在大数据处理的实践中,数据集成是连接异构数据源、保障数据高效流转的核心环节。面对日益增长的数据规模,传统基于行式存储的同步方式在应对列式存储的数据源时,常常遇到性能瓶颈。为解决这一挑战,DataWorks数据集成推出了基于Apache Arrow列存格式的全新同步能力,实现了从“行式转换传输”到“列式直通”的技术升级,显著提升了数据同步效率。
技术核心:基于Apache Arrow的列存同步方案
Apache Arrow:高性能列式内存数据标准
Apache Arrow是由Apache基金会主导的跨语言、高性能列式内存数据标准,被广泛应用于Spark、Flink等大数据生态系统中。其核心优势在于:
- 零序列化/反序列化:数据以内存二进制块形式直接传输,避免了繁琐的格式转换开销。
- 零拷贝(Zero-Copy):支持跨进程或跨系统共享内存,极大降低了CPU与内存的消耗。
- CPU缓存友好:列式存储提高了数据访问的局部性,从而优化了计算效率。
- 统一类型系统:支持复杂嵌套数据结构,确保了数据在不同平台间类型的兼容性。
简而言之,Apache Arrow让数据能够“原样流动”,省去了在不同格式间“反复翻译”的过程。
架构演进:从“行式搬砖”到“列式直通”
传统的数据集成工具大多采用“行存驱动”的设计:
- 读取器(Reader)从列存文件(如ORC、Parquet)中读取数据,并解码为单行的记录(Record)对象。
- 同步框架传递这些行记录。
- 写入器(Writer)再将行记录编码为目标端的列存格式。
这个过程存在明显的性能损耗,包括多次数据类型转换、频繁的Java对象创建与垃圾回收(GC)压力,以及内存带宽利用效率低下。
而基于Apache Arrow的新架构彻底改变了这一流程:
- 读取器直接输出列式的数据批次(Columnar Batch)。
- 写入器直接消费这些列式批次。
整个同步链路无需在行、列格式之间进行转换,实现了真正意义上的“端到端列式流水线”。
传统行存同步架构示意图(以MaxCompute列存数据同步到MaxCompute为例):
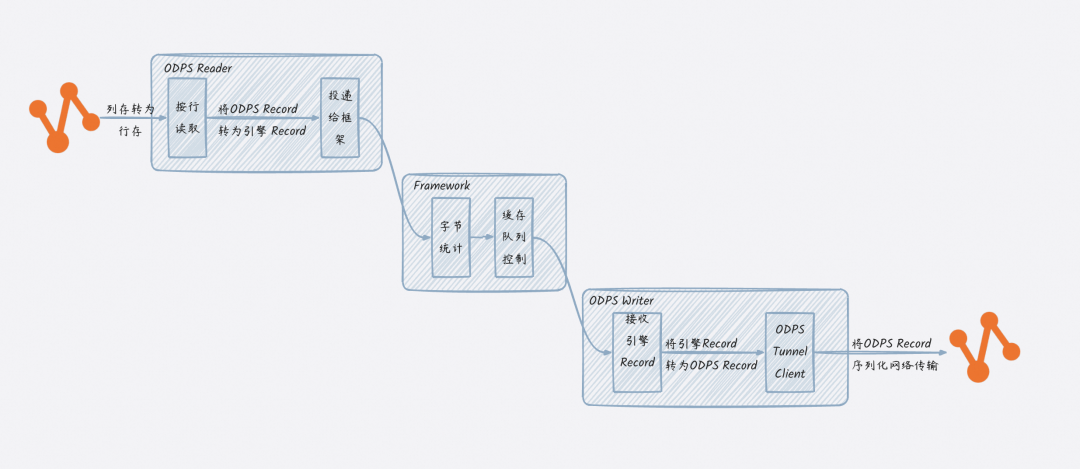
核心流程涉及多次格式转换与序列化操作。
Arrow列存同步架构示意图:
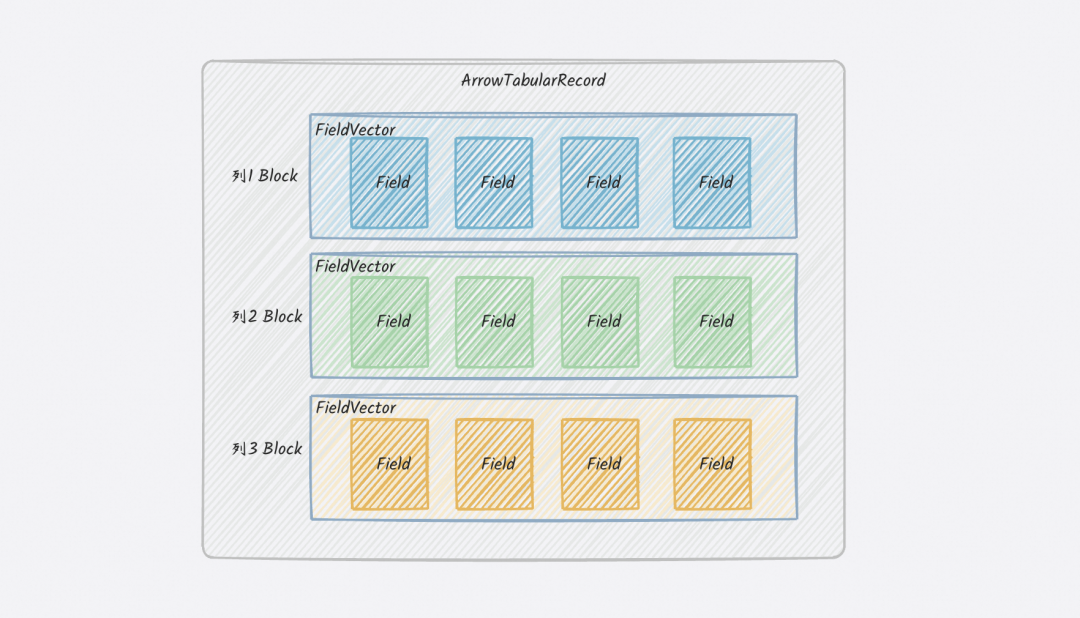
DataWorks通过引入全新的ArrowTabularRecord数据结构,原生支持Arrow列式数据,跳过中间的行式转换环节,实现“短路同步”。
核心能力与性能表现
DataWorks数据集成现已全面支持MaxCompute、Hologres、Hive/OSS/HDFS(Parquet/ORC格式)等主流列存数据源的Arrow读写能力。用户仅需在任务配置中为Reader和Writer添加 "useArrow": true 参数,即可一键启用高性能同步模式。
性能压测数据
在多种典型同步场景下,启用Arrow列存同步后性能提升显著:
场景一:MaxCompute列存同构同步
- 性能提升:约200%
- 说明:源和目标均为MaxCompute表,通过Tunnel Arrow API直接进行列存数据交换。
场景二:Hologres同步至MaxCompute
- 性能提升:87% - 95%
- 说明:避免通过JDBC行式接口导出的瓶颈,直接以Arrow格式传输。
场景三:Parquet/ORC文件同步至MaxCompute
- 性能提升:Parquet提升约5.55倍,ORC提升约9.85倍。
- 说明:直接读取Parquet/ORC底层的Arrow格式数据,免去解码为行记录再编码的步骤。这些文件可存储于HDFS、OSS等分布式文件系统中。
核心优势与应用场景
主要优势
- 高性能:吞吐量最高提升可达10倍,特别适用于宽表、海量数据的迁移与同步。
- 低成本:零拷贝与内存复用机制大幅降低了GC压力,节省了计算资源消耗。
- 高兼容性:无缝支持主流大数据平台与列式存储格式。
- 易用性:配置简单,无需修改业务代码即可获得性能增益。
典型应用场景
- 大数据平台迁移/搬站:将Hive等数据仓库中的数百TB数据迁移至MaxCompute,同步耗时从小时级缩短至分钟级。
- 湖仓一体数据流转:构建高效的“数据湖”(如Hive)与“数据仓库”(如MaxCompute、Hologres)之间的数据通道,支持一数多用、湖仓协同的架构。
如何启用Arrow加速
单表离线同步配置
在DataWorks数据集成任务的JSON配置中,分别在Reader和Writer的parameter部分添加"useArrow": true参数。请注意,该功能要求源端和目标端的列数据类型保持一致。
{
"type": "job",
"steps": [
{
"stepType": "hive",
"parameter": {
"useArrow": true,
"datasource": "my_datasource",
"column": ["col1", "col2"],
"readMode": "hdfs",
"table": "table"
},
"name": "Reader",
"category": "reader"
},
{
"stepType": "odps",
"parameter": {
"useArrow": true,
"truncate": false,
"datasource": "odps_test",
"column": ["col1", "col2"],
"table": "table"
},
"name": "Writer",
"category": "writer"
}
],
"setting": {
"speed": {
"concurrent": 3
}
}
}
整库同步解决方案
DataWorks已发布的Hive至MaxCompute整库同步功能,会根据字段类型自动判断并启用Arrow高性能同步能力,用户无需进行复杂配置。
总结与展望
DataWorks数据集成通过引入Apache Arrow列存同步能力,利用其列式、零拷贝、内存高效传输的特性,为大数据同步场景带来了显著的性能突破。未来,DataWorks将继续扩展对更多数据源(如ClickHouse、Iceberg)的支持,并探索智能调度等优化,致力于构建更强大、高效的企业级数据流转平台,助力企业打破数据孤岛,实现数据价值的快速流动。
 发表于 2025-12-20 07:11:57
|
查看: 200|
回复: 0
发表于 2025-12-20 07:11:57
|
查看: 200|
回复: 0
