

Attention Sink 来源于 Transformer 需要 Context Aware 的 Identity Layer,即需要 Attention Block 根据 Context 不输出任何变化的能力。
背景
最早是 Streaming LLM 这篇工作发现了 Attention Sink 这一现象:在 Transformer 模型的较深层中,注意力会越来越聚焦于序列的第一个 token。然而,这篇论文并没有深入解释这一现象背后的原因。

▲ https://arxiv.org/abs/2309.17453
那么,为什么模型会表现出这种“偏爱”呢?
在我的认知里,似乎一直没有论文能给出一个令人完全信服的解释。直到去年有一项工作专门进行了实证研究,试图探索其中的一些规律:

▲ https://arxiv.org/pdf/2410.10781
Understanding Attention Sink
基于现有的观察,我们尝试提出一个假设,以期解释所有与 Attention Sink 相关的实验现象:
Attention Sink 来源于 Transformer 需要 Context Aware 的 Identity Layer,即需要 Attention Block 根据 Context 不输出任何变化的能力。
证据一:首个 token 的 value 几乎为 0

▲ https://arxiv.org/pdf/2410.10781
从上述实证研究论文图中的第一行第三列可以发现,第一个 token 对应 value 的范数(norm)非常小。这意味着即使模型“关注”到了这个 token,它对最终输出结果的贡献也微乎其微。
这就引出了一个核心问题:模型为什么要去关注一个几乎为零的 value 呢?
- 对于序列开头的两三个 token 而言,模型学习到的可能主要是 bi-gram 或 tri-gram 这类相对简单的模式。我们有理由认为,这些任务在较浅的模型层中就可以完成。
- 假设浅层网络已经输出了“正确”的表示,那么深层网络需要做的,可能就是保持一种“恒等变换”,即不改变输入。
但是,Attention Block 如何实现这种数据依赖的恒等变换呢?
- 考虑残差连接结构,Attention Block 要实现恒等变换,就需要其输出接近于 0。
- 由于每个 token 在每一层是否需要“跳过”(恒等变换)是依赖于具体上下文(data-dependent)的,因此无法通过像
W_O * W_V * W_K 这样固定的静态参数来实现。
- 那么,就必须通过 Softmax Attention 机制本身来实现。这意味着在 key 空间中必须存在一个特殊的 key:
k_zero,这个 key 对应的 value 是 0。模型需要在想输出 0 时,能够精确地 attend 到这个 k_zero。
- 这也意味着模型必须为这个
k_zero 分配一个独立的子空间。这个 k_zero 需要与所有其他正常的 key 向量正交或呈负相关,这样才能保证当 query 与 k_zero 夹角很小时,其注意力分数最高,从而实现 attend 到 sink token 并输出 0 的目的。
- 同时,这个
k_zero 的模长也必须设计得比较小,以确保在模型不需要进行恒等变换时,它对正常注意力计算的影响降到最低。其原理如下图所示。

▲ sink token 和其余 token 的 key 会有什么区别

▲ https://arxiv.org/pdf/2410.10781
上述实证研究论文中的实验图也佐证了我们的猜想。第二行第二列显示,当发生 sink 时,其他 key 之间的余弦相似度几乎为 0 或负值;同时第一行第二列显示第一个 token 的 key 的模长显著更小。
证据二:模型存在 early decoding,且越深的层 sink 越明显
如果我们使用语言模型头(lm head)去探测中间层特征所预测的 token,可以发现模型确实存在“提前解码”的现象。即从某个中间层开始,其输出的 Top-1 预测结果就已经和最终输出层的 Top-1 相同了。
而如果我们探测不同层的注意力分布图(Attention map),也会发现 Attention Sink 现象确实在更深的层中更为明显。这进一步支持了“深层网络更倾向于执行恒等变换”的猜想。
(部分实验图片可能涉密,无法公开,这里仅分享结论)
证据三:非归一化或者非正定 kernel 会消除 sink
假设我们手动设置一个与所有 key 的相似度都为 1、value 为 0 的虚拟 token(这等价于给 Softmax 分母加上了一个常数 e^1)。理论上,这会缓解 sink 现象。有研究者进行了实验,验证了这一猜想。

▲ https://arxiv.org/pdf/2410.10781
同时,上述实证研究论文也发现,使用非归一化的注意力机制(即注意力分数不一定非负,且加和不一定为 1)的模型没有出现 sink 问题。这同样佐证了我们的猜想:如果模型的注意力分数不一定非负,那么它也可以通过分数组合来实现输出 0,而不必依赖一个专门的 sink token。
证据四:Attention Sink 浪费了 dim,Gate 可以解决
Attention Sink 导致模型必须为 k_zero 分配一个专用的子空间,我们合理怀疑这会带来模型维度(dim)的浪费(即使给分母加常数 e 也无法从根本上解决)。一个想法是使用门控(gating)操作,使得模型可以 data-dependent 地输出 0。恰巧,Qwen 团队最近的相关实验为此提供了证据:

▲ https://arxiv.org/pdf/2505.06708
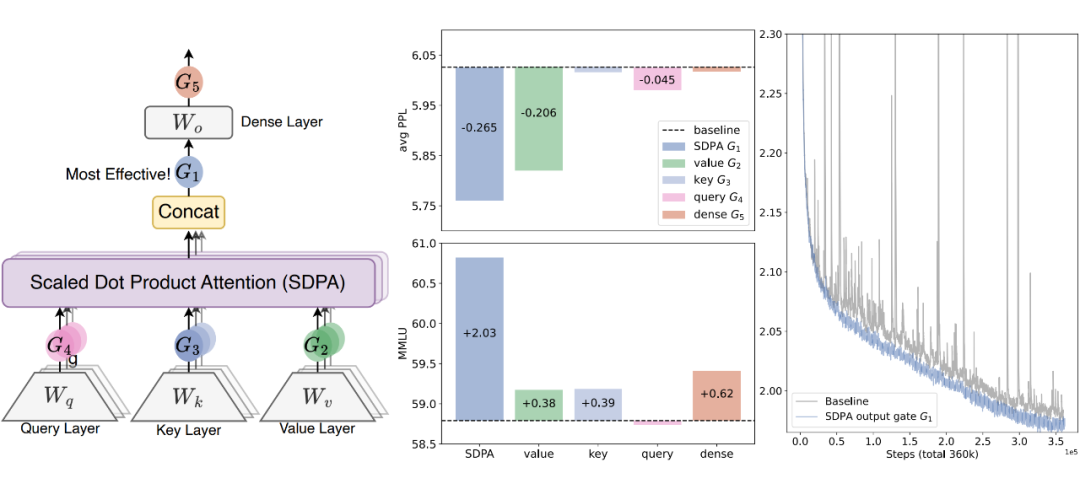

先不谈其带来的具体效果提升,他们发现在注意力机制的输出阶段(对应图中的 G1)加入门控最为有效,并且成功消除了 Attention Sink。这与我们的猜想一致(在 key、query、value 投影处加入门控 G2、G3、G4 并不能直接让注意力输出变为 0,但在输出处加入门控 G1 可以)。
总结
Transformer 模型中的 Attention Sink 现象,很可能源于模型对 context-aware 的 identity layer 的内在需求。多项经验性证据支持这一假设:
- Sink token 的 value 接近于 0,且其 key 拥有专用子空间;
- Transformer 存在 early decoding 现象,且更深的网络层中 sink 现象更为严重;
- 通过采用非归一化或非正定的注意力核函数,可以移除 Attention Sink;
- 门控机制能够有效消除 Attention Sink,并且可能因为解决了子空间浪费问题从而带来性能提升。
这一假设为 Attention Sink 提供了一个连贯的解释框架,并得到了来自多项独立实验的经验性证据支持。关于Transformer等大模型的内部工作机制,仍有诸多值得探讨的奥秘,欢迎大家在云栈社区继续交流讨论。
 发表于 2026-3-13 06:02:21
|
查看: 229|
回复: 0
发表于 2026-3-13 06:02:21
|
查看: 229|
回复: 0
