高级DSL(如Triton)的本质,是将高层次的算子描述,通过多级下降(lowering)最终转化为能够在GPU上执行的CUDA内核(PTX或cubin)。要理解这个过程,我们不妨先从标准的NVCC编译链路入手,梳理从源码到可执行文件的完整路径,然后再对照Triton的编译流程,从而清晰地看到高级DSL是如何最终落到GPU硬件上运行的。
CUDA编译流程详解
与CPU基于已发布的固定指令集架构不同,GPU架构处于快速迭代中,难以保证严格的二进制兼容性。为此,NVCC采用了一种巧妙的两段式编译模型来解决这个问题。
其核心思想是从CUDA源码先编译到PTX中间代码,再生成最终的cubin二进制。PTX可以看作是一种虚拟的GPU架构汇编语言,它并不直接对应某一代具体硬件,其角色类似于Java字节码,是一种硬件无关的中间表示。而cubin则是针对特定GPU代际(如SM70, SM80)优化后的原生机器码。在NVCC的术语中,我们常用 compute_xy 来表示PTX的架构版本,而用 sm_xy 来表示cubin的目标硬件架构。

整个CUDA的编译流程可以概括为:输入程序首先经过“设备编译”预处理,被编译为CUDA二进制文件(cubin)和PTX中间代码,这些内容会被打包进一个称为“胖二进制(fatbinary)”的文件中。随后,输入程序会进行“主机编译”预处理,通过代码合成将fatbinary嵌入到主机代码中,并将CUDA特有的C++扩展(如<<< >>>)转换为标准C++结构。最后,C++主机编译器将嵌入了fatbinary的合成主机代码编译成主机对象文件。具体步骤如下图所示。
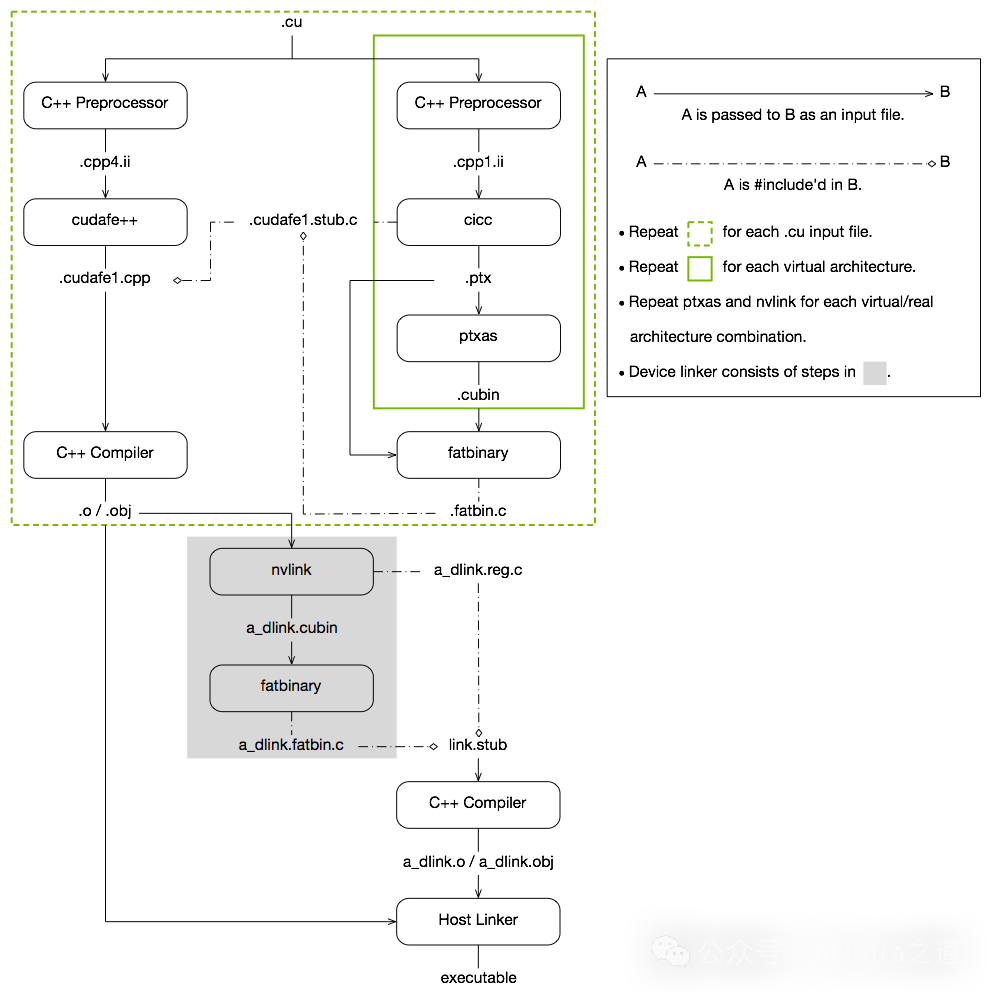
每当主机程序启动设备代码时,CUDA运行时系统会检查嵌入的fatbinary,从中提取适用于当前GPU的镜像(可能是预编译的cubin,也可能是需要即时编译的PTX)来执行。
C++预处理器(C++ Preprocessor)
CUDA中间编译器(cicc)
// vector_add.ptx 内容示例
.version 7.6
.target sm_70
.address_size 64
.visible .entry vectorAdd(
.param .u64 vectorAdd_param_0,
.param .u64 vectorAdd_param_1,
.param .u64 vectorAdd_param_2,
.param .u32 vectorAdd_param_3
){
.reg .pred %p<2>;
.reg .b32 %r<10>;
.reg .b64 %rd<11>;
// ... PTX指令
ld.param.u64 %rd1, [vectorAdd_param_0];
ld.param.u64 %rd2, [vectorAdd_param_1];
// ... 更多指令
}
PTX作为GPU无关的虚拟指令集,为不同代际的GPU架构提供了统一的编程接口和中间表示,是理解[编译器](https://yunpan.plus/f/36-1)跨平台兼容性的关键。
### PTX汇编器(ptxas)
* **输入**:`.ptx`(GPU虚拟指令)
* **输出**:`.cubin`(GPU原生二进制)
* **作用**:将PTX转换为针对特定GPU架构(如SM80、SM90)的机器码。这一过程会执行寄存器分配、指令调度等底层的硬件优化,生成GPU可直接执行的二进制文件。
```bash
nvcc -cubin vector_add.cu -o vector_add.cubin -arch=sm_70
胖二进制生成器(fatbinary)
- 输入:
.ptx、.cubin
- 输出:
.fatbin.c文件(包含多个GPU架构代码的集合)
- 作用:
- 将针对不同架构(
sm_xy)编译得到的多个.cubin文件,以及作为“后备”的.ptx文件,打包成一个单一的“胖二进制”文件。
- fatbinary机制是CUDA生态实现“一次编译,多处执行”的关键。它在编译时预置了针对主流架构的高性能代码,同时在运行时通过PTX JIT编译来兼容未来或未预置的新设备,巧妙平衡了性能与灵活性。(得益于缓存机制,PTX JIT通常只增加首次启动的耗时)。
nvcc -gencode arch=compute_50,code=sm_50 \
-gencode arch=compute_60,code=sm_60 \
-gencode arch=compute_70,code=sm_70 \
vector_add.cu -o vector_add.fatbin.c
CUDA前端(cudafe++)
- 输入:
.cpp4.ii(主机分支)
- 输出:
.cudafe1.stub.c(设备代码存根)、.cudafe1.cpp(最终主机代码)
- 作用:处理CUDA特有的语法(如
<<< >>>核函数启动配置),将设备代码的引用和fatbinary嵌入到主机代码中。.cudafe1.stub.c是一个中间文件,存储了设备代码的符号信息,具体实现则指向.fatbin.c中的内容。这一步主要处理主机侧的代码逻辑。
C++编译器与主机链接器
此外,在上图流程的阴影部分,nvlink和fatbinary工具还负责将多个.cu文件编译出的模块链接在一起,并生成统一的胖二进制文件,这对于复杂的C++项目尤为重要。
CUDA编译的中间文件类型

需要注意的是,NVCC本身不区分对象文件(.o)、库文件(.a/.lib)或资源文件。在链接阶段,它只是简单地将这些文件传递给下游的主机链接器进行处理。
Triton编译流程剖析

与NVCC针对CUDA C++的编译不同,Triton作为高级DSL,其编译器管线也更为专精:
- 前端(Frontend):将用户用Python编写的Triton Kernel转换为高级的、硬件无关的Triton IR。
- 优化器(Optimizer):通过一系列编译Pass,将Triton IR逐步转换并优化为针对GPU硬件的TritonGPU IR。
- 后端(Backend):将TritonGPU IR进一步降级(lower)为标准的LLVM IR。对于NVIDIA显卡,最终通过LLVM的后端生成PTX或cubin。
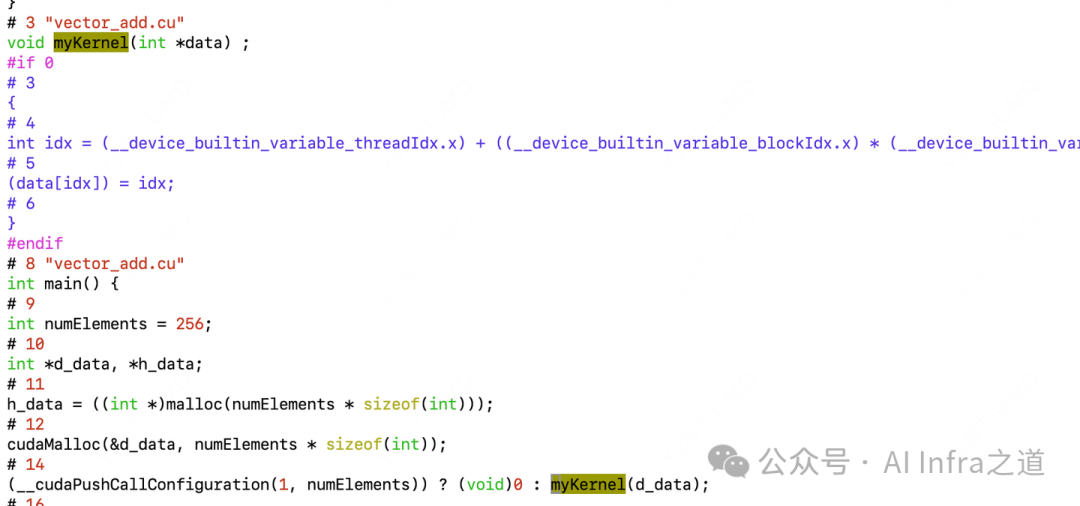
我们以Triton官方教程中的向量加法示例01-vector-add.py在NVIDIA GPU上的编译过程为例。运行该Kernel后,会在缓存目录(如~/.cache/triton)中生成一系列中间文件,这些既是编译过程的产物,也是运行时用于加速的缓存。


Triton IR (add_kernel.ttir)
这是与硬件无关的高级中间表示,用于表达计算逻辑。其特点包括:
- 高级抽象:允许开发者用接近Python/NumPy的语义描述张量计算。
- 操作丰富:包含矩阵乘法、卷积、元素级运算等深度学习常用算子。
- 高级优化:在此层级可进行死代码消除、常量传播等与硬件无关的优化。
- 转换起点:它是向更低层IR(如TritonGPU IR)转换的起点。
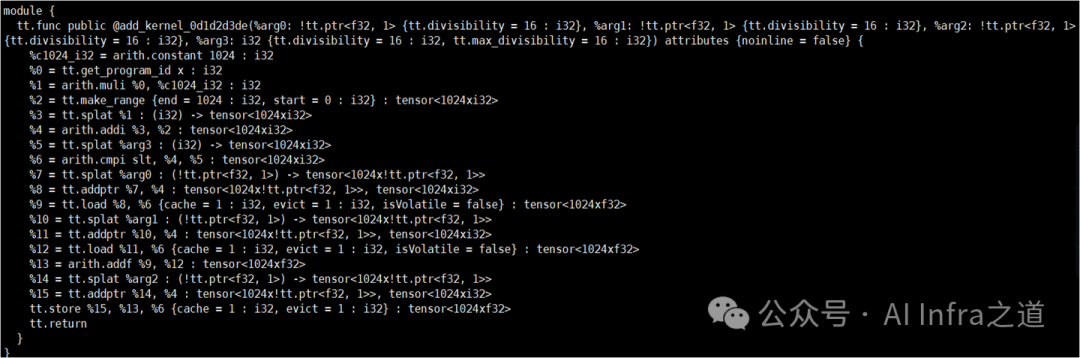
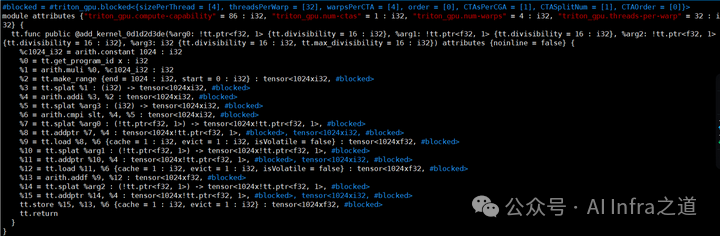
TritonGPU IR (add_kernel.ttgir)
这是专门针对GPU架构进行优化的低级中间表示。其特点包括:
- 硬件特定优化:引入了线程块、线程束(Warp)、内存层次结构(共享内存、全局内存)等GPU概念,并进行相关优化。
- 并行性显式表示:明确表示了数据并行和任务并行的模式。
- 转换桥梁:它可以相对直接地被转换为LLVM IR,以便利用成熟的LLVM工具链。
LLVM IR (add_kernel.llir)
- 平台无关:LLVM IR是成熟的、支持多后端的中间语言。
- 大量优化:可以利用LLVM庞大的优化器(Optimizer)进行低层级的指令级优化。
- 代码生成:通过LLVM的NVPTX后端,可以将LLVM IR转换为NVIDIA GPU的PTX汇编代码。
- 模块化结构:清晰地表征函数、全局变量等程序结构。
生成PTX与Cubin
- NVPTX后端:LLVM的NVPTX后端根据设置的目标特性(target features),将LLVM IR代码生成(codegen)为PTX汇编代码(
.ptx文件)。
- Cubin文件:Triton通常会调用NVIDIA的
ptxas汇编器,将PTX汇编成最终的cubin二进制。Triton会直接缓存cubin的字节流,在执行时通过CUDA Driver API动态加载。
核心差异:编译时链接 vs. 运行时加载
到这里,Triton Kernel已经变成了可以在GPU上执行的cubin代码。我们观察到,Triton的流程在生成cubin后便停止了,并没有像NVCC那样继续进行fatbinary打包、cudafe++合成主机代码、以及最终链接成可执行文件的过程。
这是为什么呢?根本原因在于两者的使用模型不同:
- NVCC:编译的是完整的、独立的CUDA C++程序,需要生成一个包含主机逻辑和设备代码的可执行文件。其过程是“编译时静态链接”。
- Triton:作为嵌入在Python环境中的DSL,其主机侧的控制逻辑(即Triton Runtime,一个预先编译好的C++扩展)是固定且可复用的。每次定义新的Kernel时,只需要编译设备端的计算逻辑。其过程变成了“运行时动态加载”:
生成cubin → CUDA Driver API加载模块(driverLoadModule)→ 获取函数指针(getFunction) → 启动核函数(launch)。
这种设计使得Triton能够实现极快的迭代速度,因为不需要每次修改Kernel都重复编译庞大的主机运行时代码,这正是其在AI模型开发和调优场景下的一大优势。希望本次对两种编译链路的剖析,能帮助你更好地理解GPU高性能计算背后的工作原理。如果你想与更多开发者交流此类底层技术,欢迎来到云栈社区参与讨论。
 发表于 2026-2-4 03:16:44
|
查看: 237|
回复: 0
发表于 2026-2-4 03:16:44
|
查看: 237|
回复: 0
