PostgreSQL 15 版本中引入了一对与恢复过程相关的新参数:recovery_prefetch 和 wal_decode_buffer_size。它们旨在通过预读(Prefetch)机制来加速数据库的Redo恢复过程,这对于提升主库故障重启、点播时间恢复以及备库的数据同步效率至关重要。当Redo速度过慢时,会直接影响服务可用性和数据时效性。
预读机制解决的问题
在一个WAL记录中,包含了被修改的数据页信息。在PG15之前,负责恢复的startup进程在处理WAL记录时是串行的:先读取WAL记录,然后再去读取该记录所涉及的数据页,最后应用更改。读取数据页可能命中共享缓冲区,也可能需要从磁盘加载。如果频繁发生磁盘I/O,startup进程将花费大量时间等待,从而拖慢整个恢复流程。
预读工作机制详解
新的预读机制引入了并行化思路。startup进程在读取WAL记录时,流程变得更加复杂与智能:
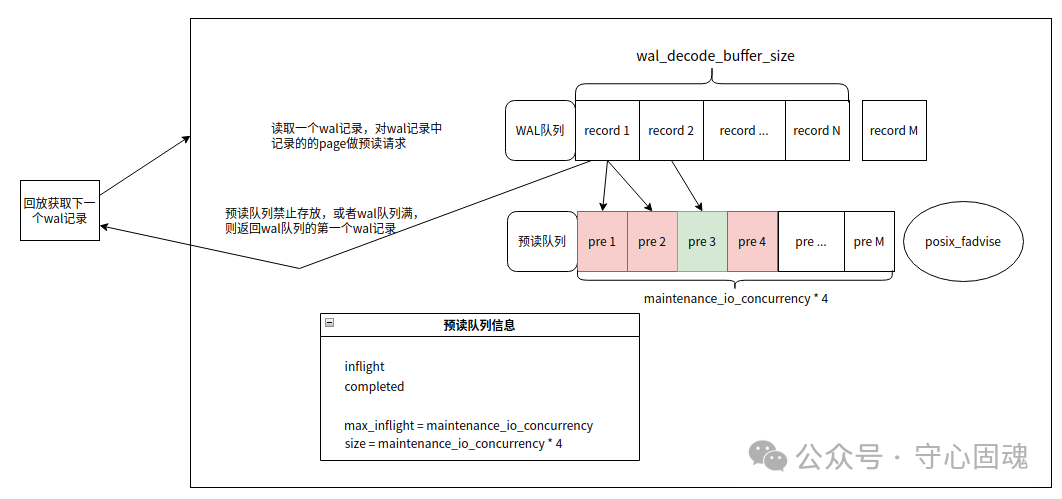
如图所示,startup进程读取到record1后,会将其放入WAL解码队列,并分析出它涉及两个数据页(pre1和pre2)。图中标为红色,意味着这些页不在共享缓冲区中,因此触发了实际的预读操作。
随后,系统会检查WAL队列和预读队列是否已满。若未满,则继续读取下一个record2并放入队列。record2涉及的数据页已在共享缓冲区中(图中标记为绿色),因此只需记录其缓冲区位置,无需触发预读。
这个过程会持续,直到满足以下任一条件则停止预读,并返回record1进行实际的Redo操作:
- WAL队列满。
- 触发的预读(红色)页数量超过
maintenance_io_concurrency。
- 涉及的总页数(红色+绿色)超过
4 * maintenance_io_concurrency。
实际Redo时的优势:
- 处理
record1时,由于其数据页已被预读,极大概率已缓存在操作系统页面缓存中,startup进程可直接使用,避免了真实的磁盘I/O等待。
- 处理
record2时,会检查之前记录的共享缓冲区位置是否仍有效。若该页未被换出,则直接使用;若被换出,则退回到普通读取流程。
简而言之,该机制的核心思想是将可能阻塞的同步I/O转化为异步的预读任务,让startup进程在系统“后台”加载数据的同时,继续处理其他逻辑,从而大幅减少I/O等待时间,提升数据库/中间件恢复性能。
相关GUC参数解析
总结与注意事项
预读机制的精髓在于变“被动等待”为“主动调度”,通过异步I/O来掩盖延迟。要有效测试此功能的性能提升,必须确保测试数据集远大于shared_buffers,否则数据全在内存中,预读效果无法显现。
在高负载场景下,备库追同步压力巨大。除了预读,社区也一直在探索并行Redo等更激进的算法/数据结构优化方案,以进一步提升恢复并行度。 |  发表于 2025-12-25 03:48:31
|
查看: 176|
回复: 0
发表于 2025-12-25 03:48:31
|
查看: 176|
回复: 0
