消息中间件常被视为一个“黑盒”,但只有深入剖析其在磁盘上的字节组织方式,才能真正领悟其设计上的精妙之处。
本文旨在带您“打开机箱”,绕过复杂的源码追踪,直接通过观察文件系统来解构RocketMQ的存储核心。我们将直观地检视消息的最终归宿——CommitLog文件,探究其高效索引ConsumeQueue的结构,并解析ConsumerOffset如何实现多消费者组的进度隔离。所有这些设计,都封装在一个个精心编排的二进制文件中。
一、如何查看Broker的存储目录?
首先启动Broker。为了明确存储路径,需要在broker.conf配置文件中指定storePathRootDir参数。
配置示例如下:
brokerClusterName = DefaultCluster
brokerName = broker-a
brokerId = 0
deleteWhen = 04
fileReservedTime = 48
brokerRole = ASYNC_MASTER
flushDiskType = ASYNC_FLUSH
namesrvAddr=127.0.0.1:9876
storePathRootDir=/Users/wuzexin/_workspace/rocketmq/ROCKETMQ_HOME/store/

配置完成后,启动Broker并使用Producer发送几条测试消息,随后观察store目录的变化。
其典型目录结构如下所示:
store/
├── commitlog/
│ ├── 00000000000000000000
│ └── 00000000001073741824
├── consumequeue/
│ └── TopicTest/
│ └── 0/
│ └── 00000000000000000000
└── index/
└── 20251204173254561
config文件夹下存放着Broker运行时的关键配置信息。
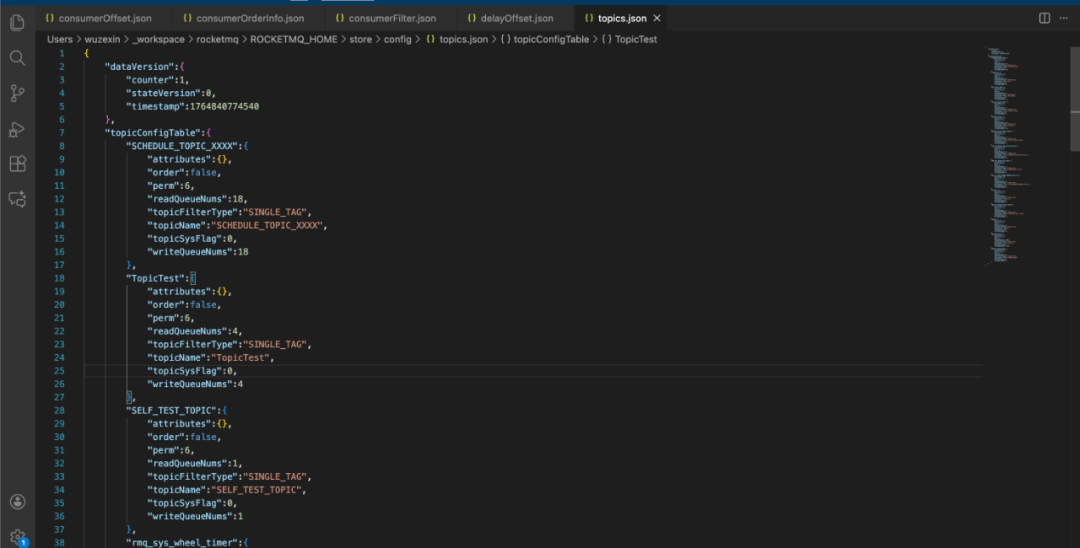
其中可以找到我们创建的Topic TopicTest的记录。
二、Broker存储核心原理剖析
1. 数据基石:CommitLog

CommitLog文件是消息内容的最终存储地。单个文件写满1GB后,会创建新文件继续写入。
文件名即为该文件的起始全局偏移量。例如,00000000001073741824这个文件名,其代表的偏移量1073741824正好等于1GB。
每条消息在CommitLog中的存储格式是固定的,包含丰富的元信息,其结构大致如下:
| 字节数 |
字段名 |
说明 |
| 4 |
TotalSize |
整条消息的总长度 |
| 4 |
MagicCode |
魔数,标识协议版本等 |
| 4 |
BodyCRC |
消息体的CRC校验码 |
| 4 |
QueueId |
所属队列的ID |
| 8 |
QueueOffset |
在ConsumeQueue中的逻辑偏移量 |
| 8 |
PhysicalOffset |
在CommitLog中的物理偏移量(全局) |
| 4 |
SysFlag |
系统标志位 |
| 8 |
BornTimestamp |
消息产生时间戳 |
| 8 |
StoreTimestamp |
消息存储时间戳 |
| 8 |
BornHost (IP+port) |
生产者地址 |
| 8 |
StoreHost (IP+port) |
存储该消息的Broker地址 |
| 4 |
ReconsumeTimes |
消息重试次数 |
| 8 |
PreparedTransactionOffset |
事务消息相关 |
| 4 |
BodyLength |
消息体长度 |
| n |
Body |
消息体内容 |
| 1 |
TopicLength |
Topic名称长度 |
| n |
Topic |
Topic名称 |
| 2 |
PropertiesLength |
消息属性长度 |
| n |
Properties |
消息属性 |
由于消息体长度不定,无法进行均等切分。正是依靠每条消息头部的TotalSize字段,才能准确界定每条消息的边界。
CommitLog实现高性能的关键在于其顺序写的磁盘操作模式,这对于像RocketMQ这样的数据库/中间件而言至关重要。
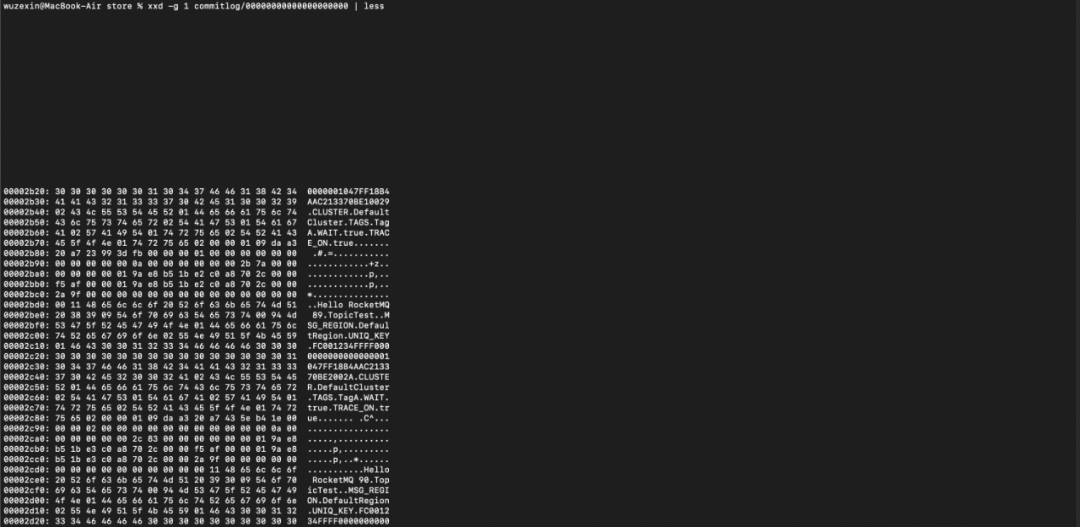
我们可以使用xxd命令查看CommitLog文件的原始内容:
xxd -g 1 commitlog/00000000000000000000 | less
2. 消费指引:ConsumeQueue

ConsumeQueue是CommitLog的索引文件。每个ConsumeQueue文件被逻辑上平均分割为30万(300,000)个固定单元,每个单元20字节,因此单个文件大小固定为约5.72MB。
这20字节的编排如下:
| 字节数 |
字段 |
含义 |
| 8 |
commitlog offset |
指向消息在CommitLog中的物理偏移量 |
| 4 |
size |
消息在CommitLog中的存储长度 |
| 8 |
tag hashcode |
消息TAG的哈希码,用于消费时的TAG过滤 |
消费者拉取消息时,其流程为:先查询ConsumeQueue获取到消息在CommitLog中的物理偏移量(commitlog offset)和大小(size),再根据这两个信息精准地从CommitLog中读取完整的消息内容。
其构建过程是异步的:
Producer 发送消息
↓
写入 CommitLog(消息内容)
↓
ReputMessageService 异步构建:
- ConsumeQueue(消费队列索引)
我们可以使用hexdump命令查看ConsumeQueue索引条目:
hexdump -e '8/1 "%02x " " | " 4/1 "%02x " " | " 8/1 "%02x\n"' consumequeue/TopicTest/0/00000000000000000000
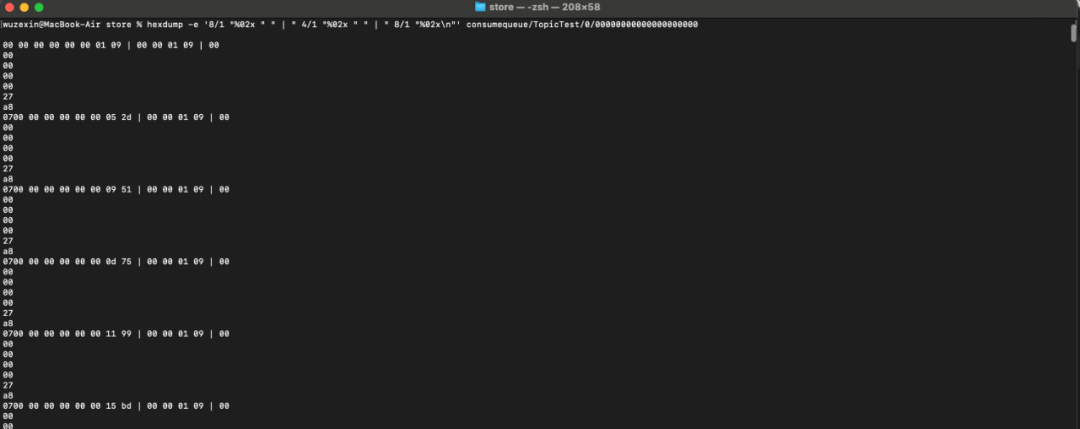
三、从存储结构反推生产与消费流程
基于对存储目录的观察,我们可以对RocketMQ的生产消费流程做出合理推测(可能与实际源码有细微出入,但核心思想一致):
- 生产者(Producer)端:Producer从NameServer获取Topic的路由信息(包含Broker列表及每个Broker上的队列情况)。在发送消息时,会以队列(Queue)为维度进行选择(例如轮询),以实现负载均衡。消息最终被发送到选中的Broker,并由该Broker直接顺序写入CommitLog文件。
- 消费者(Consumer)端:Consumer同样从NameServer获取路由信息,并在消费者组内进行队列负载均衡(Rebalance)。当Consumer准备拉取某个队列的消息时,会向对应的Broker发起请求。Broker根据请求中携带的
queueId和offset,定位到具体的ConsumeQueue文件。由于ConsumeQueue文件名就是起始偏移量,且条目定长,可以快速计算出offset对应的索引条目位置,进而找到消息在CommitLog中的精确位置并读取。
四、从存储看多消费者组的进度管理
一个有趣的问题是:当存在多个消费者组订阅同一个Topic时,RocketMQ如何为每个组维护独立的消费进度?毕竟所有的ConsumeQueue索引是共享的。
答案在于另一个文件:consumerOffset.json。如果没有配置消费者组,或者消费者组没有消费行为,这个文件可能是空的,因为此时无需记录额外的偏移量信息。

但是,一旦配置了消费者组并开始消费,consumerOffset.json文件就会记录下每个消费者组(group)对于每个Topic的每个队列(queueId)的当前消费进度(offset)。
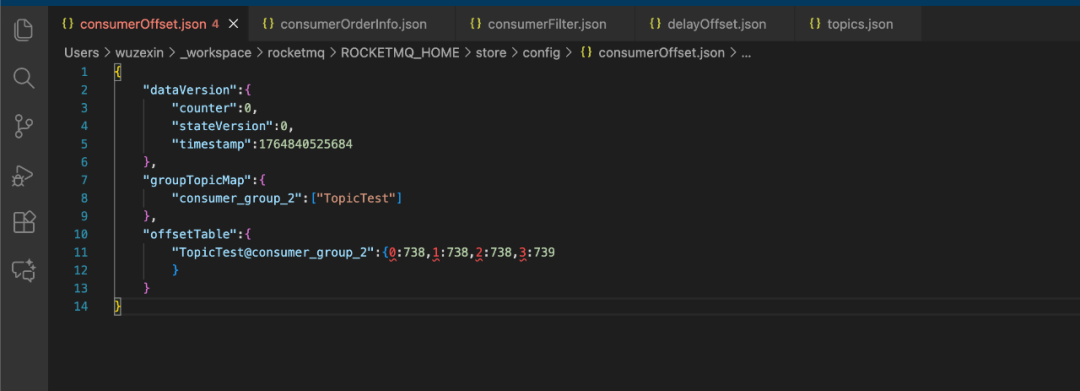
工作流程如下:
- 消费者上报或拉取进度时,Broker会查询
consumerOffset.json,获取该消费者组在指定队列上的最后消费偏移量。
- 然后,Broker根据这个偏移量去对应的ConsumeQueue中查找下一条待消费消息的索引。
- 由于ConsumeQueue是定长结构,即使进行随机查找(根据偏移量计算文件内位置)也非常高效。
这种将共享的物理存储(CommitLog)、共享的读索引(ConsumeQueue) 与私有的逻辑进度(consumerOffset.json) 分离的设计,正是RocketMQ能够高效支持多消费者组并行消费同一份消息的基石。对于使用RocketMQ进行系统解耦的Java开发者而言,理解这一机制对性能调优和问题排查很有帮助。
当然,关于新增消费者组时的行为、消息被所有组消费完后文件的清理机制等,还有许多细节值得深入探讨,本文作为入门解析,先到此为止。
 发表于 2025-12-19 00:42:53
|
查看: 203|
回复: 0
发表于 2025-12-19 00:42:53
|
查看: 203|
回复: 0
