Anthropic研究团队联合帝国理工学院、爱丁堡大学及Constellation的研究人员,提出了一项名为选择性梯度掩码(Selective GradienT Masking,SGTM)的新技术。该技术通过在训练阶段将危险知识物理隔离到特定参数中并在随后剔除,实现了比传统数据过滤更优的安全性与通用能力平衡,其抗恢复性是现有方法的7倍。
这项研究直面大语言模型在安全领域的核心难题,即如何在保留人类通用知识的同时,彻底剥离关于化学、生物、放射性及核(CBRN)武器等危险领域的双重用途能力。它不仅揭示了传统数据过滤方法的局限性,更通过一种近乎外科手术般的参数隔离手段,为构建安全的超级模型提供了全新的技术路径。
数据过滤面临不可能三角困境
构建安全模型的传统思路非常直观,业界普遍采用数据过滤法,即在预训练阶段就把有害数据清洗掉。这种看似合理的逻辑在模型规模不断扩大的当下遭遇了严峻挑战。
首先,标注成本与准确性的矛盾难以调和。想要在海量文档中精准识别出所有涉及CBRN的内容,成本高昂且极易出错。任何微小的误判率都会导致海量的有害信息漏网或有益信息被误删。更棘手的是,有害内容往往隐藏在良性文档中,例如一本化学教科书中可能夹杂着关于有毒化合物合成的章节。若直接剔除整本书,模型将失去宝贵的化学常识;若保留,危险知识便随之潜入。
双重用途知识的纠缠特性使得彻底分离成为一种奢望。许多科学概念本质上是中立的,既可用于研发救命药物,也能用于制造致命毒素。这种知识的纠缠使得简单的二元分类失效。随着模型采样效率的提升,即便只有极少量的有害数据残留,大模型依然能够从中提取出危险能力。这导致了一种无法避免的权衡:要么接受模型包含危险知识的风险,要么通过过度激进的过滤牺牲模型的通用智能。
现有事后安全措施,如拒绝回答训练,虽然能阻止模型直接输出有害信息,但往往无法抵御坚定的对抗性攻击。攻击者总能找到绕过防御的方法,诱导模型释放其潜藏的危险能力。SGTM则不再试图在输入端完美区分数据,而是改变了模型存储知识的方式。
梯度掩码实现知识物理隔离
SGTM的核心理念源自梯度路由(Gradient Routing),即在模型训练过程中,人为地将特定类型的知识引导至特定的模型参数中。
研究团队将Transformer架构中的参数划分为两类:一类是负责存储通用知识的保留参数,另一类是专门用于存储危险知识的遗忘参数。这些参数具体分布在每一层Transformer块的注意力头和多层感知机神经元中。
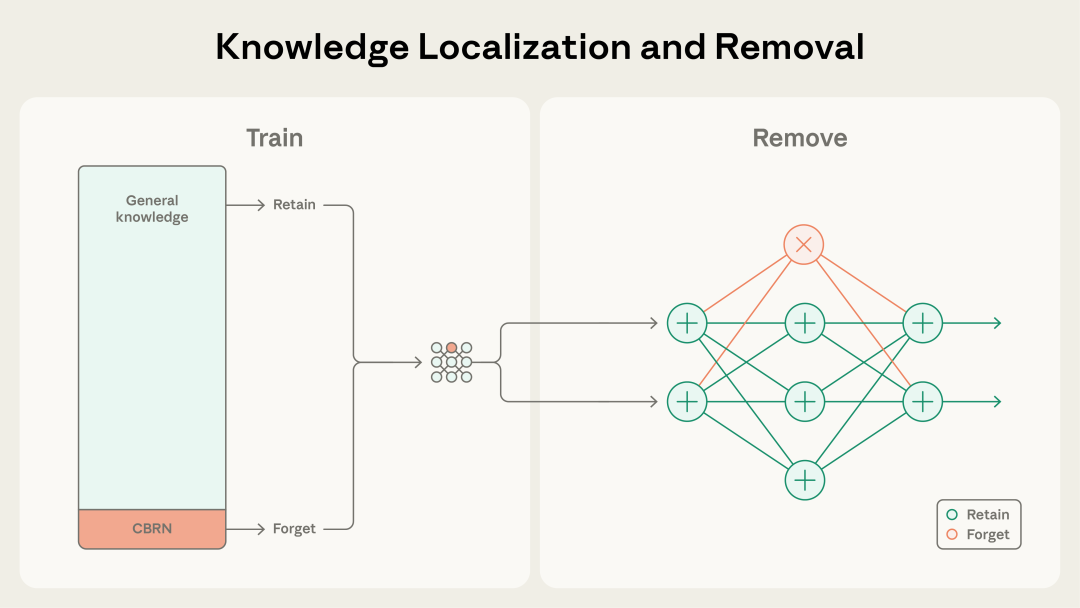
在训练过程中,当模型遇到被标记为危险的数据(如CBRN相关内容)时,SGTM会启动选择性梯度掩码机制。此时算法会强制将损失函数产生的梯度更新仅应用于那些被指定为遗忘参数的部分,而保留参数则被冻结或忽略。这相当于在模型的大脑中划定了一个隔离区,所有危险知识在进入模型时,都被强制路由并存储到了这个特定的区域,而通用知识则正常分布在保留参数中。
训练完成后,由于危险知识被物理隔离在特定的参数子集中,去除这些能力变得异常简单且彻底。研究人员只需将这些遗忘参数的权重清零或重置,就能精准地移除危险能力,同时最大程度地保留存储在其他参数中的通用能力。
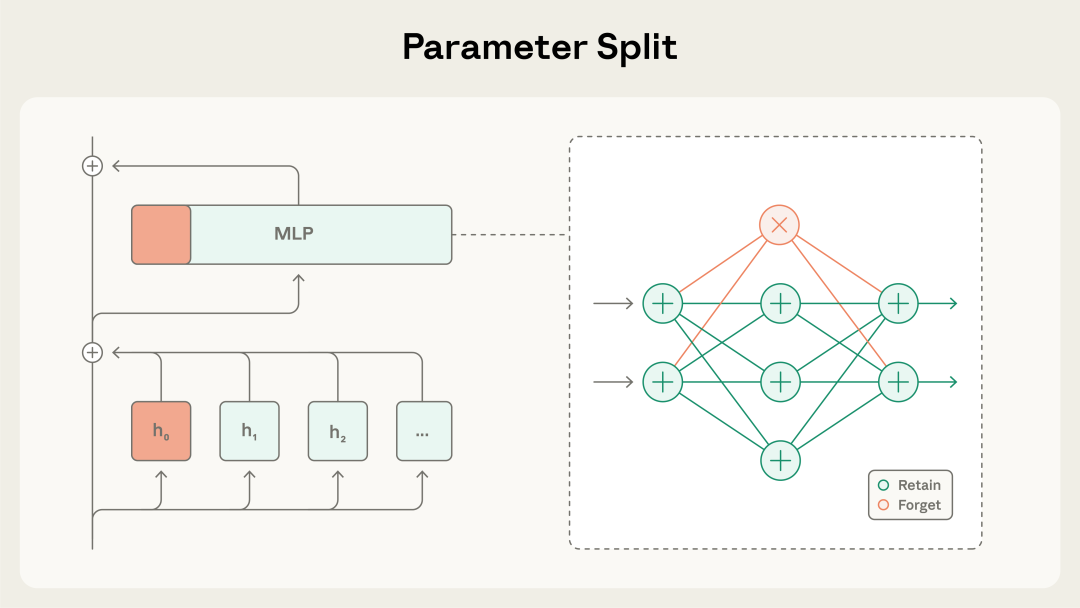
这种方法从根本上区别于传统的数据过滤。它允许模型阅读包含危险信息的文档,从而学习其中的通用语法、逻辑和背景知识,但将危险的核心要素隔离存储以便后续切除。
自强化吸收效应解决标注难题
SGTM最令人惊叹的特性在于其对未标记数据的处理能力,即所谓的“吸收效应”(Absorption)。
在实际应用中,我们不可能完美标记所有危险数据。SGTM利用了神经网络的一种内在动力学特性:一旦模型开始根据已标记的样本将危险知识定位到特定的遗忘参数中,一个自强化的过程便随之产生。这意味着,即使是未被标记的危险内容,在经过模型处理时,也会自然地倾向于激活并更新那些已经专门用于处理此类信息的遗忘参数。
研究团队通过梯度范数分析证实了这一现象。在双语TinyStories实验中,研究者将英语作为保留数据,西班牙语作为遗忘数据。
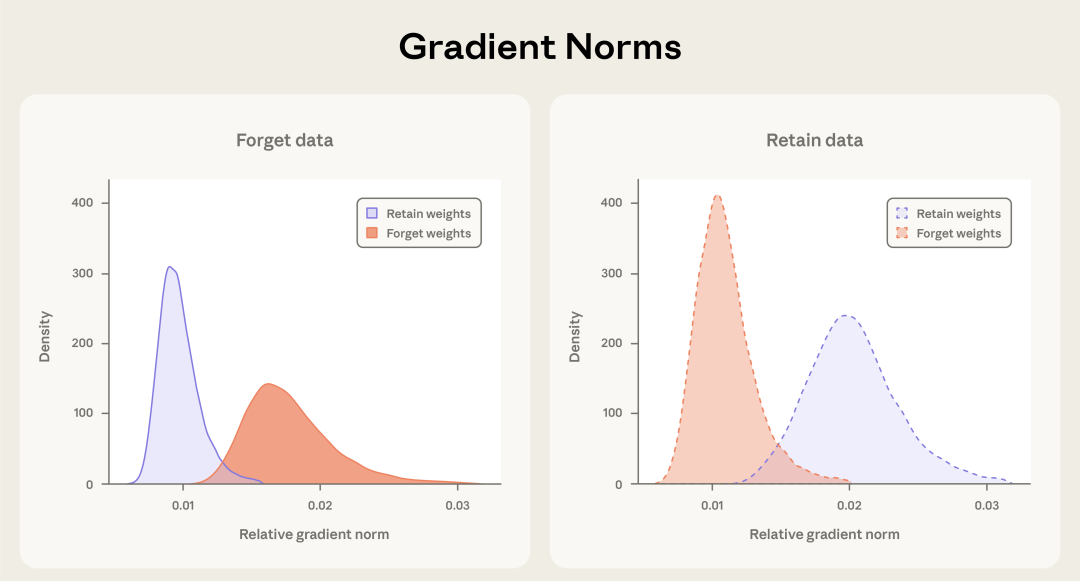
初期仅对部分标记数据应用梯度掩码。随后在处理未标记数据时,研究者发现,西班牙语数据产生的梯度更新自然而然地集中在了遗忘参数上,而英语数据则主要更新保留参数。这意味着模型内部建立起了专门处理特定领域知识的通路。这种特性赋予了SGTM极强的鲁棒性,即使训练数据存在大量标签噪声或遗漏,它依然能够有效地将危险知识隔离。这是传统数据过滤方法完全无法具备的优势。
暴力微调验证知识彻底清除
检验一种知识移除方法是否有效,最硬核的标准是看它在遭受恶意攻击试图恢复记忆时能坚持多久。目前流行的浅层遗忘学习方法,往往只是压抑了模型输出危险知识的倾向,并未真正清除相关权重。
研究团队对SGTM训练出的模型进行了残酷的对抗性微调测试,试图通过输入混合数据来恢复被移除的生物学知识。
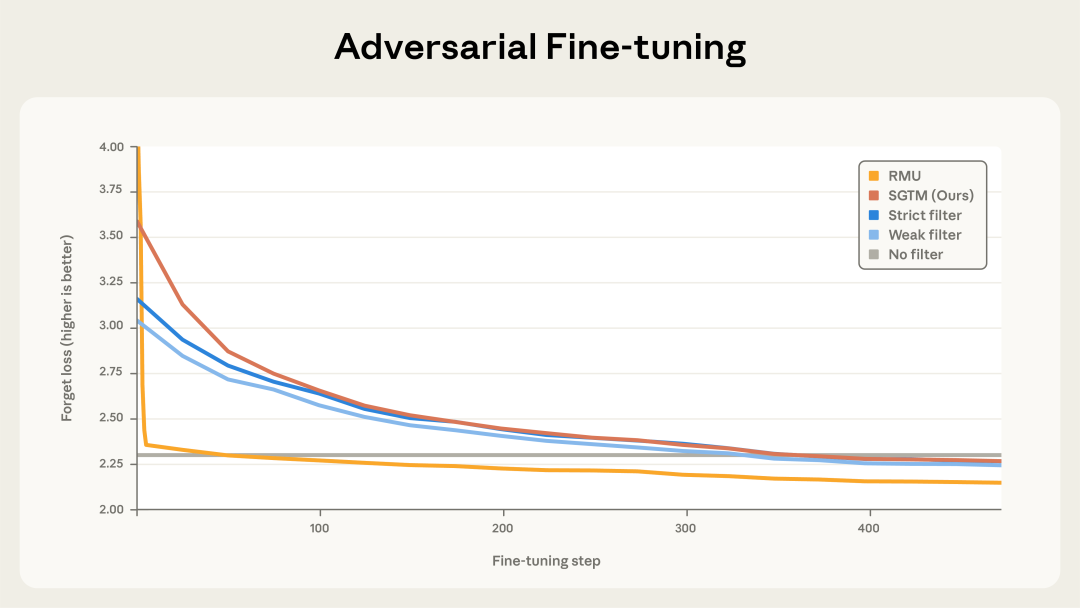
结果显示,传统的遗忘学习方法不堪一击,仅需50步微调,模型原本被移除的生物学能力就完全恢复到了基线水平。相比之下,SGTM展现出了惊人的抗恢复性。攻击者需要进行长达350步的微调,才能将模型的生物学能力恢复到基线水平,这一难度是传统方法的7倍。
这一数据证明SGTM不仅仅是抑制了知识的表达,而是真正实现了知识的物理移除。只有当攻击者通过微调重新向模型灌输大量新知识时,这种能力才会重新出现,这本质上已经是重新训练而非记忆恢复。
在与不同强度数据过滤的对比实验中,SGTM展现出了更优越的保留与遗忘权衡。
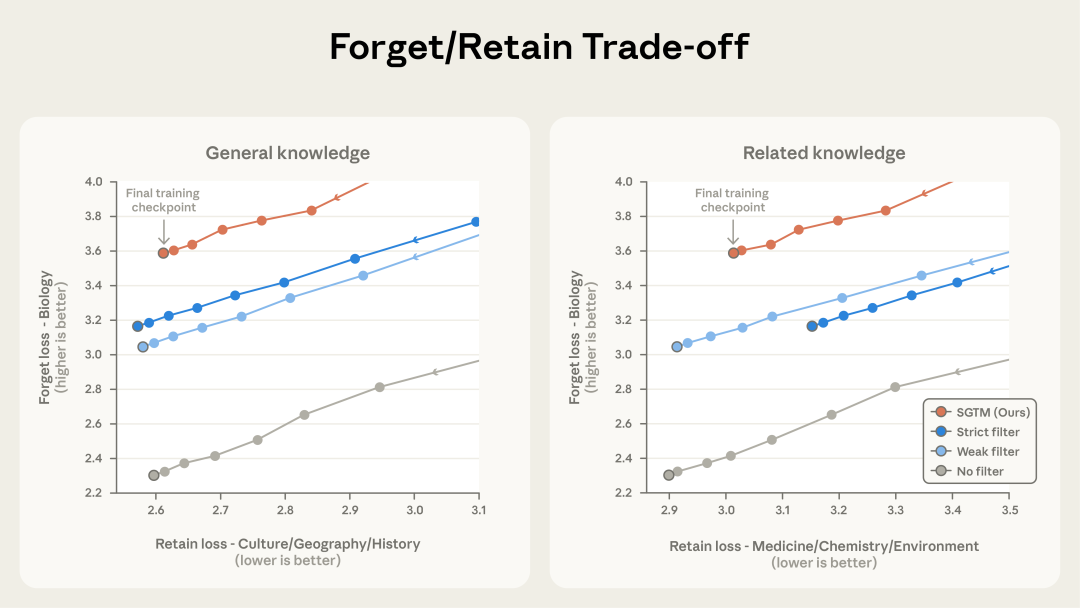
在相同的通用能力保留水平下,SGTM能更彻底地清除目标危险知识;而在相同的危险知识清除水平下,SGTM能保留更多相邻领域的有益知识。它避免了强过滤带来的“焦土政策”,也弥补了弱过滤在处理纠缠知识时的无力。
机制局限与未来防御图景
尽管SGTM在2.54亿参数规模的模型上取得了令人振奋的成果,但研究团队也指出了当前的局限性。实验尚未在更大规模的模型或混合专家架构上进行验证,其稀疏激活的特性是否会影响梯度路由的效果,仍需探索。此外,评估主要依赖于损失指标,未来需要引入更直接衡量危险能力的下游基准测试。
必须清醒地认识到,SGTM主要解决的是模型参数知识的安全性。它无法防御上下文攻击(In-context Attacks)。如果攻击者在提示词中直接提供了制造生化武器所需的全部详细步骤,即便模型本身不具备这些知识,它仍可能利用其强大的逻辑推理能力帮助攻击者梳理信息。因此,SGTM不能单打独斗,它必须与输入过滤、输出监控等防御措施结合,构成多层纵深安全防御体系。
SGTM为双模型部署提供了一种极具吸引力的可能性。由于该技术在训练阶段就已经实现了知识的物理分离,开发者可以仅通过一次训练,就同时获得两个版本的模型:一个包含完整参数的未删减版,供经过授权的安全人员或科研机构使用;另一个是经过参数切除的安全版,面向公众开放。这种“一次训练、双重产出”的模式,在算力成本高昂的今天,具有极高的经济价值和实用意义。
对于追求AGI安全的研究者而言,SGTM提供了一个重要的启示:与其试图清洗那片浩瀚且混乱的互联网数据海洋,不如重塑模型的大脑结构,让危险知识在进入的那一刻起,就被关进了可以随时丢弃的笼子里。
参考资料:
- Anthropic 研究博客: Selective Gradient Masking
- 研究论文: Selective Gradient Masking 预印本
- 开源代码: GitHub 项目地址
 发表于 2025-12-22 19:13:09
|
查看: 221|
回复: 0
发表于 2025-12-22 19:13:09
|
查看: 221|
回复: 0
