在现代分布式系统中,Kafka作为核心的消息中间件,其卓越的性能很大程度上归功于其独特的存储设计:顺序写磁盘。本文将深入解析Kafka采用顺序写磁盘的四大核心优势。
一、实现极致高吞吐量
顺序写磁盘能最大限度地利用磁盘的顺序I/O带宽,并充分发挥操作系统缓存的预读和写回特性。
这种方式显著减少了磁头寻道与盘片旋转延迟带来的性能开销。通过将所有新消息持续追加到日志文件的末尾,Kafka可以将大量零散的写操作聚合成连续的大块I/O请求。这种设计使得Kafka能够实现极高的写入吞吐率,轻松应对流式数据场景下的海量写入需求,这也是其成为优秀消息中间件的关键。
二、充分利用操作系统页缓存
操作系统为了加速文件访问,会将部分空闲内存用作页缓存。当应用程序执行写操作时,数据首先被写入页缓存,随后由操作系统在后台异步地刷写到物理磁盘。
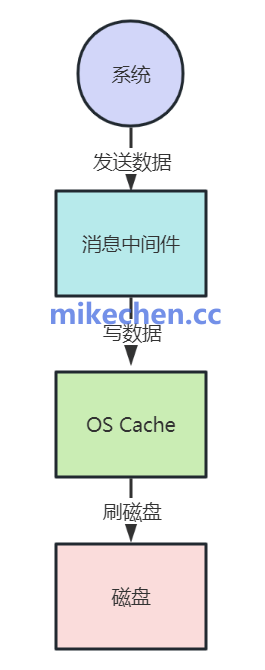
顺序写操作具有高度可预测性,这使得操作系统可以进行有效的预读,并将连续的数据块一起缓存。应用程序读写数据时,直接在内存中进行,避免了每次都与慢速磁盘交互,从而极大地提升了I/O性能。理解这些底层操作系统的优化机制,对于设计高性能系统至关重要。
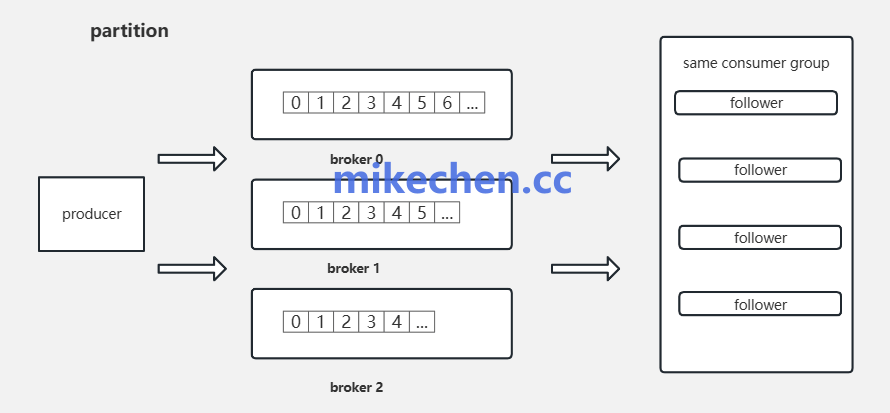
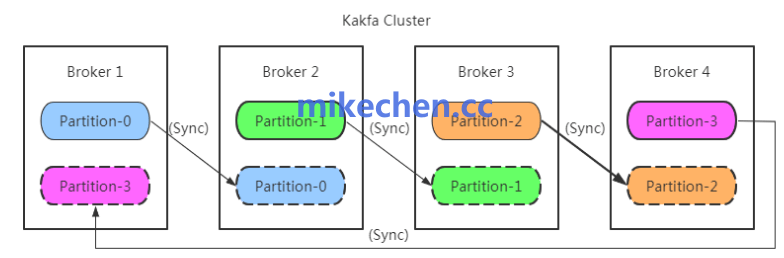
三、保障低延迟与高效副本复制
顺序写简化了数据写入路径,减少了复杂的系统调用与上下文切换次数,使得单条消息的写入延迟保持稳定且可控。
同时,对于保障数据可靠性的副本复制机制而言,顺序追加的日志结构让从节点的增量同步变得极为简单。Follower副本只需按顺序拉取Leader副本日志末尾的新数据并追加到本地即可,完全避免了复杂的随机读写逻辑。这不仅提高了数据复制的效率,也降低了一致性维护的整体延迟。
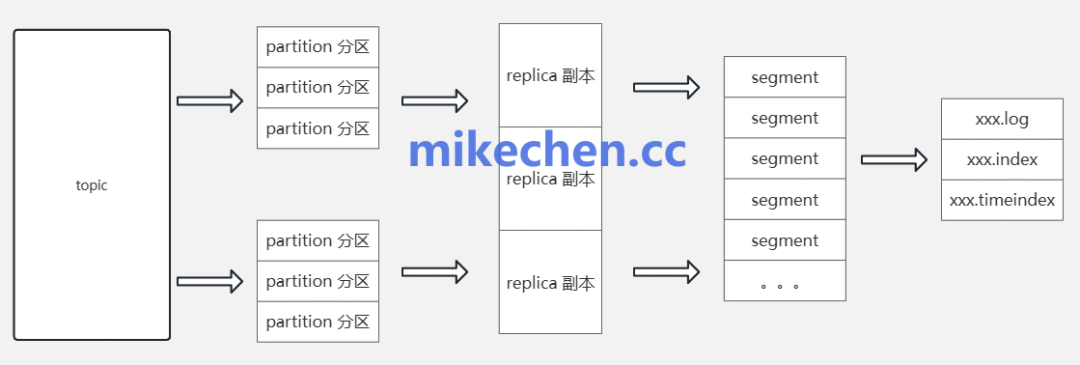
四、提升系统可靠性与故障恢复速度
通过将消息持久化为不可变的顺序日志文件,Kafka能够以简单、可预测的方式实现数据持久化与消费位移(Offset)的管理。
当系统发生故障需要恢复时,顺序日志结构允许服务快速定位到最后一个有效的数据点,并只需重放其后未消费的数据。这种方式避免了恢复过程中产生的大量随机I/O,从而显著提升了系统的恢复速度与整体可用性,非常适合处理流式大数据场景。 |  发表于 2025-12-17 23:07:07
|
查看: 249|
回复: 0
发表于 2025-12-17 23:07:07
|
查看: 249|
回复: 0
