本文解读阿里在 arXiv 上发布的论文《PI2I: A Personalized Item-Based Collaborative Filtering Retrieval Framework》。这篇论文提出了一种创新的 物品到物品(Item-to-Item, I2I) 召回框架,通过在训练阶段引入独特的负样本挖掘策略,实现了训练与线上推理的一致性,并在淘宝“猜你喜欢”场景的线上 AB 测试中带来了 在线交易率提升 1.05% 的显著效果。
核心问题与框架概述
传统的 I2I 推荐旨在回答一个问题:给定一个用户和一个触发物品(trigger item),用户喜欢另一个目标物品(target item)的概率是多少?即建模 P(target item | user, trigger item)。
论文提出的 PI2I (Personalized Item-to-Item) 框架,本质上是一个使用了复杂排序模型的召回方法。其整体流程可以概括为:
- 离线构建 I2I 关联表:为全站物品预先计算共现关系,形成
trigger -> [target1, target2, ..., targetT] 的映射。
- 在线异步推理与缓存:当用户点击某个物品(成为 trigger)时,异步调用 PI2I 模型,使用用户的历史行为序列作为 triggers,计算出推荐候选列表并缓存。
- 推荐服务读取缓存:当用户访问推荐页面时,服务直接读取已缓存的推荐结果,实现高效召回。
模型结构与训练创新
模型本身采用了在推荐系统中较为常见的架构:
- 输入特征:包含用户画像、触发物品(trigger item)特征、目标物品(target item)特征以及它们之间的交叉特征。
- 序列建模:使用 Multi-Head Target Attention (MHA) 对用户历史行为序列进行建模,其中 Query 是由 trigger、target 及交叉特征拼接后经 MLP 得到的向量。
- 预测层:将序列建模的输出与其他特征向量拼接,送入一个深度神经网络(DNN),最终输出一个标量分数,代表用户对“trigger-target”对的兴趣概率。
- 损失函数:采用 Softmax 交叉熵损失,核心目标是让正样本的分数高于所有负样本。
本文的核心创新点并非模型结构,而在于负样本的挖掘策略。传统的做法通常使用全物料库随机采样作为“易负例”,用曝光未点击样本作为“硬负例”。PI2I 则提出了一种与线上推理分布更一致的负样本构造方法。
创新的负样本挖掘策略
模型的训练样本格式为 (用户, 触发物品, 目标物品, 标签)。正样本即用户有正向交互(如点击)的 (trigger, target) 对。
负样本分为两类,均从基于历史行为构建的 I2I 关联表中采样:
- 硬负例(Hard Negatives):从与正样本相关的触发物品(称为“正触发”)所关联的目标物品池中随机采样(排除正样本本身)。
- 为什么“硬”:这些负例与正样本高度相似(因为它们来自同一触发物品的关联池),迫使模型学习更细微的区别,从而提升模型的判别能力和鲁棒性。
- 易负例(Easy Negatives):从用户历史行为序列中,非正触发的其他物品所关联的目标物品池中采样。
- 为什么“易”:这些负例与正样本关联较弱,为模型提供了明确的对比信号,帮助其快速区分明显不相关的物品。
为什么不使用曝光未点击或完全随机的物品作为负例?
关键在于与线上推理分布保持一致。线上推理时,模型使用用户历史行为序列中的所有物品作为 triggers,根本不会涉及“曝光未点击”或“完全随机”的物品。如果在训练中引入这类分布外的样本,会导致训练-推理偏差,从而影响最终的检索效果。
关键技术:I2I 关联表构建
负样本挖掘依赖一个预计算的 I2I 关联表。构建方法如下:
对于每个物品 i (作为 trigger),计算其与所有其他物品 j 的关联分数 s(i, j)(例如,基于共现频率的统计指标)。然后对分数进行降序排序,取 Top-T 个物品作为 target,最终形成 trigger -> [target1, ..., targetT] 的映射关系表。这张表是离线周期更新的。
线上异步推理流程
一个自然的疑问是:如此复杂的模型(类似排序模型)用于召回,线上耗时如何保证?
PI2I 采用了 在线异步推理 的方案来解决这个问题:
- 用户在浏览商品详情页时,会有点击行为。
- 该点击行为触发一个异步请求,将当前物品作为关键 trigger,结合用户实时行为序列,调用 PI2I 模型进行推理。
- 推理结果(一批推荐候选)被写入缓存(如 Redis)。
- 当用户随后访问推荐 feed 流(如“猜你喜欢”)时,推荐服务直接从缓存中读取结果并展示,避免了实时的高耗时模型计算。
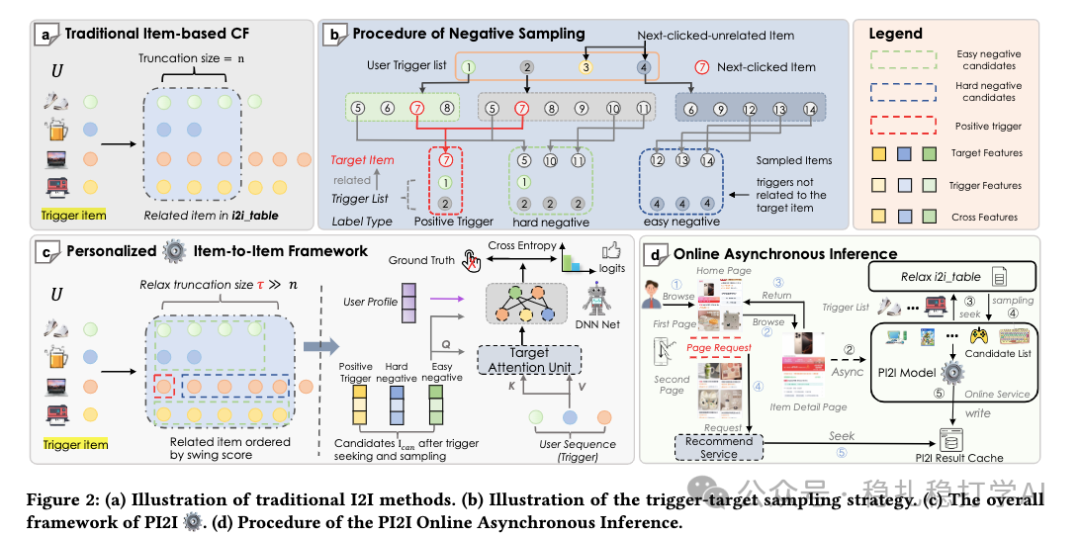
图:PI2I 框架全貌。(a)传统基于物品的协同过滤;(b)负采样策略;(c)个性化物品到物品框架;(d)在线异步推理流程。
总结与思考
技术要点总结:
- 一致性是关键:PI2I 最大的亮点在于其负样本构造策略严格对齐了线上推理的数据分布,消除了因训练样本偏差带来的性能损失。这在 召回 阶段尤为重要。
- 创新负样本源:不同于仅在同一个请求上下文(session)内挖掘负样本,PI2I 创新地从用户整个历史行为序列中,利用 I2I 关系挖掘负例,拓宽了对比学习的视野。
- 工程架构设计:通过“在线异步计算 + 结果缓存”的架构,巧妙地将一个“重”模型应用于对延迟极其敏感的召回阶段,这是算法落地的重要工程实践。
可探讨的方向:
论文将“构建 I2I 表”作为第一步先行介绍,而将核心的召回模型作为第二步。从读者理解的角度,或许以核心任务(个性化 I2I 召回)为主线,将 I2I 表作为支撑性的负样本挖掘工具来介绍,逻辑会更顺畅。
阿里团队在电商推荐场景下的这一实践表明,在召回阶段精细化地设计 Deep Learning 模型,特别是负样本采样策略,仍然能带来显著的性能提升。这为推荐系统的优化提供了一个扎实的技术思路。对这类 算法 模型细节和工程实现感兴趣的开发者,可以关注云栈社区的智能与数据板块,那里有更多深入的讨论和技术分享。
 发表于 2026-1-27 07:09:58
|
查看: 216|
回复: 0
发表于 2026-1-27 07:09:58
|
查看: 216|
回复: 0
