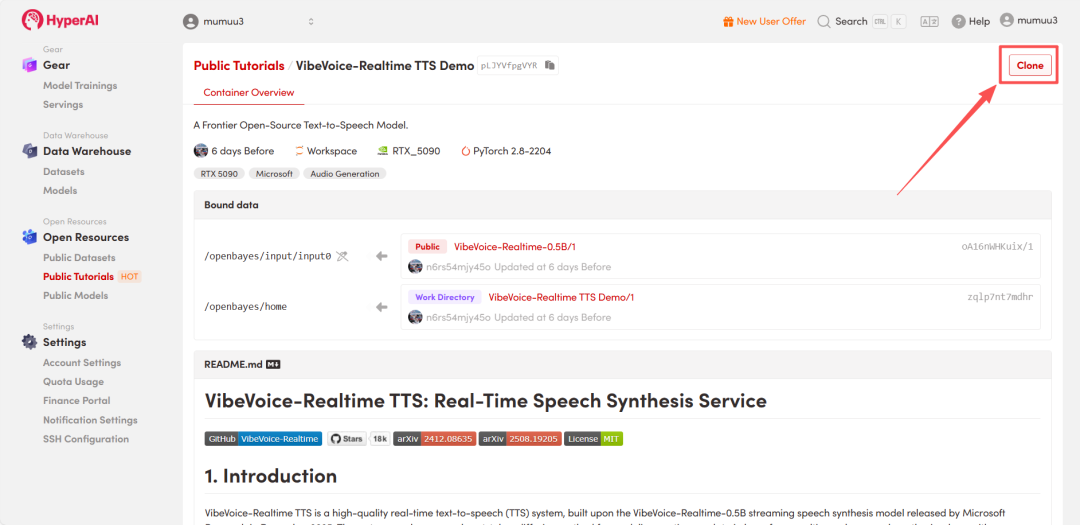
- 页面跳转后,点击右上角的「Clone」按钮,将该教程克隆至自己的容器中。
注:页面右上角支持切换中/英文语言界面,本教程以英文界面为例。
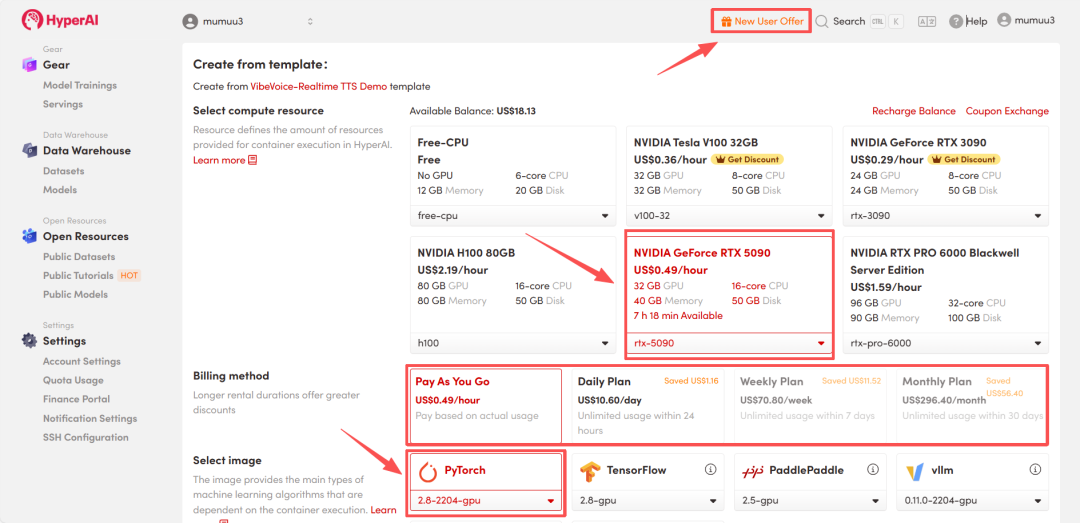
- 选择「NVIDIA GeForce RTX 5090」显卡及「PyTorch」基础镜像。然后根据需要选择「Pay As You Go(按量付费)」或包日/周/月计划,点击「Continue job execution(继续执行)」。
HyperAI为新用户提供注册福利,仅需$1即可获得5小时RTX 5090算力。

- 等待资源分配,首次克隆通常需要约3分钟。当容器状态变为「Running(运行中)」后,点击「API address」旁的跳转箭头,即可进入Demo交互页面。
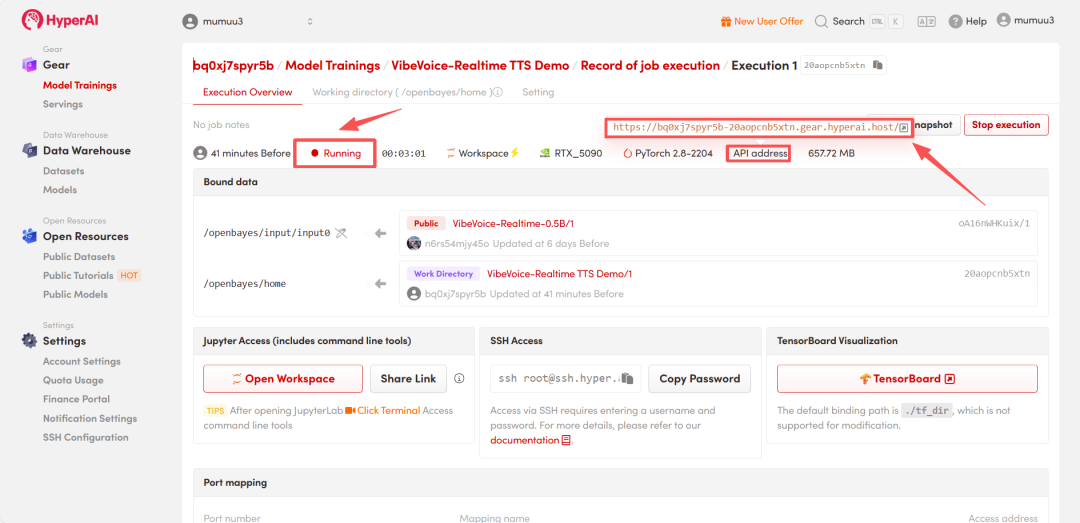
效果演示
在Demo页面中,在「Text to Convert」区域输入需要合成的文本。「Speaker Voice」选项提供了7种可选音色。通过调整「CFG Scale」可以控制语音的情感风格强度,数值越大情感越强。最后点击「Generate Speech」,稍作等待即可生成并试听音频。这种基于云原生平台的快速体验,极大降低了AI应用的门槛。
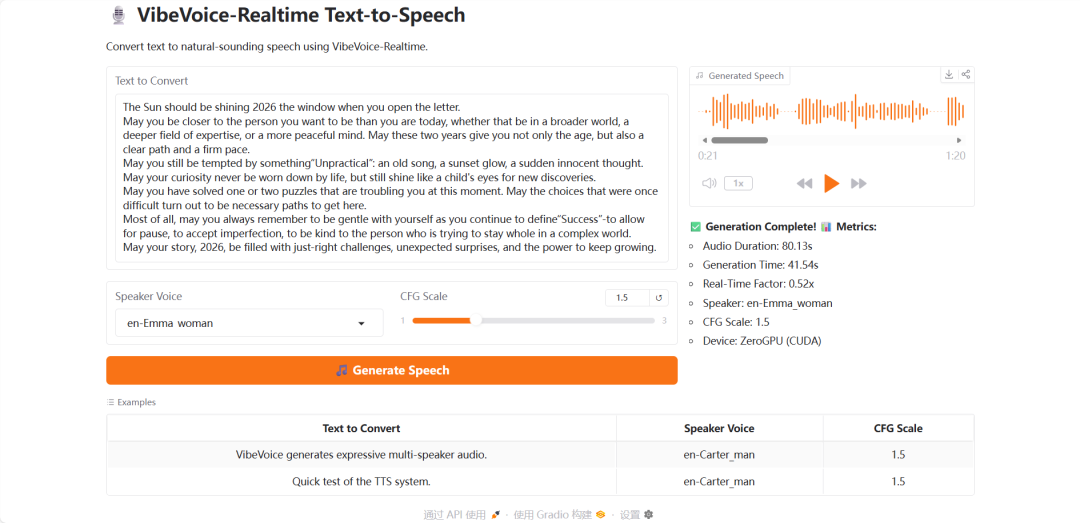
您可以点击播放由VibeVoice生成的新年祝福音频,亲身体验其合成效果。 |  发表于 2025-12-17 04:26:48
|
查看: 240|
回复: 0
发表于 2025-12-17 04:26:48
|
查看: 240|
回复: 0
