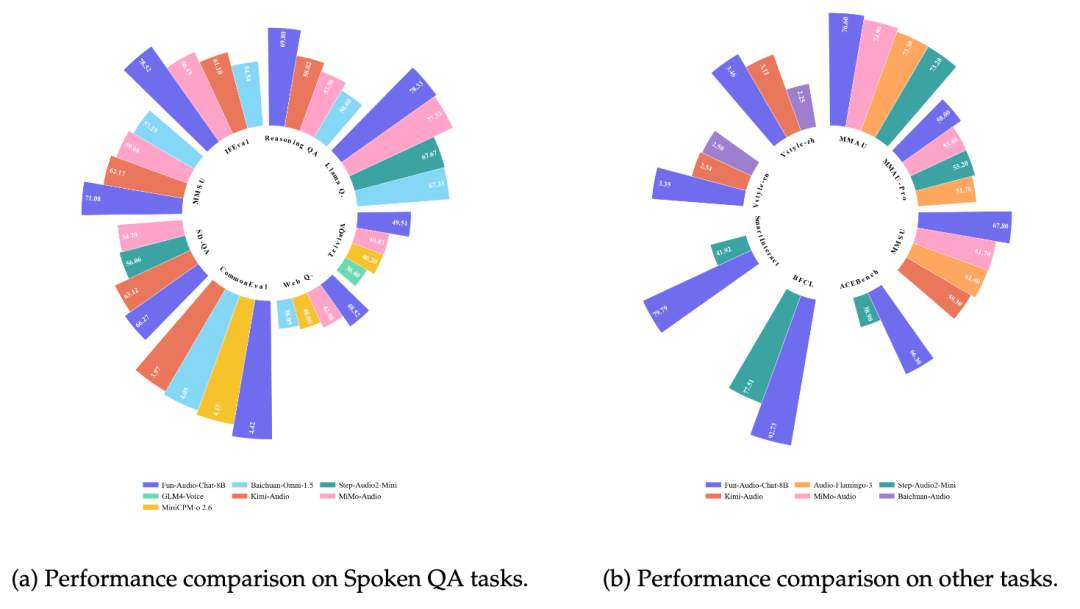
通义百聆家族近日开源了新一代语音交互模型 Fun-Audio-Chat-8B。该模型在 OpenAudioBench、VoiceBench、UltraEval-Audio、MMAU、MMSU、SpeechFunctionCall 等多项权威基准测试中表现优异,综合性能达到 SOTA(State-of-the-Art)水平,超越了众多同体量的开源模型。它在对话中展现出出色的理解与共情能力,为用户带来更自然、更懂你的交互体验。
通义百聆系列语音模型
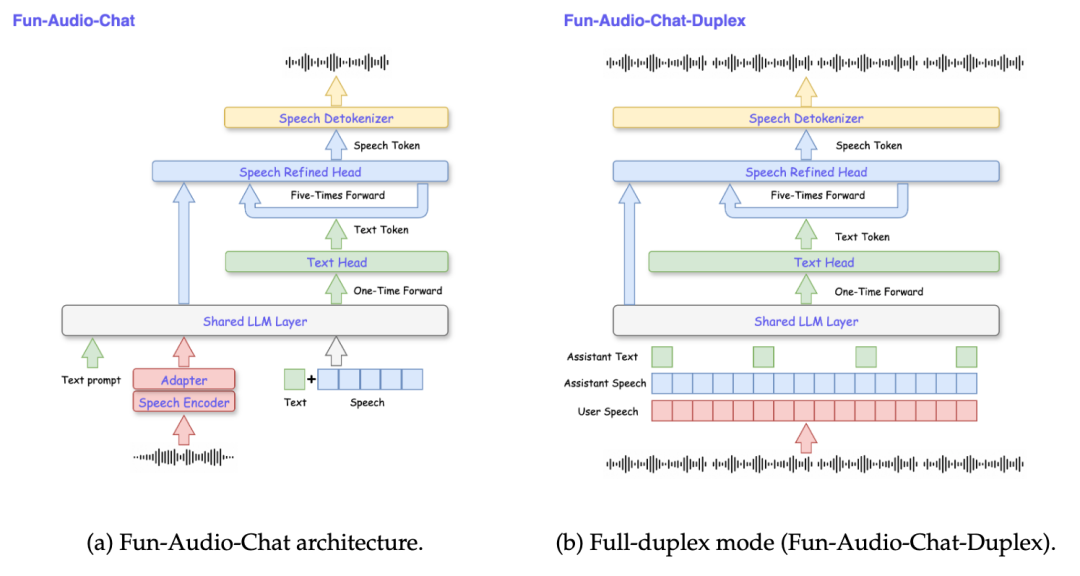
作为通义大模型家族的全新语音系列,通义百聆此前已拥有专注于“会说话”的语音转文字模型 Fun-ASR,以及“听得懂”的文字转语音模型 Fun-CosyVoice3。本次开源的 Fun-Audio-Chat-8B 模型,主打“能听会说”的端到端语音对话功能。用户可直接与模型进行音频交流,无需文字中转,适用于语音聊天、情感陪伴、智能设备和语音客服等多种场景。开发者现可通过魔搭社区、HuggingFace 或 GitHub 下载模型进行体验与部署。
模型开源下载地址:
-
ModelScope:
https://modelscope.cn/FunAudioLLM/Fun-Audio-Chat-8B
-
HuggingFace:
https://huggingface.co/FunAudioLLM/Fun-Audio-Chat-8B
-
GitHub:
https://github.com/FunAudioLLM/Fun-Audio-Chat
高效架构实现近50%GPU计算节省
在融合了大规模语音与多模态数据后,Fun-Audio-Chat-8B 仍能保持强大的文本理解能力(“原有智商”),这得益于两项创新的训练策略。
首先是采用了“核心鸡尾酒”(Core-Cocktail)两阶段训练方法。第一阶段模型专注于快速学习新的语音理解与生成能力;随后,将习得新能力的参数与原始纯文本大模型的参数进行融合,再进行微调。这种策略有效缓解了灾难性遗忘问题,确保模型在掌握新技能的同时不忘“老底子”。
其次是与人类偏好对齐。通过多阶段、多任务的强化学习和指令微调,模型在真实对话场景中能更精准地捕捉用户的语音内容和隐含的情绪线索,从而生成更符合人类期望的自然回应。
此外,模型架构本身也进行了重大创新。它采用了“压缩-自回归-解压缩”(CARD)的双分辨率端到端设计,将需要建模的音频帧率降至业界领先的 5Hz。这一设计在保证输出语音质量的前提下,显著降低了计算复杂度,据测算可节省近 50% 的 GPU 计算资源,对于云原生环境下的部署与推理成本控制具有重要意义。
出色的共情与角色扮演能力
该模型具备优秀的自动情绪感知能力。即使在没有任何外部提示或情绪标签的情况下,它也能通过分析用户的语义、语气、语速、停顿和重音等细微特征,主动感知用户的情绪状态,并给出恰到好处的关切、安慰或鼓励。
示例对话:
用户(语气紧张): “我一个人走在回家的路上,有人已经跟了我两个街区了。”
模型(关切、温和地): “别怕,我陪你一起走这段路,好吗?我们试着往灯亮、人多的地方走。或者,你需要我帮你联系一下家人,发条消息确认你的位置吗?”
同时,模型支持丰富的角色扮演功能。用户可以为其设定特定的角色(如“兴奋的电竞解说员”、“沉稳的历史老师”),并定制对应的情绪、说话风格、语速及音调,使其人工智能交互更具趣味性和定制性。
示例对话:
用户指令: “现在,你是一名正在直播英雄联盟总决赛的、无比兴奋的电竞解说员!”
模型(语速极快、充满激情地): “我的天!这位选手进场了!一个精准的闪现接大招!瞬间融化了对方的后排!这波团战要结束了!让我们恭喜……”
|  发表于 2025-12-24 08:07:14
|
查看: 286|
回复: 0
发表于 2025-12-24 08:07:14
|
查看: 286|
回复: 0
