在数字化业务场景下,保障服务的持续可用是系统架构设计的核心目标之一。实现99.99%的可用性(年停机时间约52分钟),需要从全局视角进行分层规划与设计。
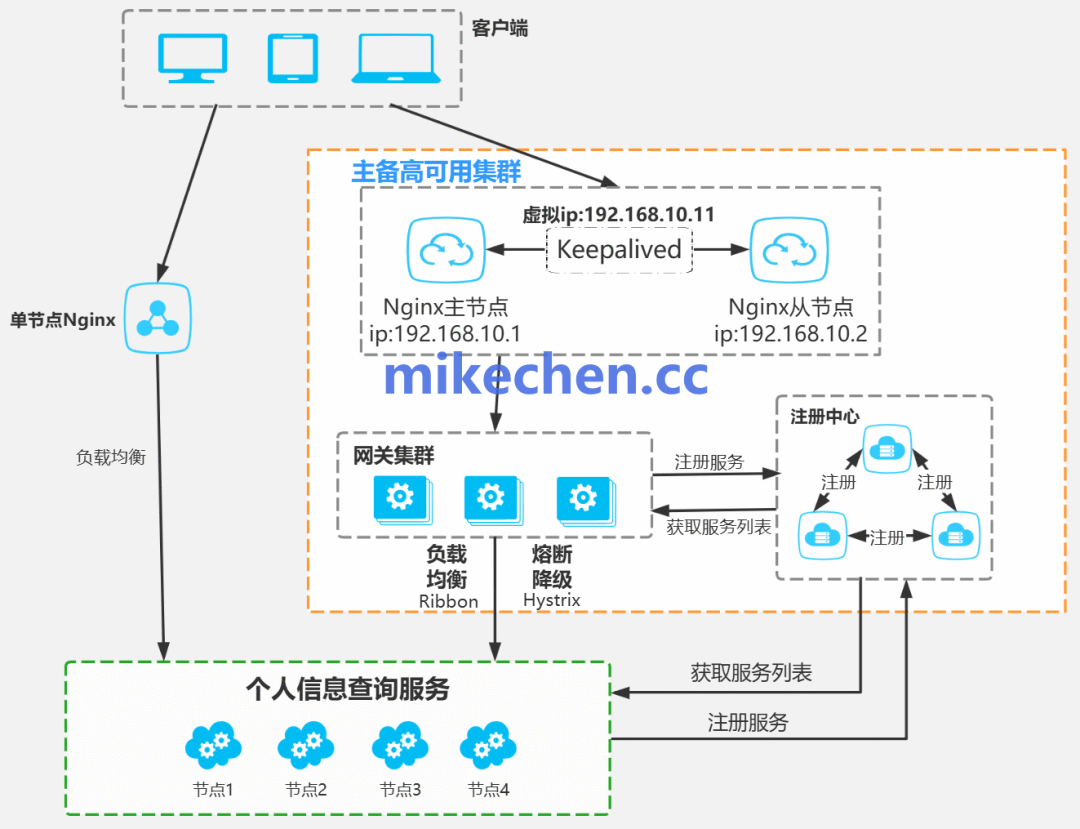
首先,应将整体可用性目标(SLA)拆解到各个架构层级,例如入口层、核心服务层、数据层等,并为不同层级或服务定义差异化的服务等级目标(SLO)。例如,核心业务链路追求99.99%,而非核心服务可能设定为99.9%即可,以此在成本与可靠性之间取得平衡。
流量入口层的高可用设计
流量入口层作为系统对外服务的门户,必须具备冗余与智能调度的能力。
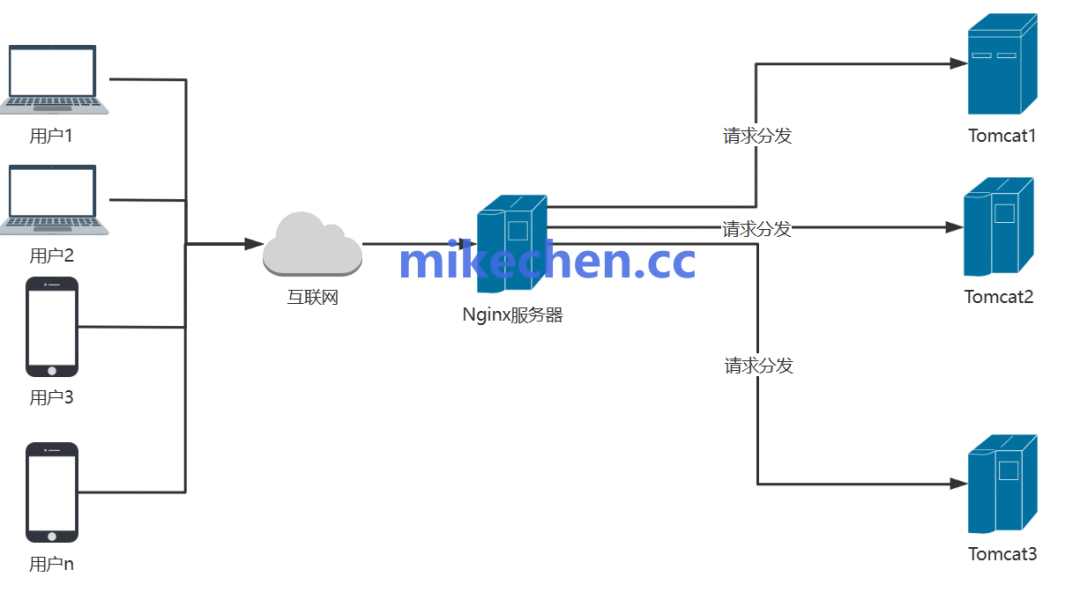
典型的流量入口高可用链路如下:
用户请求 ↓ DNS/AnyCast全局调度 ↓ 多VIP/多SLB集群 ↓ 多Nginx/Gateway实例
其核心在于部署多个全局负载均衡节点,并结合多活或主备模式的边缘负载均衡器与防火墙。通过健康检查机制与自动流量切换策略,确保单点故障不影响整体服务。例如,L4/L7负载均衡器自身可通过 Keepalived + VRRP 协议实现主备或双主热备,消除负载均衡器自身的单点故障。
应用层的高可用设计
应用层承载核心业务逻辑,是故障的频发区域,其高可用设计的核心在于实现无状态化、故障隔离与快速弹性伸缩。
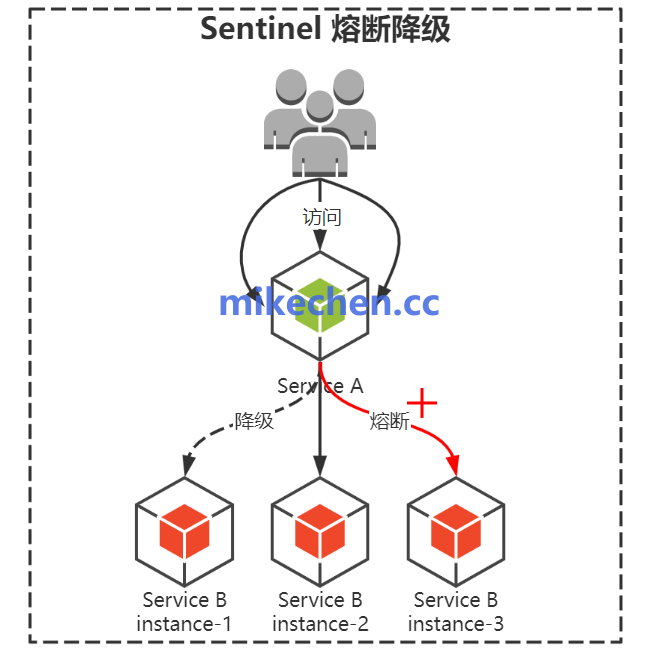
此外,必须集成一系列服务治理策略,常被称为保障稳定性的“四大基石”:
- 超时:为所有外部调用设置合理的超时时间,防止请求无限等待,占用系统资源。
- 限流:在流量超过系统处理能力时,主动拒绝部分请求,实现系统自我保护。
- 熔断:当依赖的下游服务失败率达到阈值时,自动熔断对其的调用,防止故障扩散引发级联雪崩。
- 降级:在系统压力过大或部分功能异常时,暂时关闭非核心功能,保障核心业务流程的畅通。
这些策略是构建健壮微服务与分布式系统的关键实践。
中间件层的高可用设计
消息队列、缓存、配置中心等中间件是架构中的关键枢纽,其可用性直接影响全局。高可用策略主要包括集群化部署、数据分片与副本、以及自动故障转移机制。
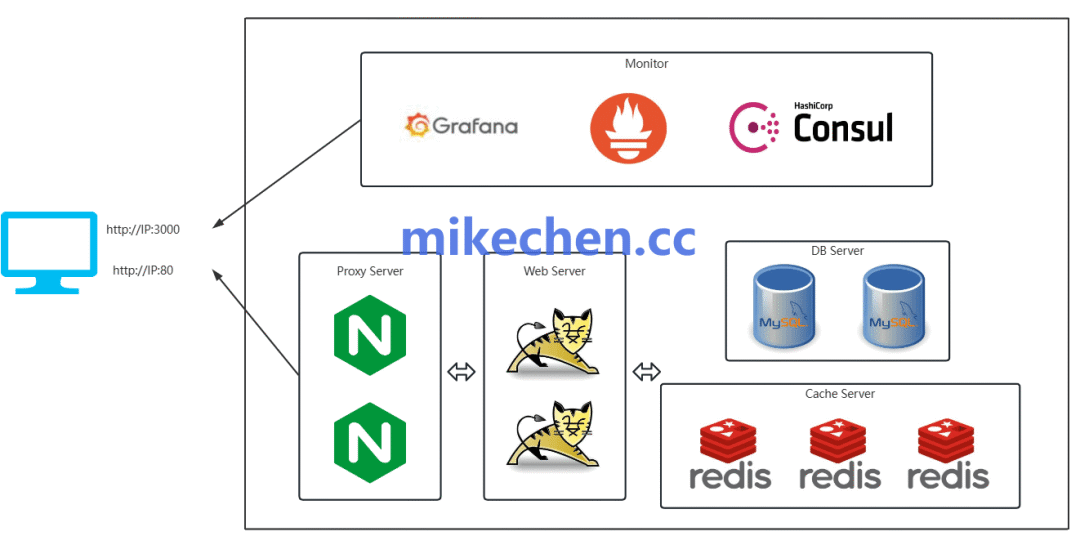
针对缓存,常见的高可用方案有:
- 集群模式,如 Redis Cluster,提供数据分片与在线扩容能力。
- 哨兵(Sentinel)模式,实现主从故障的自动监测与切换。
针对消息队列(如 Kafka),Broker节点必须集群部署。通常建议设置副本因子(Replication Factor)至少为3,以确保即使单个节点故障,数据依然可用且服务不中断。这类设计是现代化云原生架构的基石。
数据层的高可用设计
数据层涉及数据的持久化与一致性,是高可用设计中复杂度最高、容错成本最大的部分。
设计时必须在数据副本、备份策略、同步延迟与一致性保证之间进行权衡。常见方案包括:
- 主从复制:通过二进制日志实现数据异步或半同步复制。
- 多主复制:允许多个节点同时接受写操作,需解决冲突问题。
- 分布式一致性协议:采用如 Paxos、Raft 等协议实现强一致性的分布式存储。
采用半同步复制可以在一定程度上降低主库宕机时的数据丢失风险。除此之外,定期的冷备份、建立异地容灾数据中心,以及定期进行灾难恢复演练(包括故障切换流程验证与数据完整性校验),都是保障数据最终可用的必备实践。 |  发表于 2025-12-19 19:12:00
|
查看: 242|
回复: 0
发表于 2025-12-19 19:12:00
|
查看: 242|
回复: 0
