
当你与AI大模型对话时,账单上“Token”这个计量单位是否让你感到困惑?它直接决定了你的使用成本,甚至影响着不同模型的“智商”水平。今天,我们将深入剖析Token的本质,帮你搞清楚每一分钱花在了哪里。
Token:AI世界的“话费”与“流量”
AI服务并非免费午餐,其核心计费逻辑就建立在Token之上。观察各大AI厂商的定价表,无论是输入还是输出,其计价单位无一例外都是Token。
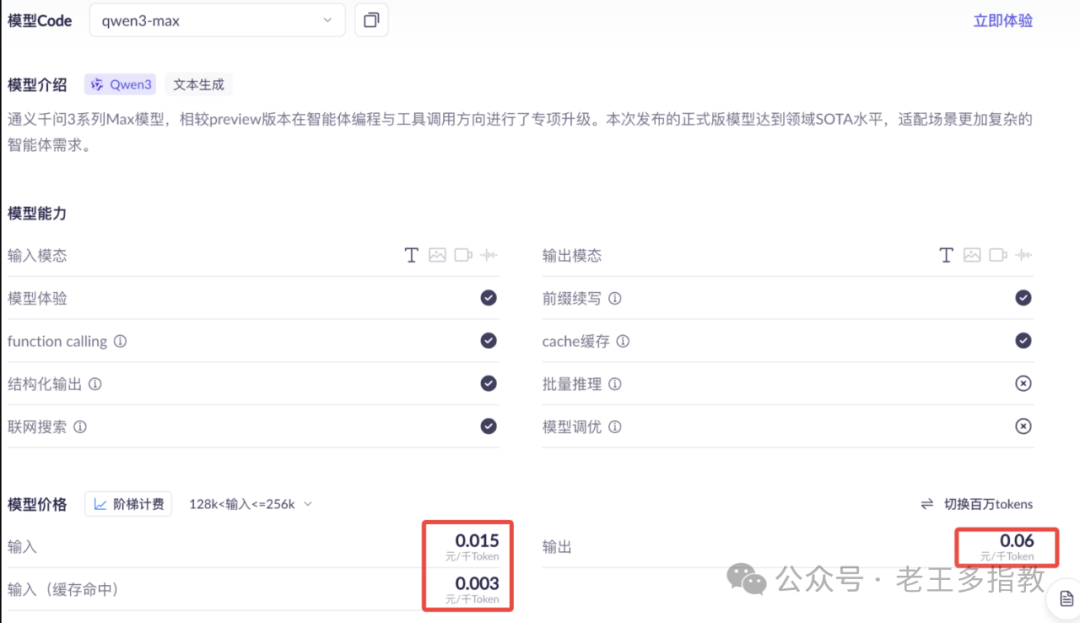
你可以将这个过程类比为手机通讯:你向AI发送的提示(如“帮我写周报”)消耗“输入Token”,相当于上行流量;AI返回的答案消耗“输出Token”,相当于下行流量。理解Token的计量方式,是成为精打细算的AI使用者的第一步。
一个Token不等于一个单词
那么,Token究竟如何计算?它等同于一个汉字或一个英文单词吗?事实远非如此简单。
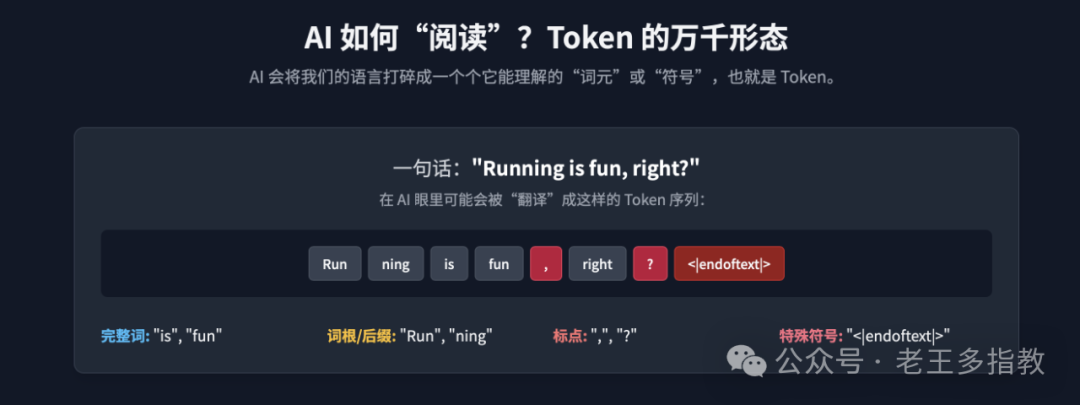
以一句简单的英文“Running is fun, right?”为例。在我们看来是4个单词,但在AI的“眼中”,它可能被拆解成更细的颗粒。以通义千问模型的分词器为例,其对这句话的拆分结果如下:
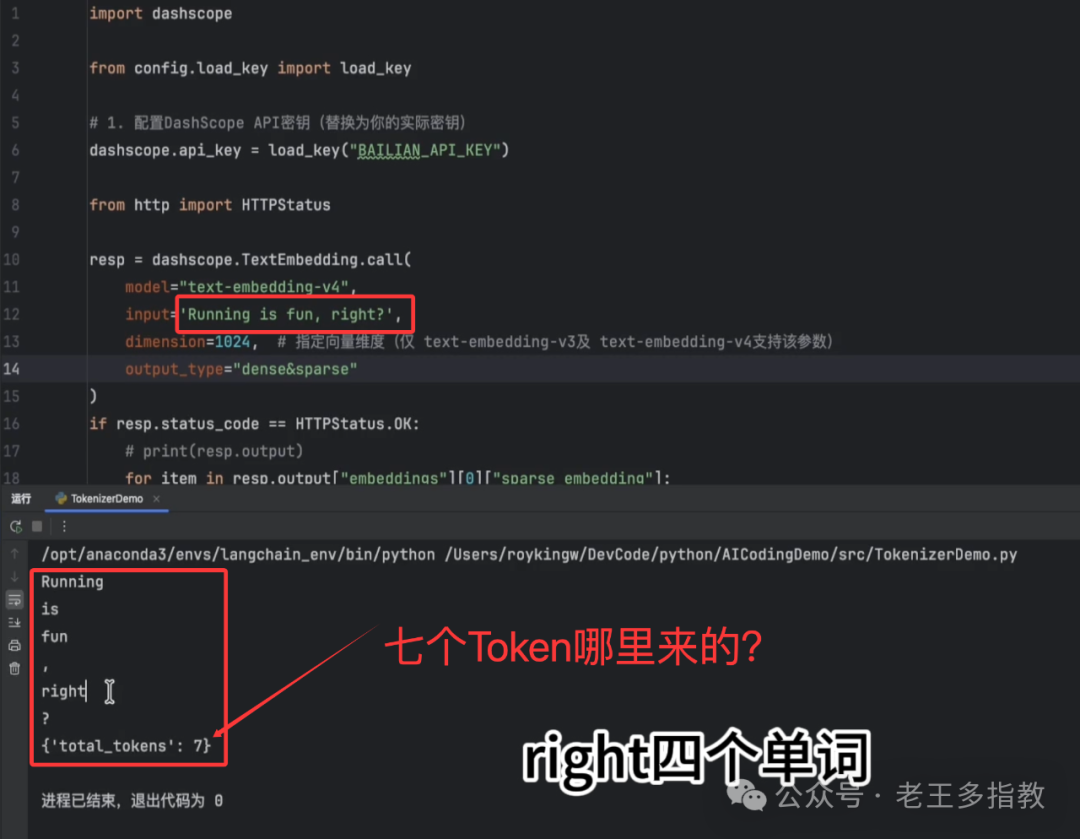
可以看到,它被拆分成了 ‘Running‘, ‘is‘, ‘fun‘, ‘right‘ 以及逗号和问号,共计6个独立Token(总计7个Token,包含一个起始标记)。Token是AI能够理解和处理的最小语义单元,是它的“专属字典”条目,而非我们直观认为的单词或汉字。标点符号、空格甚至是一些不可见的特殊控制字符(如表示文本结束的 <|endoftext|>)都可以是独立的Token。
对于英文,许多模型还会将常见词缀(如“ing”、“ed”)或高频词组作为一个整体Token,这进一步说明了Token划分的统计本质,而非简单的语法规则。
AI“专属字典”的诞生:无监督学习
谁制定了拆分Token的规则?答案并非人类工程师,而是AI模型自己。

大模型在训练初期,会“阅读”海量的互联网公开文本数据。通过统计学习方法,模型会自动发现哪些字符序列经常共同出现,并将它们定义为一个Token,赋予一个唯一的ID(例如“苹果”可能对应ID 19416),从而构建起一个庞大的“词表”(Vocabulary)。
这个过程是完全数据驱动的。因此,不同模型由于训练数据不同,其Token词表也各不相同,这直接影响了模型对语言的理解能力和“智商”高低。这也解释了为何在早期研究中,让两个AI互相对话时,它们可能发展出人类无法理解的“暗语”。
理解“人话”的关键:上下文语境
将句子拆分成Token后,AI如何理解其真实含义?关键在于上下文。

以经典例句“我叫苹果,我爱吃苹果,我用苹果手机。”为例。通义千问分词器可能将三个“苹果”都划分为同一个Token。那么,AI如何区分人名、水果和品牌?
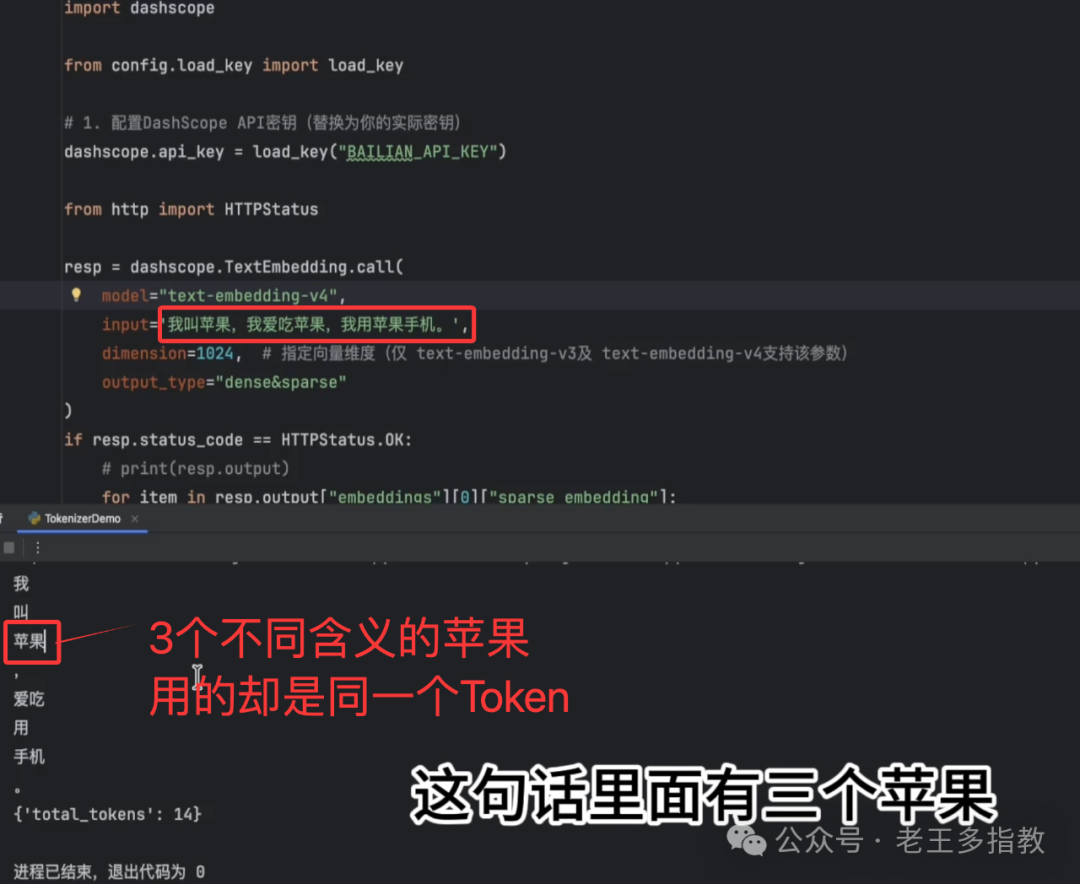
答案在于模型会分析目标Token前后所有的Token(即上下文):
- 遇到第一个“苹果”时,模型看到前面的“叫”,结合训练经验,判断此处应为人名。
- 遇到第二个“苹果”时,结合前面的“吃”,判断为可食用的水果。
- 遇到第三个“苹果”时,结合前面的“用”和后面的“手机”,判断为电子品牌。
这种让AI具备“瞻前顾后”能力的核心技术,便是Transformer架构及其核心的自注意力机制。它使得模型能够动态权衡并融合句子中所有Token的信息,从而精准把握每个词在特定语境下的含义。理解这一机制是深入人工智能领域的关键。
核心总结

最后,我们总结关于Token的三个核心要点:
- Token是AI的基石与计价单位:它是大模型理解和生成语言的基本单元,直接决定了模型的计算成本和商业计费模式。
- AI的工作是连续的Token预测:模型基于输入的Token序列,不断预测下一个最可能出现的Token,以此生成连贯的回复。
- AI的智能源于上下文理解:模型的强大不在于记忆了多少Token,而在于它能通过Transformer架构深度分析上下文,让同一个Token在不同语境下焕发不同含义。
掌握Token的概念,不仅能让你更清晰地核算AI使用成本,更能帮助你理解大语言模型的工作原理,从而更高效地利用Python等工具进行提示工程或应用开发,从被动的使用者转变为主动的构建者。
 发表于 2025-12-20 01:30:50
|
查看: 284|
回复: 0
发表于 2025-12-20 01:30:50
|
查看: 284|
回复: 0
