

SGLang社区推出了一款名为miniSGLang的轻量化AI推理框架,它使用约五千行Python代码和少量C++代码,实现了完整的大语言模型(LLM)推理功能。相较于拥有十万行代码的完整版SGLang,miniSGLang结构简洁、易于阅读,是理解相关核心概念的绝佳切入点。
本文将结合相关示例,对miniSGLang的框架结构、核心原理与使用方法进行展开介绍。
1. 框架结构
miniSGLang的框架可以分为三层。在其官方文档的架构图基础上,我们可以进一步展开“Forward”模块的内部细节,如下图所示:
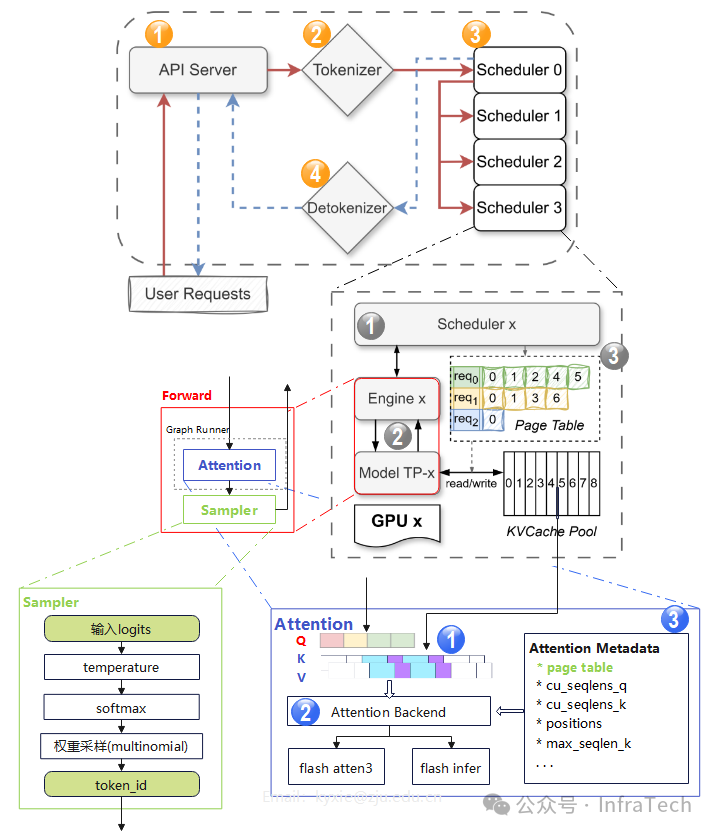
1.1 主要元素(顶层)
框架顶层主要包括运行在四个独立进程中的关键元素:
- 前端服务 (API Server):用户请求的入口。它提供一个与OpenAI兼容的API接口(例如
/v1/chat/completions),用于接收提示词(prompt)并返回生成的文本。
- 文本转Token (Tokenizer Worker):将输入文本转换为模型可以理解的数字序列(Token ID)。
- 调度执行器 (Scheduler Worker):核心工作进程。在多GPU设置中,每个GPU(称为一个TP Rank)都运行一个Scheduler Worker,负责管理该GPU的计算和资源分配。
- Token转文本 (Detokenizer Worker):将模型生成的数字序列(Token ID)转换回人类可读的文本。
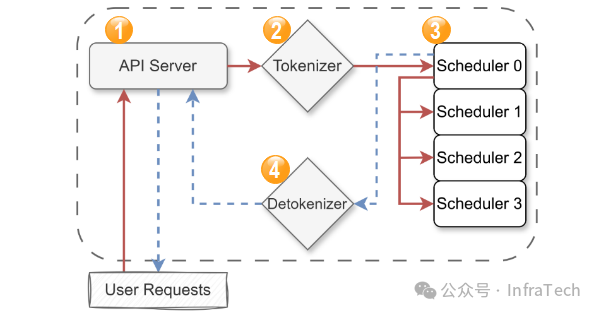
数据计算流程
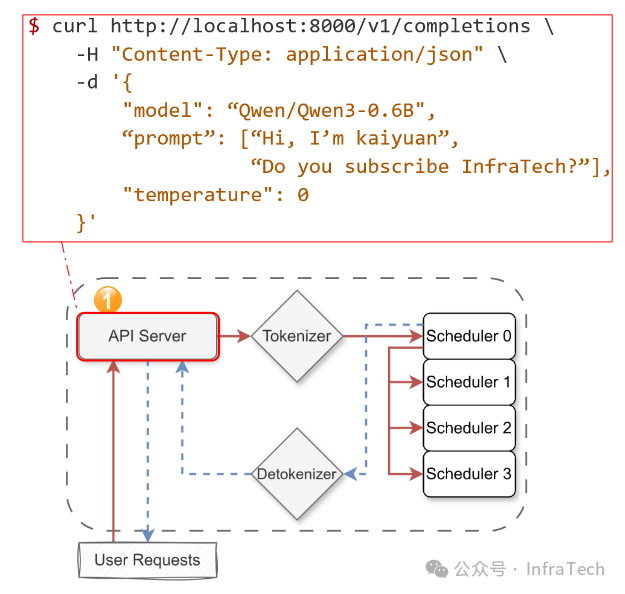
步骤1:用户向API Server发送请求。例如,下图展示了一个符合OpenAI格式的curl请求。
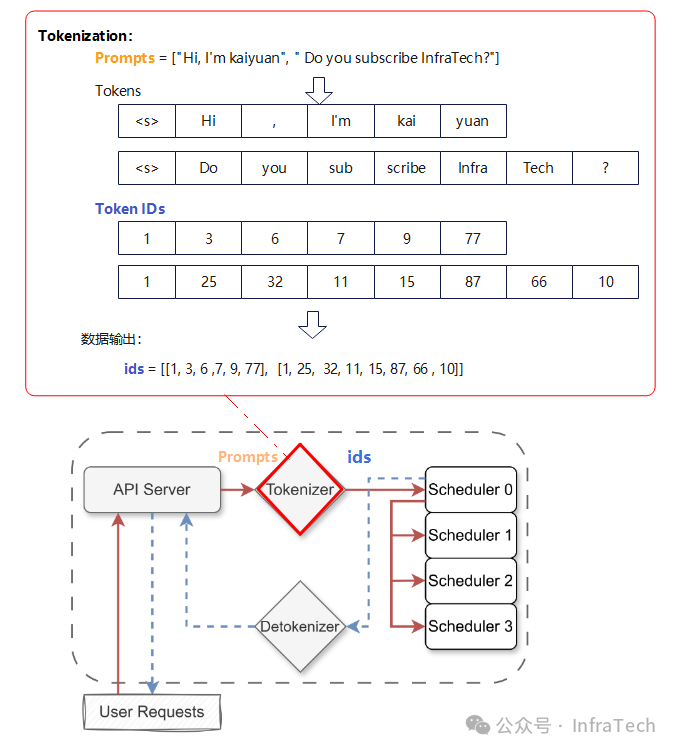
步骤2:Tokenizer将接收到的提示词(prompt)转换为Token ID序列,并将这些ID发送给主调度器(Scheduler 0 / Rank 0)。
步骤3:Scheduler触发引擎(Engine)进行前向计算(Forward),最终通过采样得到新的Token ID。在多GPU模式下,Scheduler 0(Rank 0)会将请求广播给其他Scheduler(Rank 1 ~ N),待前向计算完成后,再将数据收集回来。
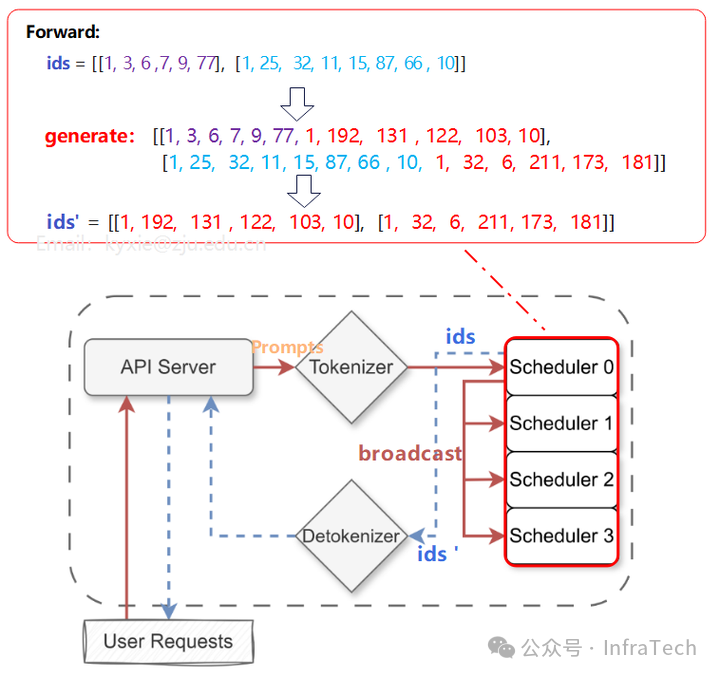
步骤4:Detokenizer接收到来自Scheduler(Rank 0)的Token ID后,将其转换回文本。
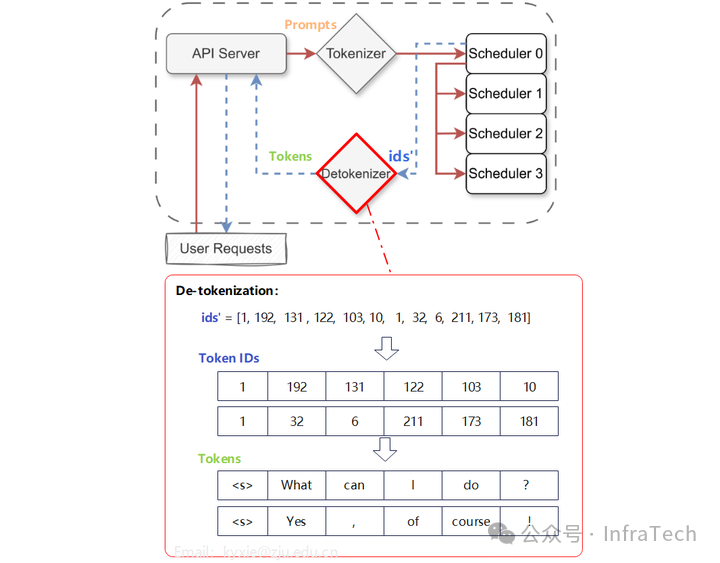
最终,API Server将结果以流式方式输出给用户。
1.2 调度引擎
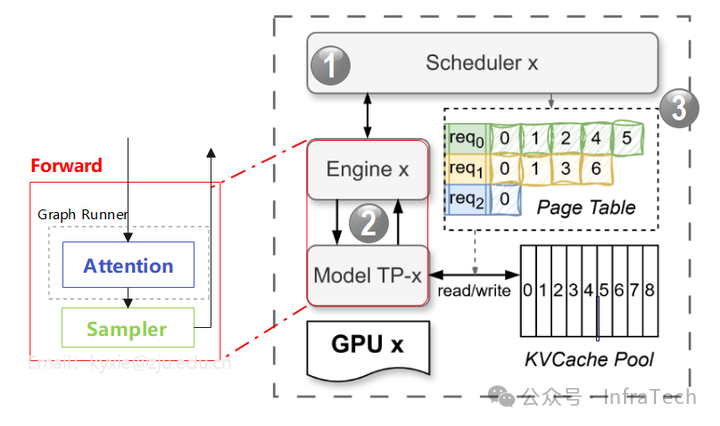
顶层的Scheduler模块内部可进一步拆分为三个核心部分:
- 调度器 (Scheduler):为请求任务分配计算与存储资源,下发任务,并协调引擎(Engine)与KV缓存模块的工作。
- 引擎 (Engine):执行具体的前向计算。负责管理模型、上下文、物理KV缓存、注意力计算后端以及CUDA计算图。在多GPU模式下,每个TP Worker运行一个Engine实例。
- KV缓存模块:基于基数树缓存(Radix Cache)原理管理KV缓存。主要由两个类实现功能:
KVCachePool(统一的缓存池,所有请求的KV缓存均从中申请)和KVCacheManager。
Scheduler应用的关键技术:
- 分块预填充 (Chunked Prefill):将大的预填充请求分割成更小的块执行,从而降低峰值显存占用。
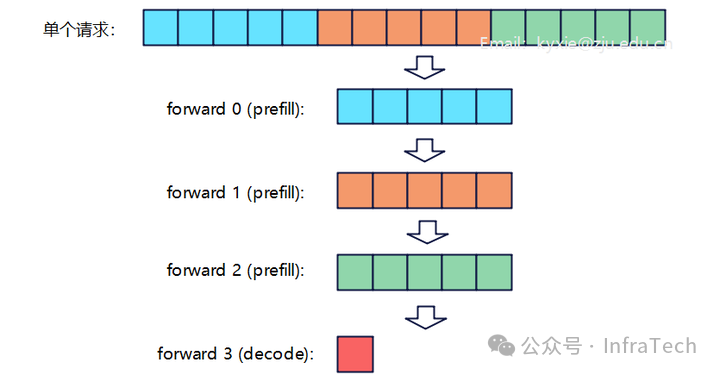
Chunked Prefill示意图
- 重叠调度 (Overlap Scheduling):为了降低CPU侧的调度开销,让CPU的调度工作与GPU的计算任务在时间上重叠进行。

KV缓存管理应用的关键技术:Radix Cache
Radix Cache是SGLang设计之初的一项关键技术,旨在通过高效复用KV缓存中的历史数据,显著降低重复计算。其具体原理可参考相关论文。
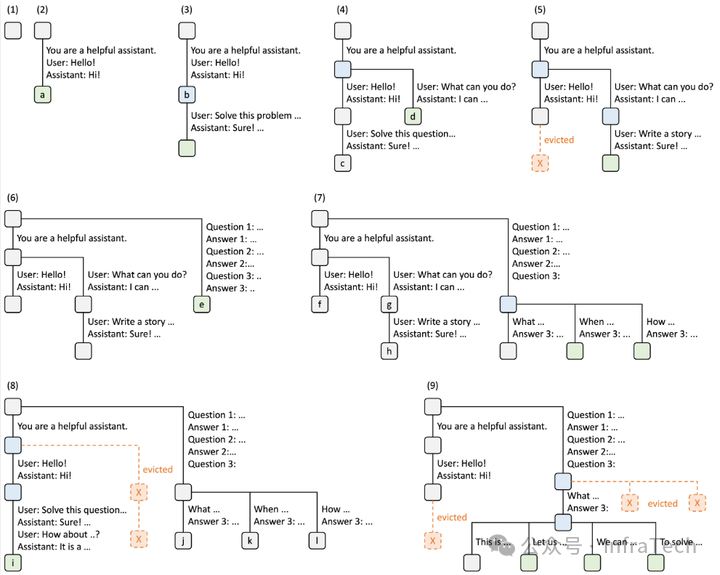
1.3 前向运算
前向运算位于Engine内部,主要包括模型的前向计算(如Attention、FFN等)和采样(Sampling)过程。
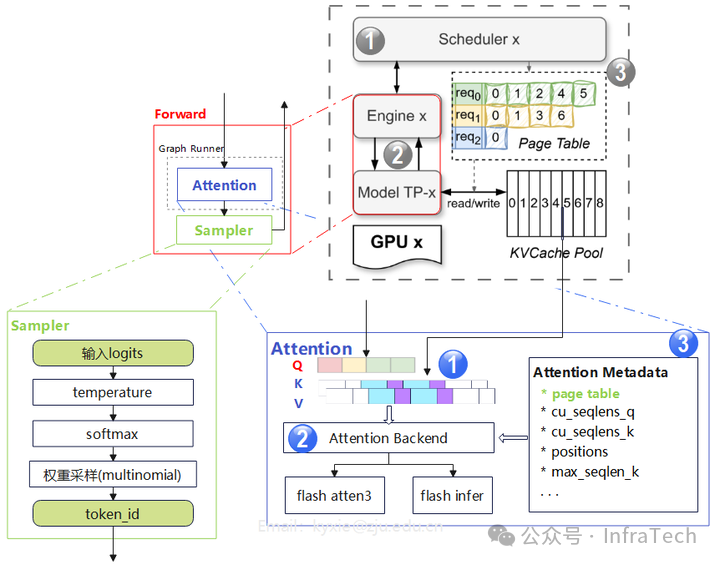
Attention运算模块包含三个关键要素:
- QKV数据:其中KV值由KV Cache Pool中的历史数据与新计算的KV值共同组成。
- 计算后端 (Backend):根据配置执行特定的注意力算子。目前支持Flash Attention 3和Flash Infer两种后端。
- 元数据 (Metadata):包含页表(page table)、位置信息等,确保注意力算子能准确读取对应请求的QKV数据。
Sampler采样器当前仅支持温度调节,TopK、TopP、惩罚等其他采样方法暂未实现。
Forward中应用的关键技术:CUDA Graph
通过CUDA Graph的捕获与重放机制,能够有效降低解码阶段的CPU指令下发开销。相关实现在GraphRunner中。
2. 代码结构与使用
2.1 代码的模块组织结构

除了第1节提到的核心模块外,代码库中还有几个重要部分:
minisgl.distributed:实现分布式并行所需的函数,如用于张量并行(TP)的all-reduce、all-gather操作。minisgl.llm:提供一个统一的Python接口,可用于离线(offline)推理模式。minisgl.kernel:执行自定义的CUDA内核。minisgl.benchmark:提供模型性能测试工具。
其中,LLM模块的离线推理使用示例如下:
import time
from random import randint, seed
from minisgl.core import SamplingParams
from minisgl.llm import LLM
def main():
seed(0)
num_seqs = 256
max_input_len = 1024
max_output_len = 1024
# 初始化LLM实例
llm = LLM(
"Qwen/Qwen3-0.6B", max_seq_len_override=4096, max_extend_tokens=16384, cuda_graph_max_bs=256
)
# 生成随机输入
prompt_token_ids = [
[randint(0, 10000) for _ in range(randint(100, max_input_len))] for _ in range(num_seqs)
]
sampling_params = [
SamplingParams(temperature=0.6, ignore_eos=True, max_tokens=randint(100, max_output_len))
for _ in range(num_seqs)
]
# 预热
llm.generate(["Benchmark: "], SamplingParams())
# 性能测试
t = time.time()
llm.generate(prompt_token_ids, sampling_params)
t = time.time() - t
total_tokens = sum(sp.max_tokens for sp in sampling_params)
throughput = total_tokens / t
print(f"Total: {total_tokens}tok, Time: {t:.2f}s, Throughput: {throughput:.2f}tok/s")
main()
2.2 安装与使用
代码库的README中提供了安装及两种使用方式:API服务调用和交互式Shell。若需调试代码,可参考2.1节的离线模式。
# 环境准备:
# 创建虚拟环境 (推荐 Python 3.10+)
uv venv --python=3.12
source .venv/bin/activate
# 安装miniSGLang:
git clone https://github.com/sgl-project/mini-sglang.git
cd mini-sglang && uv venv --python=3.12 && source .venv/bin/activate
uv pip install -e .
# 使用方式1 (启动OpenAI兼容的API服务):
# 在单GPU上部署 Qwen/Qwen3-0.6B
python -m minisgl --model "Qwen/Qwen3-0.6B"
# 在4个GPU上使用张量并行部署 meta-llama/Llama-3.1-70B-Instruct,端口30000
python -m minisgl --model "meta-llama/Llama-3.1-70B-Instruct" --tp 4 --port 30000
# 使用方式2 (启动交互式Shell):
python -m minisgl --model "Qwen/Qwen3-0.6B" --shell
测试效果
官方提供了mini-SGLang与nano-vLLM的对比数据,以及与完整版SGLang的对比测试。此处我们重点看其与SGLang的对比结果。
- 测试条件:
- 硬件: 4x H200 GPU,通过NVLink连接。
- 模型: Qwen3-32B
- 数据集: Qwen trace,重放前1000个请求。
- 评估指标:
- TTFT (首Token时间): 衡量预填充性能。
- TBT (Token间时间): 衡量解码性能。
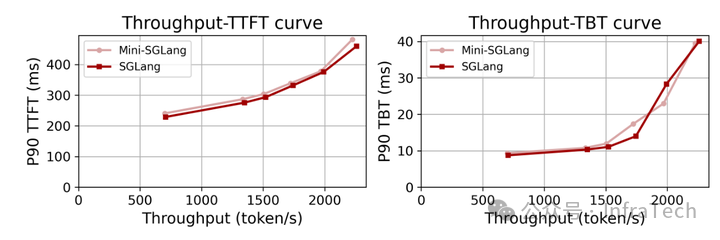
在所述测试条件下,mini-SGLang的性能表现与完整版SGLang相当。
总结
mini-SGLang作为SGLang的精简实现,保留了其核心架构与关键技术模块,代码结构清晰简洁,极大地降低了学习大型语言模型推理框架的门槛,非常适合初学者用于理解相关核心概念。当然,由于许多高级特性尚未实现,若要深入研究和应用于生产环境,仍需回归完整的SGLang项目。
 发表于 2025-12-24 02:41:44
|
查看: 369|
回复: 0
发表于 2025-12-24 02:41:44
|
查看: 369|
回复: 0
