在大规模广告推荐系统中,如何在保证检索效率的同时提升检索精度,一直是业界关注的核心难题。传统的双塔模型虽高效,但用户与广告特征的交互能力不足。腾讯广告团队提出一种基于GPU加速的压缩倒排索引(Compressed Inverted List)技术,首次在工业级海量数据检索中成功实现了 Wide & Deep 架构,并在实际业务中取得了离线与在线指标的双重提升。
一、行业痛点
1. 双塔模型的局限性
在工业界广告检索系统中,双塔模型(Two-Tower Model) 是主流方案。其核心思想是分别对用户和广告进行嵌入编码,最后通过内积计算相似度:$s = \langle u, a \rangle$,其中 $u$ 和 $a$ 分别为用户和广告的嵌入向量。
这种架构的根本问题在于:用户和广告的特征仅在最后的内积阶段进行交互,导致模型难以捕捉复杂的特征交互模式。
2. 检索与排序的效率-精度困境
- 排序阶段:可以使用复杂的深度神经网络(如 Wide & Deep、DeepFM),允许特征进行早期交互。
- 检索阶段:需要从海量候选集(百万至亿级)中快速筛选,计算复杂度限制了复杂模型的应用。
这一“效率-精度”的两难困境,是广告检索系统长期面临的挑战。
二、核心创新
1. 广告领域 Learning-to-Rank 的训练框架
召回任务本质是通过打分函数筛选高得分候选,常用双塔网络结合LambdaRank框架进行训练,目标是直接优化排序指标。
针对广告场景的改进:
原始LambdaRank仅考虑排序位置。在广告竞价(如oCPM)场景中,错误排序高价值广告会造成更大的收入损失。因此,引入价值感知的损失函数:$\lambda_{i j}=\left|\Delta N D C G_{i j}\right| \cdot \operatorname{Penalty}\left(v_i, v_j\right)$,其中 $\operatorname{Penalty}\left(v_i, v_j\right)$ 衡量交换两个广告位置导致的商业价值损失。这使模型在优化排序的同时,更关注高价值广告的正确排序。
2. 模型架构:双塔 + 隐式交互 + 显式交互
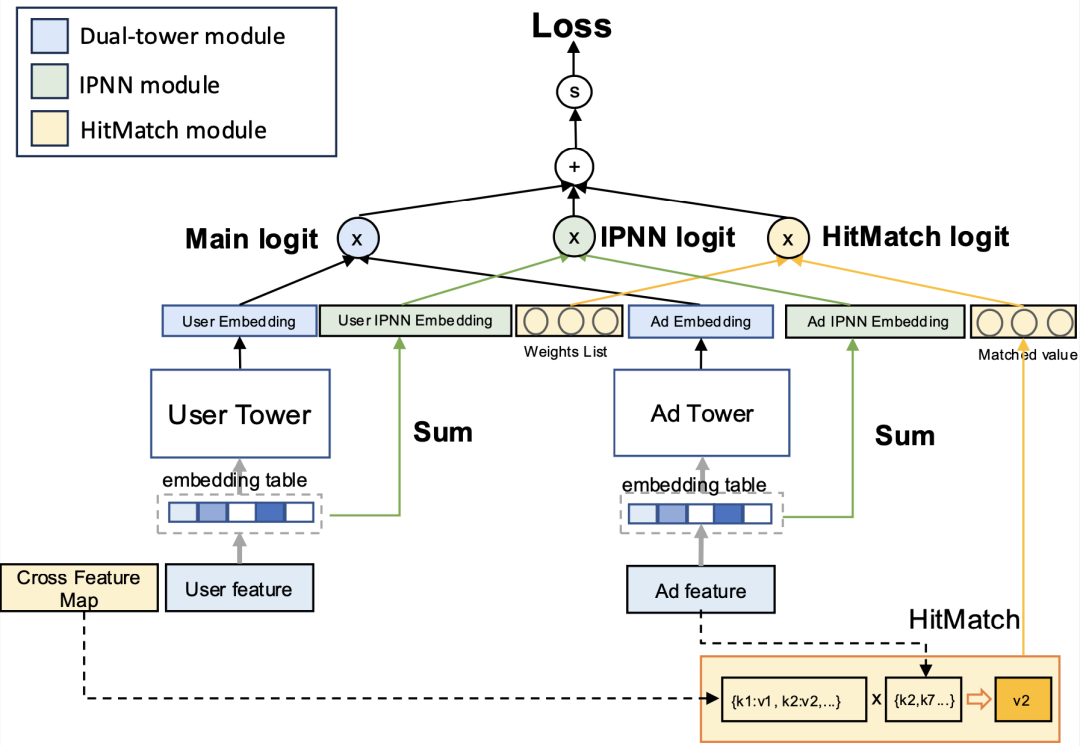
图:混合交互式广告召回模型架构
论文的核心贡献是在双塔结构基础上引入隐式与显式特征交互,同时保持检索效率。整体架构如下:
- 双塔网络(Deep部分):用户塔和广告塔分别编码,输出嵌入向量 $u^{d e e p}$ 和 $a^{d e e p}$。
- IPNN模块(隐式交互):通过内积神经网络捕捉用户-广告特征的隐式交互,输出 $u^{i p n n}$ 和 $a^{i p n n}$。
- HitMatch模块(显式交互/Wide部分):基于用户历史行为的交叉特征匹配,计算加权得分。
最终得分公式为:
$$s = \langle [u^{deep}; u^{ipnn}], [a^{deep}; a^{ipnn}] \rangle + \sum_{k=1}^K w_k \cdot v_k \cdot \mathbb{I}(hit_k(a))$$
其中:
- $w_k$ 为第 $k$ 个交叉特征的可学习权重,$v_k$ 为对应特征值;
- $\mathbb{I}(hit_k(a))$ 表示广告 $a$ 是否命中第 $k$ 个交叉特征。
这一设计首次将Wide & Deep架构成功引入检索阶段。然而,Wide特征的引入显著增加了计算耗时。为此,文章提出了压缩倒排索引结构,显著加速Wide特征交叉计算,这体现了工程与算法协同设计在突破人工智能模型性能瓶颈中的价值。
3. 压缩倒排索引结构
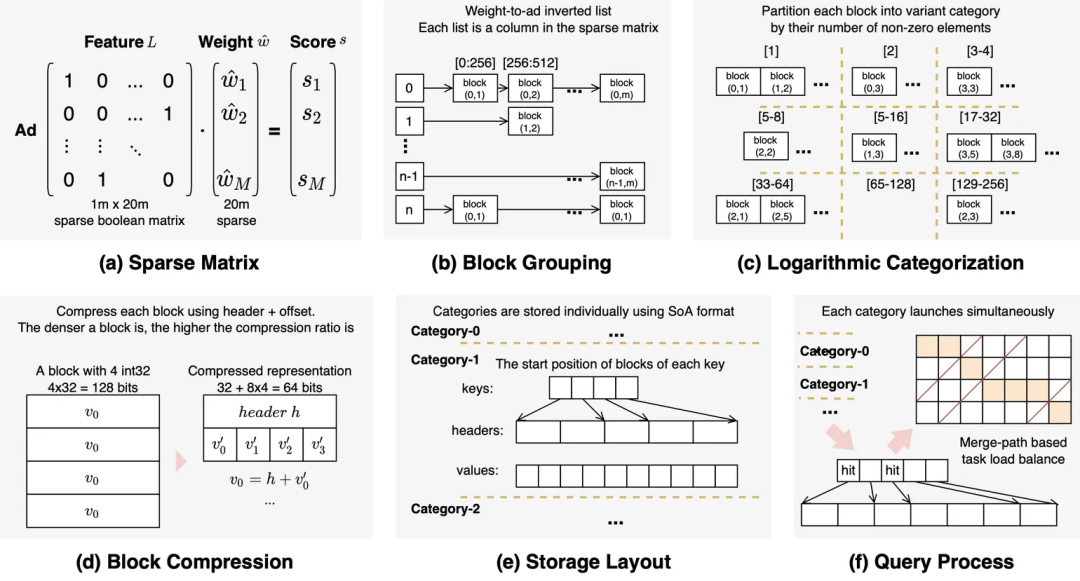
图:面向GPU加速的压缩倒排索引结构图
为支持GPU高效并行计算,团队设计了压缩倒排索引,其核心在于优化负载均衡和显存数据交换:
- 结构优化:针对GPU内存访问模式优化,将与特定用户特征组合相关的广告集合编码成紧凑的倒排表示。
- 并行检索:利用GPU大规模并行线程,对倒排条目进行批量解码和特征交互计算。
- 内存效率:通过编码压缩,显著降低GPU-CPU IO带宽压力,提升访存效率。
- 负载均衡:引入指数级长度变化编码和运行时动态调度,保证不同长度倒排条目在并行计算时负载平衡,提升吞吐。
三、实验验证
实验旨在验证三个核心问题:
- RQ1:提出的方法在离线评估中是否优于基线模型?
- RQ2:GPU倒排索引是否显著提升工程效率?
- RQ3:该方法能否在线上带来实际业务收益?
1. 离线实验(RQ1)
使用微信朋友圈/视频号广告平台的真实历史数据进行训练评估(前6天训练,第7天测试)。
| 实验数据 |
模型 |
GAUC |
Recall@5_1 |
Recall@10_1 |
| DT(基线) |
0.839 |
0.730 |
0.908 |
| DT-IPNN |
0.843 |
0.739 |
0.913 |
| DT-HitMatch |
0.847 |
0.753 |
0.924 |
| DT-IPNN-HitMatch |
0.861 |
0.768 |
0.939 |
| 相对基线提升 |
+2.62% |
+5.21% |
+3.41% |
效果分析:
- 协同效应:DT-IPNN-HitMatch在所有指标上最优,证明隐式与显式特征交互具有互补性。
- 强信号作用:DT-HitMatch相比DT-IPNN提升更显著,表明用户历史交互的交叉特征是强预测信号。
- 兴趣稳定性:交叉特征的有效性得益于用户兴趣在一定时间窗口内的相对稳定。
2. 倒排索引性能分析(RQ2)
在 Tesla T4 显卡上,将GPU倒排索引与Nvidia cuSPARSE库进行对比(使用1000个特征向量查询)。
| 测试效果 |
方法 |
预处理时间(ms) |
QPS(1/s) |
| cuSPARSE |
N/A |
275.94 |
| 本文方法 |
224.32 |
1904.23 |
| 提升 |
- |
+590% |
性能分析:
- 7倍QPS提升:相比cuSPARSE实现约7倍的吞吐量提升。
- 预处理开销低:224ms的索引构建时间可在大量查询中均摊。
- 亚毫秒级延迟:对于百万级广告候选池,HitMatch算子可在500微秒内完成,满足实时检索要求,这为云原生环境下高性能、低延迟的服务部署提供了关键技术支撑。
3. 在线A/B测试(RQ3)
模型已部署至腾讯广告系统,在微信朋友圈和微信视频号场景进行测试: |
流量场景 |
消耗提升 |
GMV提升 |
Recall@100_1提升 |
| 微信朋友圈 |
+0.37% |
+1.58% |
+1.8% |
| 微信视频号 |
+1.25% |
+1.49% |
+2.5% |
业务价值:
- 收入与GMV双增长:验证了检索阶段特征交互对最终业务指标的正向传导。
- 召回质量提升:Recall@100_1提升表明能筛选出更多高质量候选。
- 跨场景泛化:在两个不同场景均取得正向收益。
- 工程可落地:百万候选池下500微秒的延迟,证明方案具备工业级可用性。
四、结语
本文通过引入GPU加速和创新数据结构,给出了一个兼顾精度、效率与工程可落地性的解决方案,首次将Wide & Deep模型成功应用于工业级检索系统,有效解决了推荐系统检索阶段“特征交互不足”与“计算效率低下”之间的矛盾。
该工作也为大规模推荐系统的架构优化提供了新思路:通过工程/算法协同设计(co-design) 来突破算法瓶颈。此方案亦可应用于其他内容推荐系统领域。
参考文献
[1] Lei, Y., et al. (2025). An Efficient Embedding Based Ad Retrieval with GPU-Powered Feature Interaction. arXiv:2511.22460.
[2] Cheng, H. T., et al. (2016). Wide & deep learning for recommender systems. DLRS.
[3] Huang, J. T., et al. (2020). Embedding-based retrieval in facebook search. KDD.
 发表于 2025-12-20 06:26:09
|
查看: 180|
回复: 0
发表于 2025-12-20 06:26:09
|
查看: 180|
回复: 0
