在互联网行业,推荐算法往往被视为核心商业机密,但马斯克在1月20日真正兑现了他的承诺,将 X 平台内容推荐的核心算法代码开源公之于众。开源仓库在 GitHub 上线仅 6 小时,就收获了超过 1.6k 的 Star 数,引发了技术社区的广泛关注。
此次开源之所以激起巨大反响,不仅在于马斯克“晒家底”的举动本身,更因为这批代码清晰地揭示了 X 平台正在进行一场激进的技术范式转移:它正彻底告别依赖“人工堆砌规则”的旧时代。
一、 开源库概览
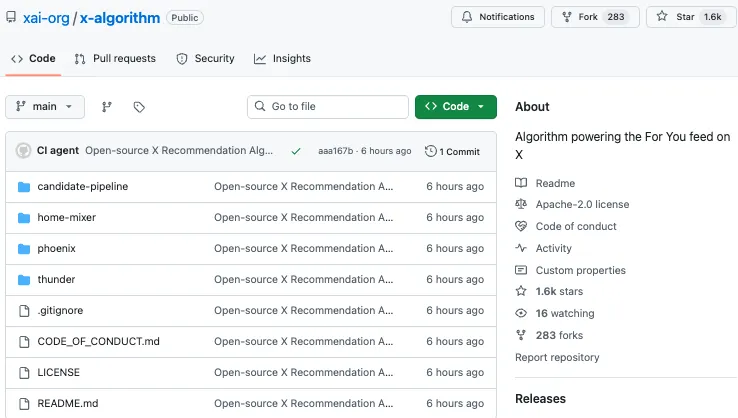
开源项目名为 x-algorithm,采用了 Apache License 2.0 协议。
传统的推荐系统常被戏称为“胶水逻辑”,它由一部分机器学习模型和另一部分成千上万条人工定义的“硬规则”拼接而成。然而,从 X 此次开源的代码来看,其变革相当彻底——几乎剔除了所有手工设计的特征。
全新的 X 推荐算法,其核心已完全由基于 xAI Grok 的 Transformer 架构接管。这意味着系统不再依赖程序员去定义“什么内容权重更高”,而是让模型直接从用户的点赞、转发、回复等行为序列中,自主学习内容与用户之间的深层关联。
三、 技术栈解密
从开源仓库中可以清晰地看到明确的语言分工:Rust + Python。这种组合是现代大规模互联网架构在“极致性能”与“开发灵活性”之间做出的经典平衡:
- Rust 负责“重体力活”(编排与并发):推荐系统的核心——Home-mixer(编排层) 和 Thunder(站内检索)模块均由 Rust 编写。作为一门追求零成本抽象和内存安全的语言,Rust 在处理 X 平台每秒数百万次请求的场景下,能提供极高的吞吐量和极低的延迟。它负责处理候选内容的补全、查询、过滤器逻辑以及 Kafka 消息处理。可以说,Rust 构成了整个系统的“钢筋骨架”,确保其在高并发下稳定可靠。
- Python 负责“大脑驱动”(模型与适配):Phoenix(推荐模型)模块则大量使用了 Python。这得益于 Python 极其成熟的 AI 生态系统,在处理模型训练、策略适配以及脚本测试时,开发效率远超其他语言。X 团队将 Grok 的 Transformer 实现移植到推荐场景,正是利用 Python 实现了算法的快速迭代。
这种“Rust 筑基,Python 调优”的组合,已经成为 IT 行业处理复杂分布式系统与 AI 模型结合的典型范式。
四、 内容推荐的7个阶段
此次开源的代码,正是驱动 X 平台‘为您推荐(For You)’信息流的核心算法。在 X 的推荐逻辑中,一条推文要最终呈现在你的屏幕上,需要经过一个严密的多阶段 Candidate Pipeline(候选流水线):
- 特征补全:算法启动的第一步是实时构建用户画像。系统会瞬时抓取你近期的互动记录(点赞、点击、转发)、关注列表及偏好设置,为后续所有计算奠定基础。
- 双路召回:系统同时开启两个渠道进行内容初筛。一是 Thunder 模块,负责从你关注的人中检索新帖;二是 Phoenix 召回模块,利用机器学习技术从全网海量内容中捞取你可能感兴趣的“陌生人”帖子。
- 信息增强:召回得到的内容最初只有 ID,这一步会补全推文的文本、图片、视频时长、作者认证状态等完整元数据。
- 前置过滤:在消耗大量计算资源进行精细打分之前,系统会启动“清洗模式”,直接过滤掉你已屏蔽的、看过的、重复的,或可能引起反感的负面内容。
- 多维度打分:这是最核心的环节。Phoenix 模型会基于用户的互动历史,同时预测你对某条内容产生点赞、转发、回复等多种互动行为的概率,并进行综合加权计算。
- 多样性筛选:即使某些内容得分很高,算法也会进行干预。它会刻意降低同一作者的重复内容权重,并平衡站内关注与站外推荐内容的比例,以确保信息流具有多样性。
- 最终验证后推送:在正式推送到你的设备前,进行最后一轮合规性和有效性检查,确认无误后才会最终呈现在信息流中。
五、 算法公开是透明化的开端
马斯克此次开源行动确实显得底气十足。X 的流水线架构实现了业务逻辑与监控逻辑的清晰分离,其“隔离计算”的设计保障了单篇帖子得分的稳定性。对于任何希望构建高可扩展推荐系统的技术团队而言,这无疑是一份极具参考价值的实战资料。
然而,算法开源也伴随着潜在的挑战。首先,透明度是一把双刃剑。一旦规则完全公开,那些旨在操纵流量的“黑产”就可能针对性地设计策略以骗取高分。其次,也是最关键的一点:目前开源的是代码逻辑,而模型训练所用的具体数据集以及最终模型权重并未公开。
马斯克声称“其他公司都不敢这样做”。这种“将逻辑摊在阳光下”的做法,确实在倒逼整个行业重新审视算法透明度的价值与实现路径。对开发者而言,深入研究这样的开源项目,无疑是理解现代大规模推荐系统设计的绝佳途径。欢迎到 云栈社区 的对应板块,与更多开发者交流探讨相关技术细节。 |  发表于 2026-1-24 12:05:18
|
查看: 240|
回复: 0
发表于 2026-1-24 12:05:18
|
查看: 240|
回复: 0
