随着大模型参数与训练数据迈入“双万亿”时代,单芯片算力增长难以匹配模型复杂度的指数级提升。为突破内存墙、通信墙与计算墙的物理瓶颈,大规模AI集群的网络架构面临范式重构。Google Jupiter DCN(数据中心网络)的演进,特别是引入Apollo OCS(光交换)技术,正是一次从传统多级CLOS迈向Direct Mesh的关键跃迁,为支撑14万颗TPU v7乃至未来百万卡集群提供了标准化工程范本。
双万亿时代的物理瓶颈与系统重构
为应对指数级增长的模型复杂度,Google采用了异构双平面的组网架构来协同解决不同语义的通信需求:
- ICI后端网络(内存语义平面):采用专有的G-ICI协议,摒弃传统网络栈开销,专注于TPU芯片间张量并行与流水线并行的微秒级同步,实现跨芯片HBM内存的全局寻址。
- Jupiter DCN前端网络(存储与管控语义平面):不同于早期5层CLOS架构,2022年后引入OCS光交换核心层的Jupiter Evolving架构。它除了承担全局检查点读写和海量训练数据加载外,更依托Multislice全栈技术,承载跨Pod的数据并行与完全分片数据并行流量,实现了多租户环境下的全局资源调度与线性扩展。
Jupiter DCN物理网络架构:光电融合拓扑解析
Jupiter DCN是一套物理与逻辑高度解耦的以太网前端网络,与TPU内部的ICI后端专网物理隔离。它部署了73,728块400G DCN IPU网卡、4,608台12.8T ToR交换机、2,304台25.6T Leaf及2,304台25.6T Spine交换机,共同支撑起超大规模集群。
拓扑层级视图:基于Apollo OCS的分层解构
Google Jupiter DCN的核心变革在于引入光交换重构了传统拓扑,实现了从计算节点到光互联核心的完整数据路径。
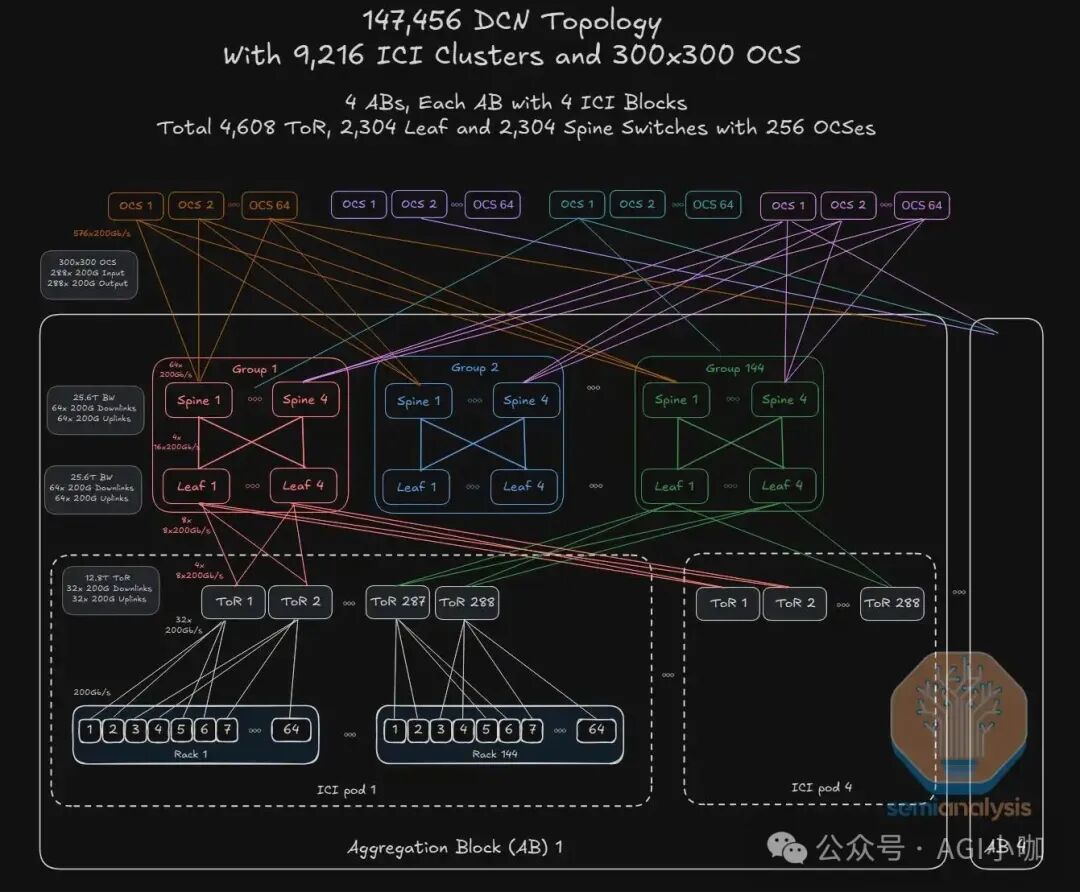
1. 联合Intel定制IPU网卡
作为最小接入单元,每个计算托盘集成4颗TPU v7芯片与1颗Host CPU。每个托盘配置2张Google与Intel联合定制的Titanium IPU网卡(基于Intel E2200 ASIC),每张卡提供2*200Gbps上行链路接入机柜顶部的ToR交换机。
2. 基于商用芯片自研电交换机
Google采用液冷高密机柜,每柜容纳16个托盘。采用双ToR冗余设计,基于Broadcom Tomahawk 3芯片的自研交换机作为ToR层,遵循1:1收敛比。Leaf与Spine层同样采用与ODM厂商合作的自研交换机,基于Broadcom Tomahawk 4芯片,全网共计部署2,304台Leaf与2,304台Spine。
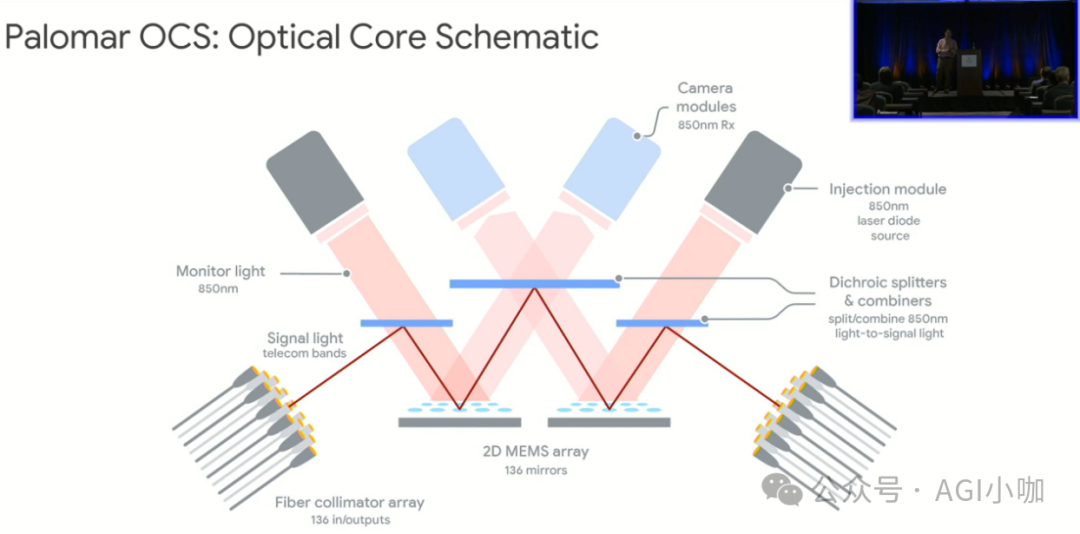
3. 基于MEMS的Apollo OCS全光交换矩阵
拓扑最顶端的4组共256台Apollo OCS是网络设计的核心亮点,标志着从CLOS架构转向以OCS为核心的Direct Mesh架构。基于3D MEMS镜片阵列技术,能实现300×300端口的全光动态调度。扁平化的光交换核心层极大地简化了架构,并实现了协议无关的透明传输。其波长与端口速率无关的特性,使得即使Spine层从400G升级至800G或1.6T,也无需更换核心OCS设备。
超大规模组网背后的架构设计亮点
1. 边缘计算单元:Titanium IPU与Host协同
在软件定义基础设施的实践中,Google与Intel深度合作,在Jupiter DCN中采用了基于Intel E2200定制的Titanium IPU网卡。该网卡将私有Falcon协议内置于芯片,集成线速加密与P4可编程流水线,将虚拟交换数据平面下沉,使每台TPU主机进化为具备边缘交换能力的高性能节点。
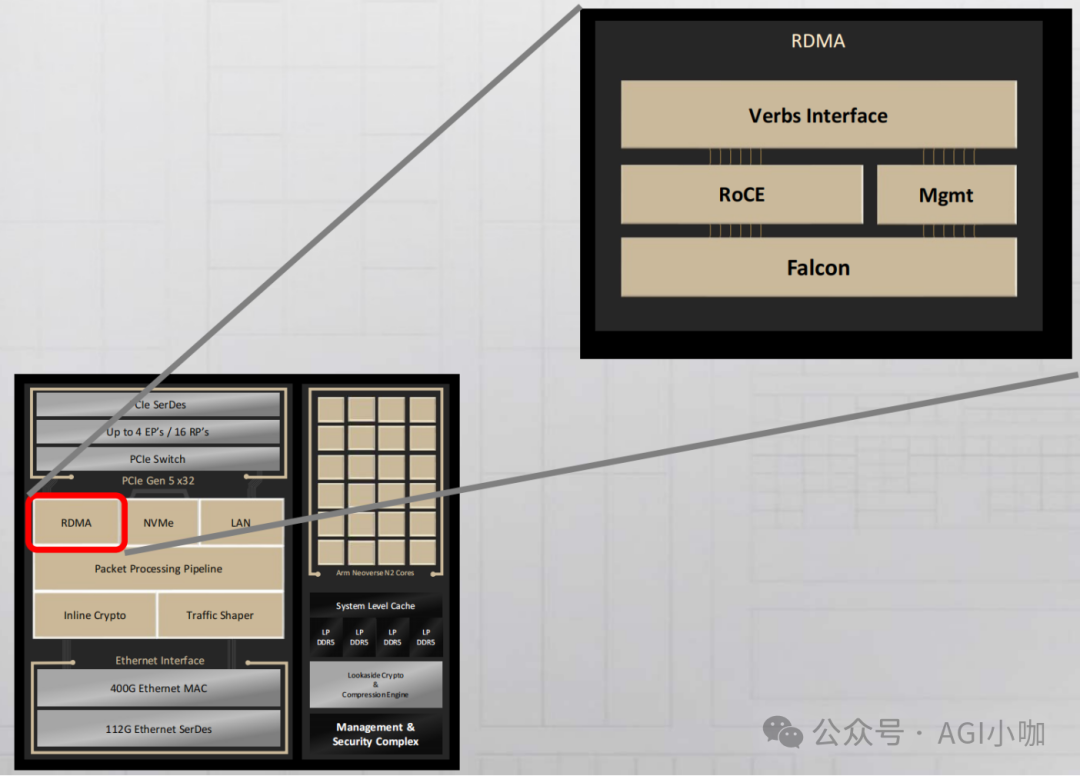
2. 交换网络:基于商用芯片的TCO优化策略
作为Broadcom的最大客户之一,Google享有芯片优先供应与深度定制权。但在Jupiter DCN中,基于200GE网络颗粒度与成本考量,务实选择了工艺成熟的TH3/TH4芯片。通过交由ODM厂商代工自研交换机的策略,剔除了品牌溢价,确保了万卡集群下的设备一致性与交付效率。
3. 核心交换:OCS光交换技术与架构重构
早期Jupiter网络采用5级Clos架构,随着规模突破十万级,电子交换的功耗、成本与布线复杂性成为瓶颈。2022年,Google实施了从CLOS全面转向以Apollo OCS为核心的Direct Mesh架构的重构。MEMS OCS替代了庞大的Super-Spine电交换层,其波长透明性克服了硬件迭代压力。OCS的引入赋予了网络动态重构与无感扩容能力,相比同等规模的InfiniBand方案,功耗降低30%-40%,在总TCO中占比不到5%。
DCN Overlay控制体系与全栈闭环
面对光路动态切换、大规模链路拥塞控制等挑战,Google通过Overlay层的感知、传输、接口到调度体系构建了精细化治理闭环。
1. 传输层 (Falcon):面向硬件卸载的协议设计
Falcon是专为配合Titanium IPU和OCS设计的传输协议,旨在替代TCP和传统RDMA。它原生支持逐包级多路径传输与数据包喷洒技术,消除了ECMP哈希不均问题。Titanium网卡内置乱序重排引擎与微秒级快速重传机制,确保了高性能与低延迟。
2. 感知层 (CSIG):高精度拥塞信号机制
为解决标准ECN无法定位拥塞点的问题,Google引入了CSIG机制。通过在L2.5层插入Shim Header,沿途交换机会实时更新其中的拥塞度量值与位置元数据。接收端网卡提取这些信息并通过ACK包回传,使发送端能精确感知拥塞位置与程度,从而进行精准的速率调整。
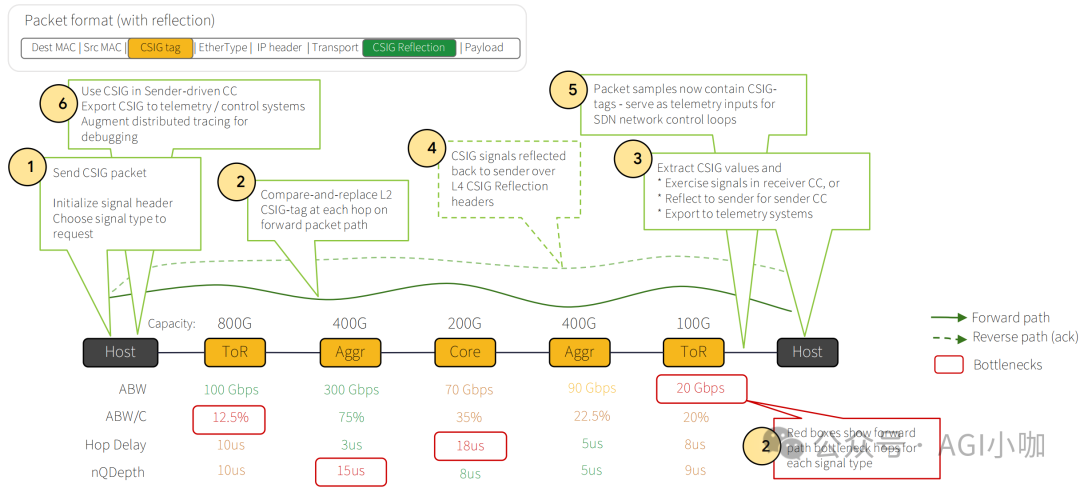
3. 调度与接口层 (Orion & SAI):全域SDN控制平面
为屏蔽底层ASIC差异,Google深度参与了OCP SAI标准的定义,所有控制指令通过标准化SAI接口下发,实现了真正的可编程确定性网络。Orion作为第二代SDN控制器,通过二分图匹配算法进行全局资源调度,深度协同光电交换:一方面向OCS下发指令物理重构拓扑,另一方面通知Falcon协议栈更新路由。针对AI训练流量,采用Rail-Aligned路由策略并结合Hedging算法,确保全网带宽高效利用。依托CSIG遥测数据,Orion实现了纳秒级负载感知与微秒级业务无损热维护,构建了端到端的流量治理闭环。
展望
Jupiter DCN以OCS光交换矩阵取代传统CLOS的Super-Spine层,协同Titanium IPU实现协议硬件卸载,融合CSIG纳秒级感知,构建了物理与逻辑解耦、调度深度协同的智算网络。这一架构从根本上突破了超大规模集群的布线与散热瓶颈。
产业生态上,TPU产能正指数级爬坡,并加速从“自用”走向“对外商用”。Meta与Google确立了基于TPU的混合部署战略,并联合启动TorchTPU项目,致力于通过PyTorch/XLA的深度优化打破AI框架与硬件的强耦合。
面向百万卡集群的互联挑战,Jupiter DCN的OCS架构展现了强大的技术韧性。尽管边缘电交换层将向更高容量迭代,但核心光交换层凭借其波长透明性可实现无感升级。未来,垂直光电融合、AI专用以太网与开放标准之间的技术路线竞争,将继续塑造超大规模AI基础设施的演进方向。
 发表于 2025-12-21 02:55:41
|
查看: 287|
回复: 0
发表于 2025-12-21 02:55:41
|
查看: 287|
回复: 0
