数据库是大型系统架构的核心,支撑千万级QPS(每秒查询率)的数据库设计是一个复杂的系统工程,需要从整体架构、数据分布、性能优化与可运维性等多个维度进行统筹规划。
首先需要明确一个关键认知:任何单体数据库都无法长期稳定地直接承载千万QPS的业务请求。在成熟的高并发系统中,真正的数据库层QPS远低于业务入口QPS,这得益于清晰的请求链路分层:
业务入口 QPS → 缓存层 QPS → 计算层 QPS → 数据库真实 QPS。
一个典型的高并发系统架构层次如下:
Client
↓
CDN / 边缘缓存
↓
接入层(Nginx / API Gateway)
↓
应用层(无状态横向扩展)
↓
缓存层(多级缓存)
↓
数据库层(分库分表 + 主从 + 多集群)
在这套体系中,90%至99.9%的请求通常不会触及数据库,数据库的核心职责被收敛为保证最终一致性与存储最核心的数据。
架构与扩展策略
1. 水平分片
水平分片(Sharding)是应对海量数据与高并发的基石。通过将数据按照业务键(如用户ID)或范围切分到多个独立的数据库节点,可以有效避免单点性能瓶颈。分片策略需要设计得足够灵活,支持数据的在线迁移与负载均衡,以便随着业务增长进行弹性扩容。
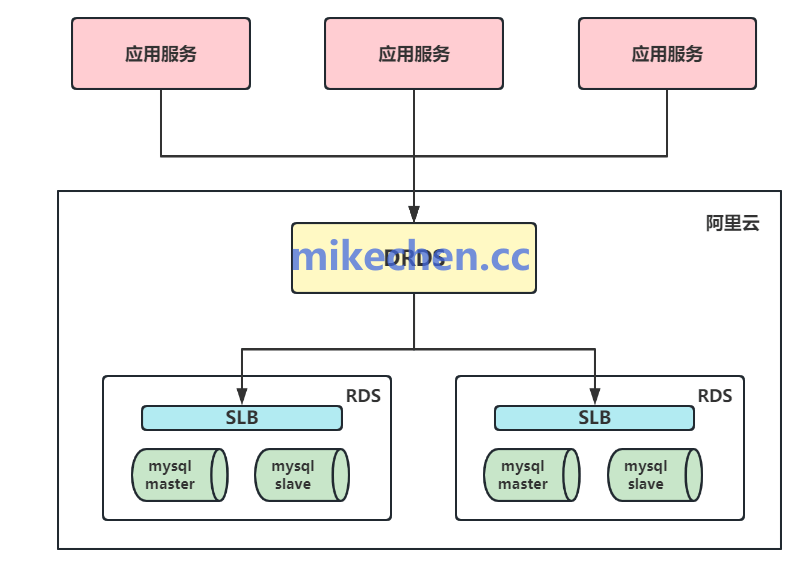
2. 读写分离
采用主从复制或多主架构,将大量的读流量分发到只读副本上,显著减轻主库的压力。对于写入量极高的场景,可以考虑引入有序写入队列或采用分区写入策略,以降低写入冲突。
3. 数据存储与索引优化
- 适配存储引擎:针对不同的业务场景(如热点数据、分析型查询)选择合适的存储引擎,例如内存型数据库、高性能KV存储或列式数据库。
- 冷热数据分离:将访问频率低的冷数据迁移至成本更低的存储介质。
- 精简索引设计:避免创建过多低效的二级索引。优先考虑使用覆盖索引或预计算字段来减少随机I/O。对于写密集场景,可以探索异步更新索引或采用LSM-Tree等写优化数据结构。
多层缓存体系
构建由本地缓存(如进程内缓存)、分布式缓存(如Redis集群)以及CDN(针对静态内容)组成的多层次缓存体系,是拦截读请求、保护后端数据库最有效的手段之一。

缓存的一致性策略需要根据业务对数据实时性的容忍度来设计:强一致性场景可采用写穿透或立即失效策略;对一致性要求不高的场景,则可以使用TTL过期或异步更新机制。
流量削峰(核心防护层)
流量削峰的目标是让绝大部分请求在到达数据库之前就被妥善处理,这是支撑百万至千万QPS的关键。一个设计良好的系统可以直接在接入层和应用层拦截掉70%以上的请求。

- CDN/边缘缓存:适用于商品详情、用户信息、配置数据、新闻资讯等变更不频繁的内容,能极大减轻源站压力。
- 接入层过滤:在Nginx或API网关上实施限流、熔断、请求聚合等策略,将异常或非核心流量挡在门外。
- 应用层异步化:对于非实时业务,将请求放入消息队列异步处理,实现流量的平滑。
高可用与容错设计
1. 多副本与多可用区部署
采用跨机房或跨可用区的数据复制方案,确保在单点或单区域故障时能实现快速切换。结合客户端或中间件的自动重试、熔断机制,防止故障扩散。

2. 流量调度与降级
实施灰度发布、流量导流与服务降级策略。在系统资源紧张或部分组件故障时,暂时关闭非核心功能,确保核心链路的高可用。
3. 灾备与备份恢复
建立定期的全量快照与增量备份机制,并定期进行恢复演练,确保在任何大规模故障下都能快速恢复数据,满足业务连续性与数据安全的要求。
通过以上从架构拆分、缓存建设、流量防护到高可用保障的全方位设计,才能构建出一个能够稳定支撑千万级QPS的健壮数据库体系。 |  发表于 2025-12-18 06:50:56
|
查看: 359|
回复: 0
发表于 2025-12-18 06:50:56
|
查看: 359|
回复: 0
