对于后端工程师而言,日常工作虽以业务逻辑、中间件和存储系统为主,但不可避免地会与数据仓库产生交集。理解数仓的核心概念与架构,能帮助我们在数据需求对接、问题排查和方案设计中更加得心应手。
本文将结合实践,从后端视角梳理数仓知识,主要分为离线数仓与实时数仓两大部分。
离线数仓
离线数仓是最经典的数据仓库形态。后端服务产生的业务数据、监控埋点及日志等,如需进行统计分析,通常需先离线采集至数仓,再通过SQL进行聚合查询。其核心在于对历史存量数据进行统计分析,并涉及合理的业务域划分、数据分层与数据分区。
数据采集
需采集的数据主要包括以下几类:
- 业务数据:通常存储在关系型数据库或HBase中。可先一次性导入存量数据至Hive表,后续通过定时任务扫描并同步增量数据。
- 监控埋点:后端服务发出的埋点消息,由采集程序消费、解析后,最终导入Hive表。
- 应用日志:可通过Filebeat等工具采集日志文件,经解析程序处理后导入Hive表。
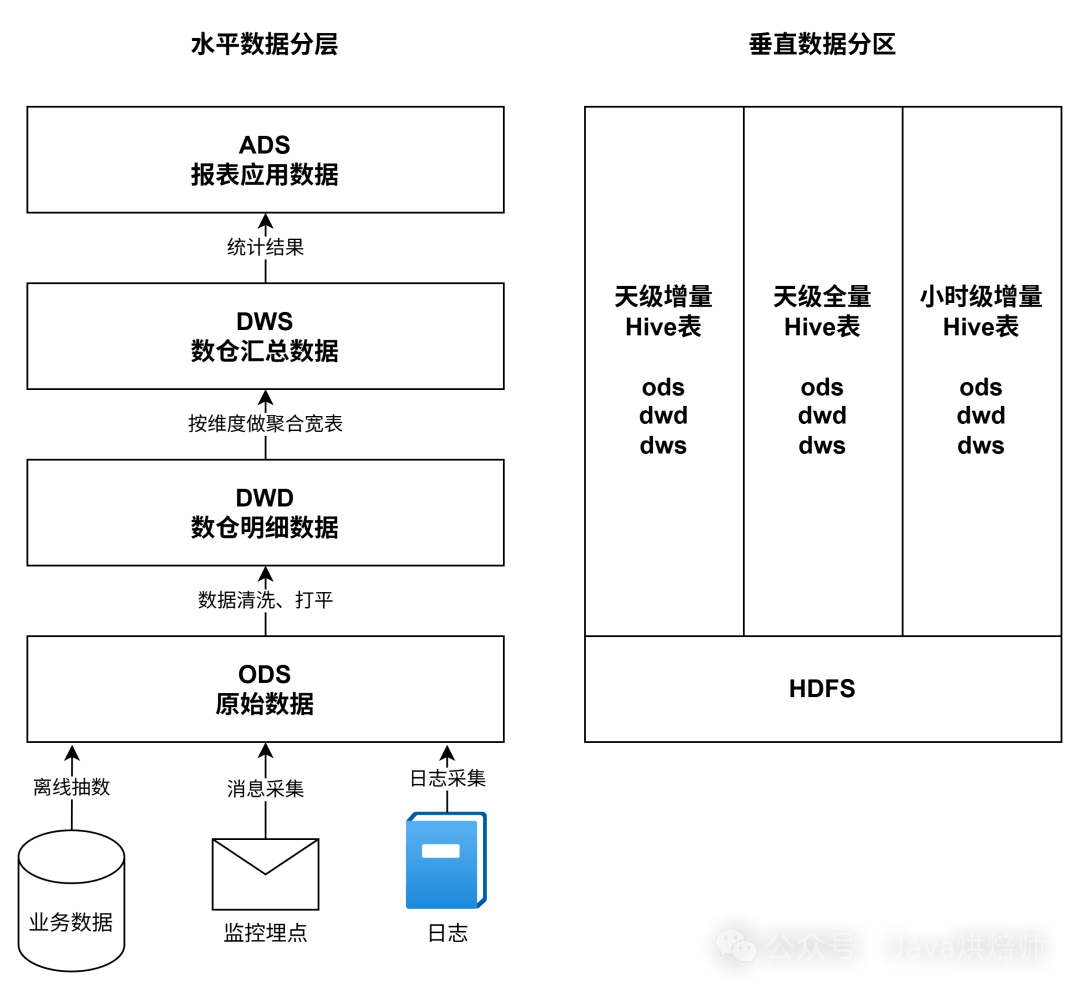
数据分层
在逻辑层面,数据通常会进行如下水平分层,这种设计与后端代码的分层架构(如接口层、服务层、数据访问层)思想相通,旨在隔离依赖、明确职责。
- ODS (Operational Data Store):原始数据层,存储未经加工的原始数据。
- DWD (Data Warehouse Detail):数据仓库明细层,在ODS基础上进行简单的数据清洗与加工,例如解析JSON字段、数据打平等。
- DWS (Data WareHouse Summary):数据仓库汇总层,在DWD层基础上,按业务维度进行聚合,形成宽表,以方便下游直接使用。
- ADS (Application Data Service):应用数据服务层,面向具体报表或应用的数据,可直接被查询使用。
数据分层的好处在于,变更可以被限制在单层内。例如,当业务数据库发生分库分表迁移时,只需调整ODS层的采集逻辑,DWD层及以上的表和下游应用均无需感知。同时,在DWD/DWS层完成数据聚合,能显著提升数据使用方的查询效率并降低其开发成本。
后端工程师接触较多的是ODS和DWD表:
- ODS表关联数据采集,并且是在线数据归档删除的前提保障。
- DWD表由于已将复杂字段(如JSON)打平,更适合用于历史数据的问题排查与筛选查询。
数据分区
为提升查询与管理效率,通常按时间维度进行垂直分区,分区粒度取决于调度频率:
- 天级增量表:包含某一天发生变更的数据记录。
- 天级全量表:包含某一天全部数据的完整快照。
- 小时级增量表:包含某一小时内发生变更的数据记录。
鉴于数据量巨大,并非所有离线表都会永久保留。例如,ODS层的天级增量表可能只保留最近N天或N个分区,而DWD层的天级全量表通过合并增量数据,可以查询到历史上的所有记录。
离线数仓典型应用场景
- 离线统计分析:通过Hive SQL执行复杂的关联与聚合查询(底层转换为MapReduce任务)。例如,将多张事实表与维度表进行关联(
JOIN),按特定维度进行计数、求和等聚合操作。事实表记录业务事件,用于统计;维度表则是描述性的元数据,用于分组分析。
- 数据对账:核对双方系统数据的一致性。
- 后端批量数据处理:当需要针对历史存量数据进行批量更新或修复时,通常先在数仓中筛选出符合条件的数据ID,再作为消息驱动后端任务执行。
后端数据归档与删除
随着业务发展,在线数据库不断膨胀,需要对已无需在线访问的历史数据进行归档清理。关键原则是:必须确保数据已被成功采集到离线数仓后,才能执行在线数据的物理删除。 一种常见的实践是,使用独立的archive_status字段(而非具有业务含义的deleted字段)标记归档状态。当该字段在数仓中被标记为特定值(如1)时,表明数据已安全落地,后端服务便可放心删除对应的在线记录。
实时数仓
既然已有离线数仓,为何还需实时数仓?
- 时效性需求:离线数仓的延迟通常在小时级,对于需要秒级甚至毫秒级延迟的业务场景(如实时监控、动态推荐),实时数仓成为必需。
- 在线业务赋能:实时数仓的产出结果可被后端服务低延迟查询,直接用于在线业务逻辑。
实时数仓的核心在于低延迟计算与精准一次(Exactly-Once)处理,与后端应用紧密结合能实现丰富的实时功能。
实时数仓构建流程
目前主流方案是使用 Apache Flink 将数据采集、计算和导出流程串联起来。下图引自某云厂商实践,其存储组件可替换为其他同类产品(如Doris、ClickHouse)。
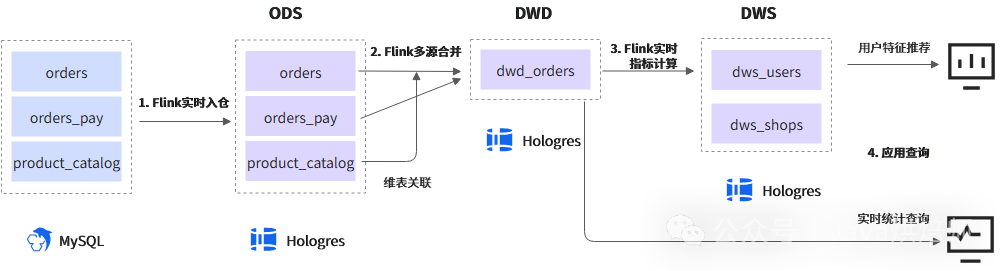
- 实时入仓:通过捕获MySQL的Binlog或直接接收业务事件消息,形成实时数据流,经由Flink写入实时数仓ODS层。
- 实时计算:在Flink中关联多个ODS表,生成DWD明细层数据,进而进行窗口聚合等计算,产出DWS汇总层数据。
- 数据服务化:计算结果可导出至专为实时查询优化的数据库(如Doris、Hologres),也可导出至MySQL、Redis等在线存储。随后封装成RPC或HTTP接口,供后端服务进行高QPS查询。
实时数仓典型应用场景
- 内部实时报表看板。
- 面向用户的实时统计:如实时排行榜、商品实时浏览量/收藏量/购买人数等。
- 用户个性化实时推荐。
掌握离线与实时数仓的基本原理、架构与适用场景,有助于后端工程师更好地进行系统设计与协作,在数据驱动的业务中构建更稳固、高效的技术底座。 |  发表于 2025-12-24 00:47:21
|
查看: 209|
回复: 0
发表于 2025-12-24 00:47:21
|
查看: 209|
回复: 0
