引言:当 AI 学会“看”屏幕
想象这样一个场景:你对着手机发出语音指令“帮我订一张明天去上海的高铁票,二等座,上午10点左右出发”。随后,一个AI助手自动打开铁路12306应用,准确地填写出发地、目的地、日期,筛选出符合条件的车次,并完成预订与支付——全程无需你触碰屏幕。它就像一个真实的助手,能够“看见”界面、“理解”内容并“点击”按钮。
这并非科幻,而是GUI Agent(图形用户界面智能体)正在实现的现实。
在过去二十年,企业自动化的主流方案是RPA(机器人流程自动化)。然而,RPA依赖于固定的UI元素选择器,一旦界面发生微小变化,自动化脚本便会失效,导致高昂的维护成本。
GUI Agent的出现带来了范式转变。它并非简单“回放”预设脚本,而是像人类一样,通过视觉感知理解屏幕内容,借助大语言模型的推理能力规划操作步骤,从而在动态、未知的软件环境中自主完成任务。
本文将深入解析GUI Agent的技术原理,并通过两个递进的实战案例,帮助你掌握部署与应用这一前沿智能体系统的核心方法。
一、AI操作界面的核心技术:GUI Agent
1. GUI Agent 是什么?
GUI Agent(图形用户界面智能体)是一类能够自主理解并操作图形用户界面的AI系统。与传统的API调用或命令行工具不同,GUI Agent直接与人机交互的图形界面进行交互——无论是手机APP、桌面软件还是网页应用。
1)从 RPA 到 AI Agent 的范式转变
通过下表对比,可以清晰地理解这一转变的核心:
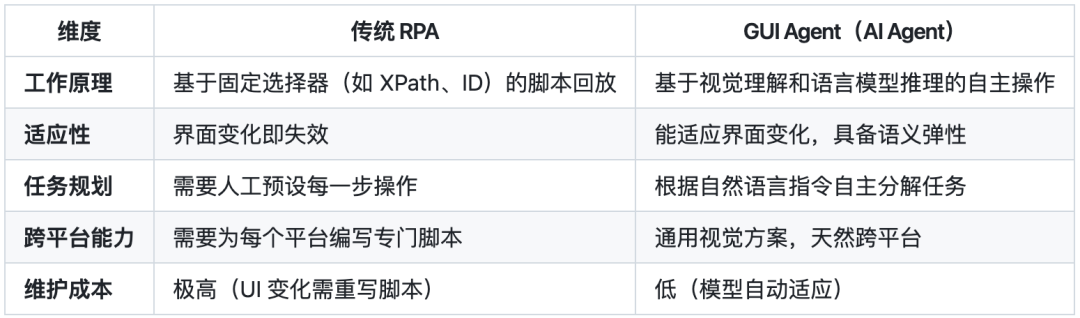
核心区别在于:RPA是“脆弱的、基于规则的自动化”,而GUI Agent是“智能的、基于理解的自主化”。
2)GUI Agent 兴起的技术背景
GUI Agent的爆发是多项技术协同成熟的必然结果。首先,多模态大模型取得了突破性进展。GPT-4o、Claude 3.5 Sonnet、Qwen-VL等模型不仅能处理文本,还能理解图像,为GUI Agent装上了强大的“眼睛”。当一张屏幕截图输入模型时,它能准确识别出界面元素及其功能。
其次是精准定位能力的突破。早期视觉模型能识别元素但难以定位,而GUI-Owl、Qwen-VL等经过专门训练的模型,可以精确输出UI元素的屏幕坐标,实现了从“看见”到“点准”的跨越。
最后是推理能力的质变。大语言模型具备的链式思考能力,让Agent拥有了规划复杂任务的“大脑”。它能将模糊的用户指令(如“订高铁票”)分解为一系列可执行的具体步骤(打开APP、输入信息、筛选、支付),并在执行中持续反思与纠错。
2. GUI Agent 的核心技术架构
一个完整的GUI Agent系统遵循“感知-推理-执行”的闭环架构,这是其实现自主决策的基础。
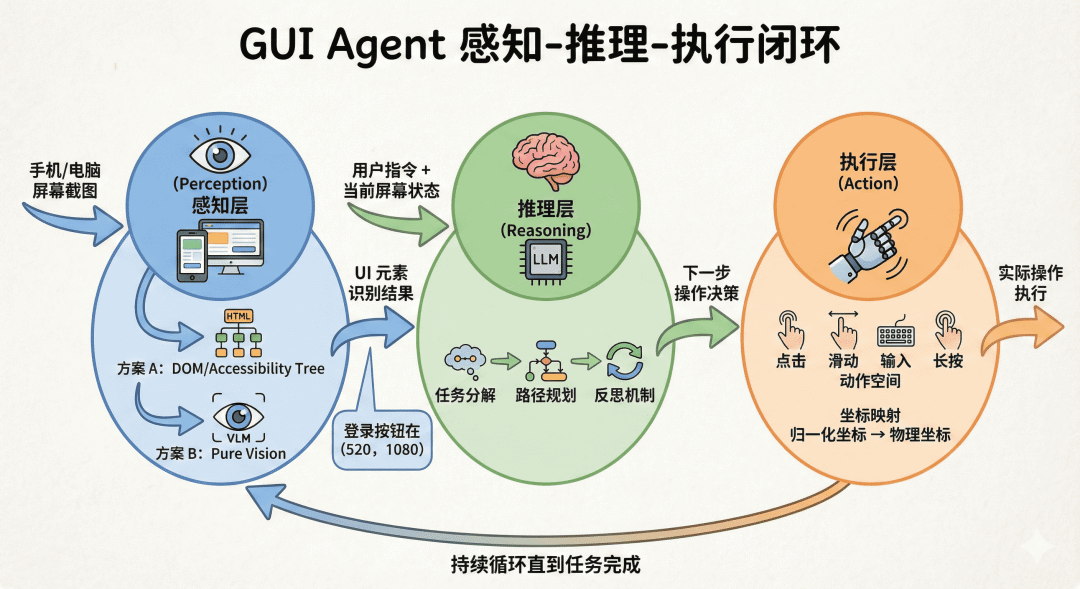
图 1 GUI Agent 的感知-推理-执行闭环
1)感知层:机器如何“看见”屏幕
感知层负责将屏幕的像素信息转化为机器可理解的结构化数据。目前主要有两种技术路线:
- 基于结构化信息的感知:通过系统API(如网页的DOM树、Android的View Hierarchy)获取应用内部结构。这种方式精确高效,但通用性差,无法处理游戏、Canvas绘制界面或不暴露结构的应用,且丢失了视觉布局信息。
- 基于纯视觉的感知:直接截取屏幕图像,使用视觉大模型进行理解。这种方式通用性极强,任何能显示在屏幕上的内容均可被识别,并具备“语义弹性”——即使按钮颜色、位置发生变化,仍能通过语义识别。其挑战在于需要高精度的元素定位。
2)推理层:大脑的决策过程
推理层是GUI Agent的智能核心,负责将抽象指令转化为具体操作序列。
- 任务分解:将“订明天上午10点去上海的高铁票”分解为“打开APP→输入地点→选择日期→查询→筛选车次→支付”等多个子步骤。
- 思维链机制:在执行每一步前,Agent会生成“内心独白”进行分析与决策,例如:“当前是首页,我的目标是订票,因此需要点击‘车票预订’按钮。”这使得过程更可解释,并减少了误差累积。
- 反思与纠错:如果执行后未达到预期效果(如弹出错误提示),Agent能识别问题并调整策略,例如:“刚才漏选了日期,需要先返回选择日期。”
3)执行层:从决策到行动
执行层是GUI Agent的“手”,负责将推理决策转化为真实的系统操作。
GUI操作的动作空间是有限的,主要包括:点击、滑动、输入、长按等。每种动作都需要特定参数,如点击坐标(x, y)、滑动轨迹(x1, y1, x2, y2)、输入文本等。
关键技术点在于坐标映射:模型通常输出归一化坐标(如0-1000),执行层需将其精确映射到设备实际分辨率(如1920x1080)。同时,还需进行多平台适配:在Android上通过ADB命令(如adb shell input tap 500 1000)操作,在桌面上则可能使用 pyautogui 等 Python 库控制鼠标键盘。
3. 主流开源框架全景对比
2024-2025年,GUI Agent领域迎来了开源框架的爆发期。下表从多个维度对比了几个代表性项目:
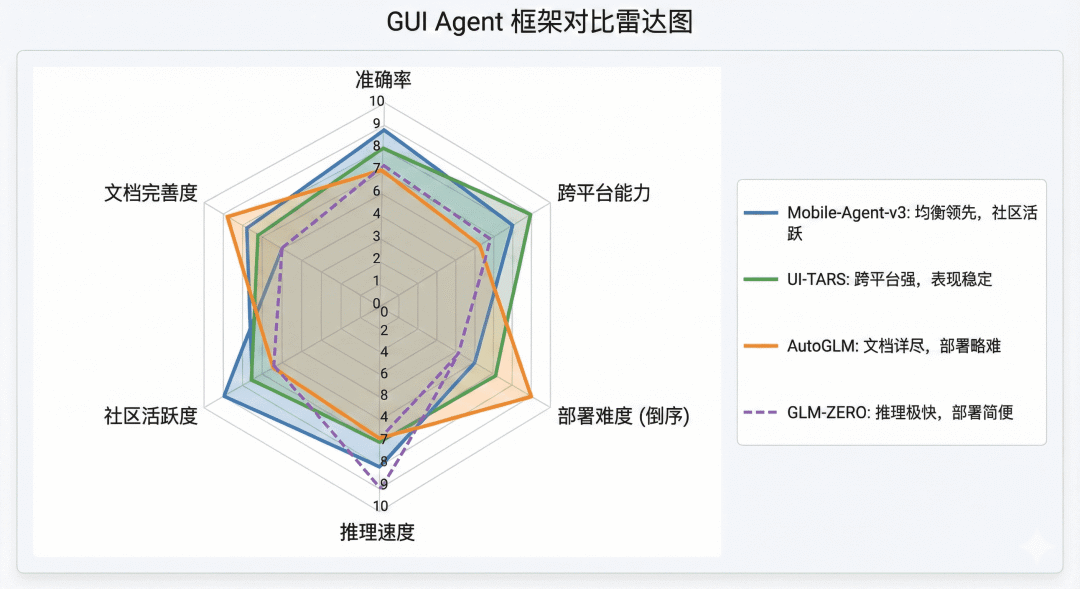
图 2 主流 GUI Agent 框架对比雷达图
4. 应用场景与技术局限
1)典型应用场景
- 智能座舱:实现“导航到咖啡店并提前点单”等跨应用、含时间逻辑的复杂语音指令。
- 软件测试:自适应UI变化,进行视觉回归测试与探索性测试,大幅降低测试脚本维护成本。
- 企业RPA:为没有开放API的遗留系统提供自动化可能,实现数据跨系统流转。
- 个人助理:自动化处理社交内容发布、信息聚合、健康数据记录等重复性数字劳动。
- 无障碍辅助:帮助视障或肢体障碍用户通过语音完全控制设备与应用程序。
2)当前技术局限
- 安全性与幻觉风险:模型可能误解高风险指令(如“清理桌面”被执行为删除文件),需通过人工确认、操作日志与沙箱环境进行缓解。
- 成本与效率问题:每一步操作都需调用大模型推理,使用云端API成本较高,本地小模型则准确率可能下降。长任务耗时明显。
- 准确率瓶颈:在真实复杂场景中,当前顶尖系统的任务成功率约在40-50%,面临复杂界面定位、动态内容干扰、长链条任务错误累积等挑战。
二、实战教程:部署你的“AI操作助手”
理论学习后,让我们通过两个由易到难的实战案例,亲手操作GUI Agent。
实战一:Mobile-Agent 在线体验(零门槛)
1)访问在线 Demo
推荐使用ModelScope平台提供的Demo,它提供了云电脑环境,无需任何本地部署。
2)界面功能与设置
进入页面后,请进行关键设置以确保体验:
- 在左上角设备下拉菜单中选择 “电脑”。
- 右侧窗口为分配给你的Windows 10云桌面。
- 左下角为指令输入区,上方对话框将显示Agent的思考与操作过程。
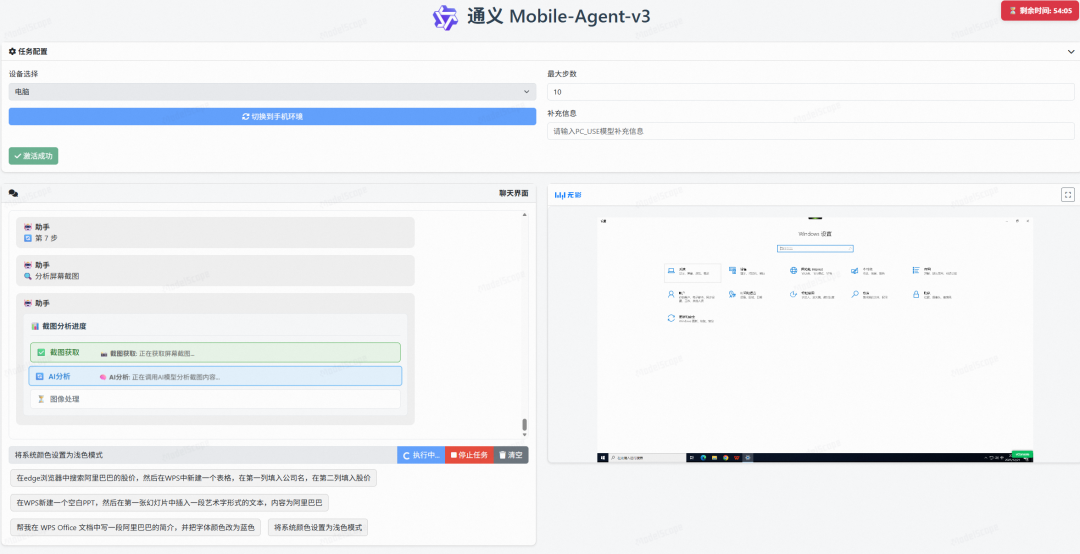
图 3 Mobile-Agent-v3 在线 Demo 界面
3)任务演练与提示词技巧
建议从简单任务开始尝试,并运用以下提示词技巧以提升成功率:
- 明确应用边界:避免“写个简介”,而应说“在WPS文档中写一段简介……”。
- 步骤链式拆解:将复杂任务分解为顺序步骤,如“第一步,打开浏览器搜索……;第二步,将结果复制到Excel……”。
- 利用视觉属性:描述元素的视觉特征,如“点击顶部蓝色的‘保存’图标”。
4)在线体验的价值与局限
在线Demo的价值在于零门槛快速体验技术边界。但其局限性在于隐私考虑、预装应用有限及云端延迟。要深入应用,需进行本地部署。
实战二:AutoGLM 本地部署与手机操控
本实战目标是在本地电脑部署AutoGLM,并连接真实Android手机,完成自动化任务。
1)环境准备
- 硬件:一台可运行Python的电脑;一部Android 7.0+的手机(需开启USB调试,无需Root)。
- 软件:安装Python 3.10+、ADB工具及ADB Keyboard输入法。
2)第一步:安装 Open-AutoGLM
# 克隆代码仓库
git clone https://github.com/zai-org/Open-AutoGLM.git
cd Open-AutoGLM
# 安装依赖及项目本身
pip install -r requirements.txt
pip install -e .
安装后,在项目根目录创建.env文件,填入从智谱AI平台获取的API密钥:
GLM_API_KEY=your_api_key_here
3)第二步:连接 Android 手机
- 启用开发者选项:在手机“设置-关于手机”中连续点击版本号7次,然后进入“开发者选项”开启“USB调试”。
- 安装ADB Keyboard:从GitHub下载APK并安装,随后在手机输入法设置中启用它。这是实现文本输入的关键。
- 验证连接:手机通过USB连接电脑,在终端执行
adb devices,看到设备序列号后显示device即为成功。
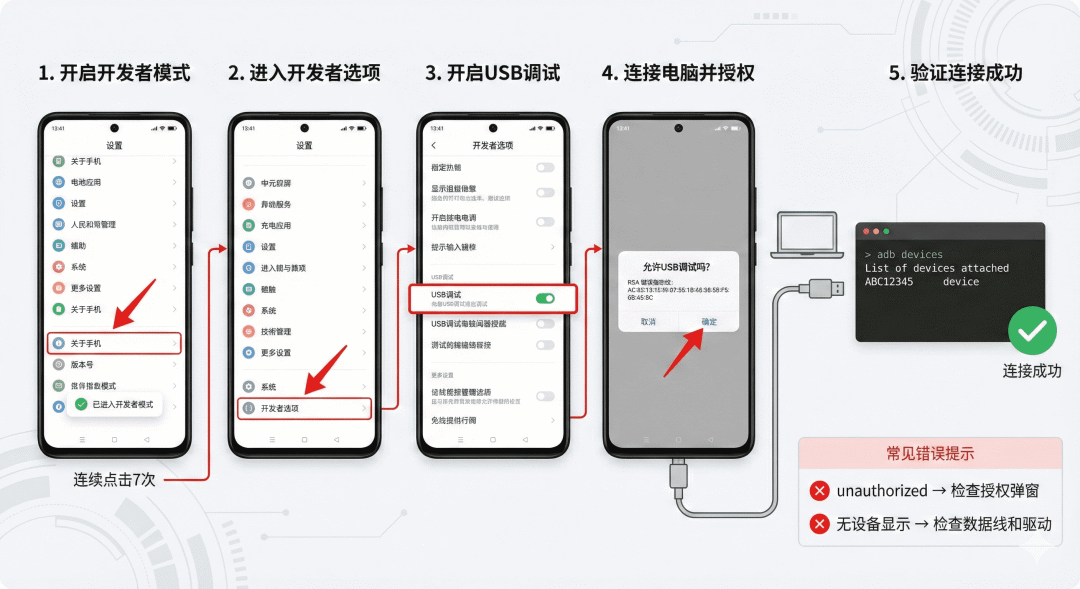
图 4 Android 手机 ADB 连接配置流程
4)第三步:运行第一个自动化任务
一切就绪后,即可通过命令行向你的手机发送指令。以下示例使用智谱的API服务:
python main.py --base-url https://open.bigmodel.cn/api/paas/v4 --model "autoglm-phone" --apikey "your-api-key" "打开美团搜索附近的火锅店"
执行后,AutoGLM将自动完成:截屏分析 → 定位并点击美团图标 → 等待启动 → 定位搜索框 → 点击并调用ADB Keyboard输入“附近的火锅” → 点击搜索按钮。整个流程约15-20秒,你可以在终端观察实时日志,并在手机屏幕上看到自动操作的过程。这为 Android 应用自动化测试与交互提供了全新的思路。
三、总结与展望
通过从在线体验到本地部署的实战,我们完整遍历了GUI Agent的应用链路。这项技术正推动人机交互向更自然、更智能的方向演进。
尽管当前GUI Agent在准确率、效率和成本上面临挑战,但随着视觉大模型能力的持续进化、端侧算力的提升以及“人在回路”等协作模式的优化,其应用前景广阔。未来,我们或许只需一句自然语言指令,就能让AI助手无缝穿梭于各个应用之间,完成复杂的数字工作流。GUI Agent为代表的 人工智能 智能体,正在将这个未来变为现实。
 发表于 2025-12-25 10:29:15
|
查看: 274|
回复: 0
发表于 2025-12-25 10:29:15
|
查看: 274|
回复: 0
