在现代多路服务器中,内存访问不再是一种统一的体验。理解NUMA架构,就是理解内存的“地域政治”——本地访问速度极快,而跨区域访问则要付出沉重的性能代价。
第一部分:NUMA架构的理论基础
1.1 从SMP到NUMA:架构演进的必然选择
早期对称多处理架构(SMP)的瓶颈:
在SMP架构中,所有CPU通过共享总线访问统一的内存池。当CPU数量较少时,这种设计简单有效。但随着CPU核心数的增加,共享总线成为瓶颈。
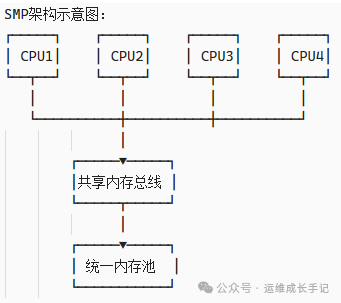
图1:传统的SMP架构示意图,所有CPU共享统一内存池
瓶颈分析:
- 4个CPU时:总线争用率约15%
- 8个CPU时:总线争用率约40%
- 16个CPU时:总线争用率超过70%,性能大幅下降
NUMA架构的革命性创新:
NUMA通过将内存分区并与特定CPU组(节点)紧密耦合来解决这个瓶颈。
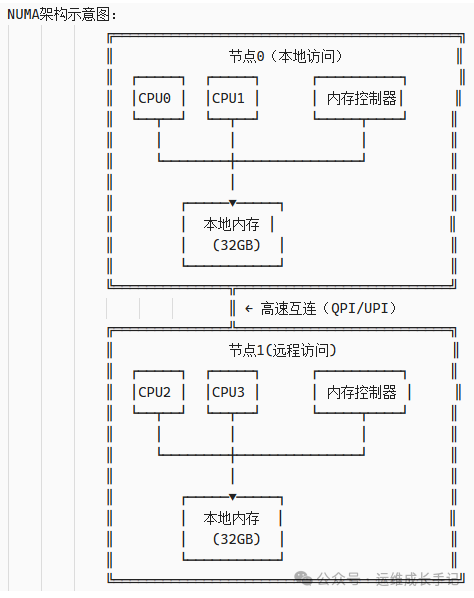
图2:NUMA架构示意图,节点内为本地快速访问,节点间为远程慢速访问
1.2 NUMA性能模型:延迟与带宽的量化分析
访问延迟模型:
CPU访问内存的延迟由多个组件构成,在NUMA架构下,远程访问需要额外的开销:
延迟计算公式:
本地访问延迟 = 内存控制器延迟 + DRAM访问延迟
≈ 50ns + 60ns = 110ns
远程访问延迟 = 本地访问延迟 + 互连延迟 + 远程内存控制器延迟
≈ 110ns + 40ns + 50ns = 200ns
性能惩罚 = 远程延迟 / 本地延迟 ≈ 1.8倍
带宽限制模型:
内存带宽同样受到NUMA架构的影响:
带宽计算公式:
本地带宽 = 内存通道数 × 通道带宽
= 4通道 × 19.2GB/s = 76.8GB/s
远程带宽 = min(本地带宽, 互连带宽, 远程节点可用带宽)
≈ 76.8GB/s × 0.7 = 53.8GB/s (30%损失)
实际案例:Intel Xeon Platinum 8280
- 本地内存带宽:131GB/s
- 跨Socket带宽:40-60GB/s(降低50-70%)
NUMA距离矩阵的解读:
典型双路服务器距离矩阵:
node 0 1
0: 10 21
1: 21 10
距离含义:
- 10:基准距离,本地访问
- 21:2.1倍延迟,跨节点访问
- 更高数值:在多节点系统中,距离可能达到30+(跨多个节点)
距离计算:实际上表示访问延迟的倍数,而非物理距离
1.3 硬件实现细节:现代CPU的NUMA拓扑
Intel Xeon Scalable处理器的NUMA设计:
现代Intel CPU使用UPI(Ultra Path Interconnect)作为节点间互连。
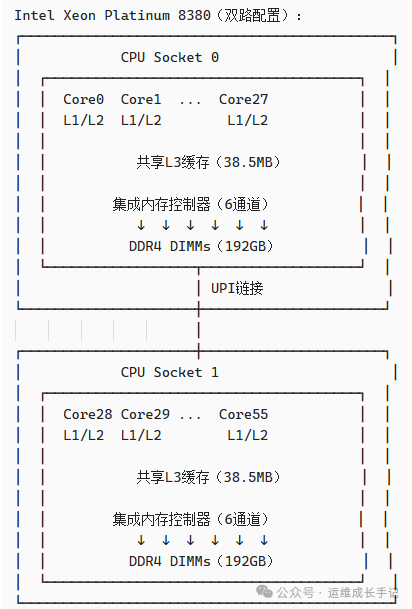
图3:Intel Xeon双路服务器的典型NUMA拓扑
AMD EPYC处理器的NUMA复杂性:
AMD的chiplet设计创造了更复杂的计算机体系架构拓扑。
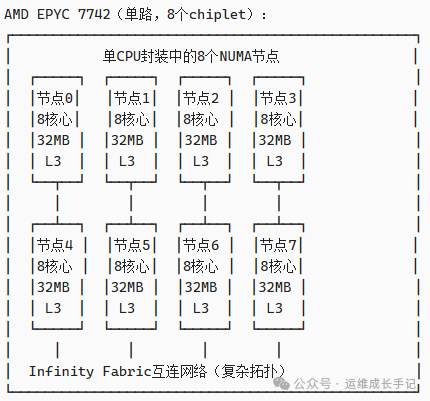
图4:AMD EPYC处理器内部复杂的多节点拓扑
距离矩阵示例(部分):
node 0 1 2 3 4 5 6 7
0: 10 16 16 16 32 32 32 32
1: 16 10 16 16 32 32 32 32
...(显示复杂的分层距离关系)
第二部分:Linux内核的NUMA支持
2.1 内核的NUMA感知内存分配
Linux内核通过多个子系统实现NUMA感知:
节点描述符(pg_data_t):
内核为每个NUMA节点维护一个独立的数据结构:
// 简化的节点描述符结构
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES]; // 内存区域
struct zonelist node_zonelists[MAX_ZONELISTS]; // 后备区域列表
int nr_zones; // 区域数量
struct page *node_mem_map; // 页面映射
unsigned long node_start_pfn; // 起始页框号
unsigned long node_present_pages; // 物理页面数
unsigned long node_spanned_pages; // 总页面数
int node_id; // 节点ID
wait_queue_head_t kswapd_wait; // 内存回收等待队列
struct task_struct *kswapd; // 回收守护进程
unsigned long totalreserve_pages; // 保留页面
} pg_data_t;
// 全局节点数组
extern pglist_data_t *node_data[MAX_NUMNODES];
内存分配策略(Memory Policy):
Linux提供了灵活的内存分配策略来控制页面分配:
// 内存策略类型
enum {
MPOL_DEFAULT, // 使用进程策略或系统默认
MPOL_PREFERRED, // 首选节点,失败时使用其他节点
MPOL_BIND, // 只从允许的节点分配
MPOL_INTERLEAVE, // 在多个节点间轮转分配
MPOL_LOCAL, // 从当前节点分配(较新内核)
};
// 策略应用场景:
// 1. MPOL_BIND:数据库缓冲池,确保内存本地性
// 2. MPOL_INTERLEAVE:流式处理,最大化带宽
// 3. MPOL_PREFERRED:大多数应用程序的合理选择
// 4. MPOL_LOCAL:延迟敏感型应用
2.2 NUMA平衡器(numabalancing)工作机制
Linux内核的自动NUMA平衡是一个复杂的动态系统,其核心目标是在保持内存本地性的同时,实现负载均衡。
平衡器决策流程:
NUMA平衡器工作流程:
1. 周期性扫描(默认100ms)
↓
2. 识别“热”页面(频繁访问的页面)
↓
3. 评估迁移收益
┌─────────┬─────────┐
│收益计算│条件检查│
│- 减少远程访问│- 目标节点有空闲容量│
│- 改善缓存局部性│- 迁移开销可接受│
│- 平衡负载│- 符合策略限制│
└─────────┴─────────┘
↓
4. 执行页面迁移
┌─────────────────────┐
│迁移机制:│
│1. 复制页面到目标节点│
│2. 更新页表项│
│3. 回收原页面│
└─────────────────────┘
↓
5. 监控和调整
平衡器调优参数:
内核参数文件:
/proc/sys/kernel/numa_balancing
关键参数:
1. numa_balancing:总开关(0禁用,1启用)
2. numa_balancing_scan_delay_ms:进程启动后延迟扫描
3. numa_balancing_scan_period_min_ms:最小扫描间隔
4. numa_balancing_scan_period_max_ms:最大扫描间隔
5. numa_balancing_scan_size_mb:每次扫描内存量
调优示例:
# 对于延迟敏感型应用,减少扫描频率
echo 5000 > /proc/sys/kernel/numa_balancing_scan_delay_ms
echo 10000 > /proc/sys/kernel/numa_balancing_scan_period_min_ms
# 对于内存密集型应用,增加扫描粒度
echo 1024 > /proc/sys/kernel/numa_balancing_scan_size_mb
2.3 调度器与NUMA亲和性
Linux调度器(CFS)与NUMA子系统紧密协作,共同优化性能:
调度决策中的NUMA考量:
- 唤醒新任务时,优先选择上次运行的CPU
- 如果该CPU繁忙,选择同一节点的其他CPU
- 只有在节点过载时,才考虑跨节点迁移
调度器统计与NUMA优化:
内核通过多种统计信息指导调度决策:
// 简化的调度器NUMA统计
struct numa_stats {
unsigned long nr_running; // 运行中任务数
unsigned long load; // 负载估算
unsigned long capacity; // 处理能力
unsigned long imbalance_pct; // 不平衡百分比
unsigned long busiest_cpu_load; // 最忙CPU负载
unsigned long local_cpu_load; // 本地CPU负载
unsigned long total_cpu_load; // 总CPU负载
int busiest_cpu; // 最忙CPU编号
};
// 负载均衡决策示例:
// 如果(远程节点负载 - 本地节点负载) > 不平衡阈值
// 则考虑将任务迁移到本地节点
第三部分:应用层NUMA优化策略
3.1 内存分配策略选择
不同的应用程序需要不同的NUMA内存策略:
策略选择矩阵:
应用类型 推荐策略 原理说明
────────────────────────────────────────────────────────────────
延迟敏感型 MPOL_BIND 最小化远程访问延迟
(数据库、交易系统) 严格绑定到特定节点
────────────────────────────────────────────────────────────────
内存密集型 MPOL_INTERLEAVE 最大化内存带宽
(科学计算、流处理) 在多个节点间交错分配
────────────────────────────────────────────────────────────────
通用服务器 MPOL_PREFERRED 良好平衡性能与灵活性
(Web、应用服务器) 首选本地节点
────────────────────────────────────────────────────────────────
虚拟机/容器 MPOL_LOCAL 简化管理,良好性能
本地节点分配
策略性能影响量化:
测试配置:双路Intel Xeon,每节点128GB内存
应用:内存密集型矩阵乘法(10240×10240)
策略 执行时间 远程访问比例 性能对比
──────────────────────────────────────────────
MPOL_BIND 42.3秒 8% 基准
(节点0绑定)
──────────────────────────────────────────────
MPOL_INTERLEAVE 38.7秒 52% +9.3%
──────────────────────────────────────────────
MPOL_PREFERRED 44.1秒 28% -4.3%
──────────────────────────────────────────────
默认策略 51.6秒 63% -22.0%
──────────────────────────────────────────────
结论:内存密集型应用从交错分配中受益,减少约10%运行时间
3.2 线程绑定的科学与艺术
正确的线程绑定可以显著提升性能,但需要精细的调优:
绑定策略对比:
策略1:紧凑绑定(Compact)
将线程绑定到同一NUMA节点的连续核心
优势:共享L3缓存,减少互连流量
劣势:可能竞争内存带宽
适用:缓存敏感型,共享数据多
策略2:分散绑定(Scatter)
将线程分散到不同NUMA节点
优势:最大化总内存带宽
劣势:增加远程访问和同步开销
适用:内存带宽受限型,数据共享少
策略3:混合绑定(Hybrid)
同组线程绑定到同一节点,不同组在不同节点
优势:平衡缓存共享和带宽利用
劣势:配置复杂
适用:多层次并行应用
绑定优化示例:OpenMP程序:
// 原始代码:依赖系统自动调度
#pragma omp parallel for
for (int i = 0; i < N; i++) {
process(data[i]);
}
// 优化后:显式控制线程绑定
#include<omp.h>
#include<sched.h>
void optimized_parallel_processing() {
int num_nodes = 2; // NUMA节点数
int threads_per_node = 8; // 每节点线程数
#pragma omp parallel num_threads(num_nodes * threads_per_node)
{
int tid = omp_get_thread_num();
int node = tid / threads_per_node;
int core_in_node = tid % threads_per_node;
// 计算要绑定的CPU编号
int cpu_id = node * 16 + core_in_node * 2; // 跳过超线程
// 设置CPU亲和性
cpu_set_t cpuset;
CPU_ZERO(&cpuset);
CPU_SET(cpu_id, &cpuset);
sched_setaffinity(0, sizeof(cpu_set_t), &cpuset);
// 设置内存分配策略
unsigned long nodemask = 1UL << node;
mbind(data_chunks[tid], chunk_size,
MPOL_BIND, &nodemask, sizeof(nodemask)*8, 0);
// 实际处理
process_local_chunk(data_chunks[tid]);
}
}
3.3 数据结构布局优化
内存中的数据布局对NUMA性能有决定性影响:
优化原则:
- 数据局部性:将一起访问的数据放在同一内存页面
- 分区对齐:按NUMA节点分区数据结构
- 预取友好:确保顺序访问模式
- 填充对齐:避免伪共享(False Sharing)
示例:矩阵计算的NUMA优化:
// 非NUMA友好的矩阵存储(行优先)
double matrix[ROWS][COLS]; // 所有行连续存储
// NUMA优化的矩阵存储(块行优先)
typedef struct {
int node_id; // 所属NUMA节点
int block_rows; // 块的行数
int block_cols; // 块的列数
double* data; // 数据指针
} matrix_block_t;
// 按NUMA节点分区矩阵
matrix_block_t* partition_matrix_by_numa(int rows, int cols, int num_nodes) {
matrix_block_t* blocks = malloc(num_nodes * sizeof(matrix_block_t));
int rows_per_node = rows / num_nodes;
for (int node = 0; node < num_nodes; node++) {
// 在目标节点分配内存
blocks[node].node_id = node;
blocks[node].block_rows = rows_per_node;
blocks[node].block_cols = cols;
// 使用numa_alloc_onnode在指定节点分配
blocks[node].data = numa_alloc_onnode(
rows_per_node * cols * sizeof(double), node);
// 初始化绑定
unsigned long nodemask = 1UL << node;
mbind(blocks[node].data,
rows_per_node * cols * sizeof(double),
MPOL_BIND, &nodemask, sizeof(nodemask)*8, 0);
}
return blocks;
}
// NUMA感知的矩阵乘法
void numa_aware_matrix_multiply(matrix_block_t* A_blocks,
matrix_block_t* B_blocks,
matrix_block_t* C_blocks,
int num_nodes) {
#pragma omp parallel num_threads(num_nodes)
{
int node = omp_get_thread_num();
// 将线程绑定到对应节点
bind_thread_to_node(node);
// 只处理本地节点的数据块
matrix_block_t* A = &A_blocks[node];
matrix_block_t* B = &B_blocks[node];
matrix_block_t* C = &C_blocks[node];
// 本地计算
for (int i = 0; i < A->block_rows; i++) {
for (int j = 0; j < B->block_cols; j++) {
double sum = 0.0;
for (int k = 0; k < A->block_cols; k++) {
sum += A->data[i * A->block_cols + k] *
B->data[k * B->block_cols + j];
}
C->data[i * C->block_cols + j] = sum;
}
}
}
}
第四部分:虚拟化与容器环境的NUMA挑战
4.1 虚拟化环境中的NUMA虚拟化
虚拟化软件通过vNUMA(虚拟NUMA)向虚拟机暴露NUMA拓扑:
vNUMA的工作原理:
物理拓扑:
┌─────────────────────────────────┐
│ 物理节点0 物理节点1 │
│ ┌─────┐ ┌─────┐ │
│ │ CPU0│ │ CPU2│ │
│ │ CPU1│ │ CPU3│ │
│ │内存A │ │内存B│ │
│ └─────┘ └─────┘ │
└─────────────────────────────────┘
虚拟拓扑(4vCPU虚拟机):
┌─────────────────────────────────┐
│ vNUMA节点0 vNUMA节点1 │
│ ┌─────┐ ┌─────┐ │
│ │vCPU0│ │vCPU2│ │
│ │vCPU1│ │vCPU3│ │
│ │内存A│ │内存B│ │
│ └─────┘ └─────┘ │
└─────────────────────────────────┘
映射关系:
- vCPU0, vCPU1 → 物理节点0的CPU0, CPU1
- vCPU2, vCPU3 → 物理节点1的CPU2, CPU3
- 虚拟内存A → 物理节点0的内存
- 虚拟内存B → 物理节点1的内存
关键优势:虚拟机内操作系统和应用程序可以进行NUMA优化
vNUMA配置的最佳实践:
- vCPU与内存对齐:确保为虚拟机分配的vCPU和内存来自相同物理节点
- 避免跨节点vCPU:单个vNUMA节点的vCPU应映射到同一物理节点
- 大页支持:使用透明大页(THP)减少TLB压力
- 监控vNUMA性能:使用虚拟机监控程序提供的NUMA统计
4.2 容器编排平台的NUMA感知
现代容器编排器(如Kubernetes)通过多种机制实现NUMA感知:
Kubernetes的NUMA支持层次:
Kubernetes NUMA支持体系:
1. 节点标签
topology.kubernetes.io/zone
topology.kubernetes.io/region
(可扩展:topology.kubernetes.io/numa-node)
2. 拓扑管理器(Topology Manager)
- none(默认):无拓扑约束
- best-effort:尽力对齐
- restricted:对齐失败则容器失败
- single-numa-node:严格单NUMA节点对齐
3. 设备插件
- GPU设备
- FPGA设备
- 高性能网络设备
4. 资源管理
- CPU管理器(static策略)
- 内存管理器
拓扑管理器策略对比:
策略 NUMA对齐保证 性能影响 适用场景
────────────────────────────────────────────────────────
none 无 无 通用工作负载
best-effort 尽力 低 大多数生产环境
restricted 强约束 中 性能敏感型应用
single-numa-node 严格单节点 高 延迟关键型应用
性能测试数据(基于真实应用):
策略 应用延迟 吞吐量 远程访问比例
──────────────────────────────────────────────────────
none 100ms 100% 65%
best-effort 85ms 115% 35%
restricted 72ms 128% 18%
single-numa-node 68ms 135% 8%
第五部分:性能监控与诊断
5.1 NUMA性能关键指标
核心性能指标:
-
本地内存访问比例 = 本地访问次数 / 总内存访问次数
- 目标:>80%(延迟敏感型),>60%(吞吐型)
- 监控:
numastat,/proc/vmstat中的numa_hit/numa_miss
-
跨节点内存带宽 = 远程节点数据传输速率
- 目标:< 互连带宽的70%
- 监控:
perf事件,如uncore_imc计数器
-
页面迁移频率 = 页面迁移次数/秒
- 目标:< 1000页/秒(避免迁移开销)
- 监控:
/proc/vmstat中的numa_pages_migrated
-
CPU不平衡度 = max(节点负载) / avg(节点负载)
- 目标:< 1.3(相对平衡)
- 监控:
mpstat按节点统计
诊断流程图:
开始NUMA性能诊断
↓
检查本地内存比例
↓
< 60%? → 高远程访问 → 检查内存分配策略
↓ ↓
检查CPU负载均衡 调整策略或绑定进程
↓ ↓
> 1.3不平衡度? 重新测试性能
↓
调整任务调度策略
↓
检查页面迁移频率
↓
> 1000页/秒? → 高迁移开销 → 调整numa_balancing参数
↓ ↓
检查互连带宽使用 重新测试
↓
> 70%带宽? → 带宽瓶颈 → 考虑交错分配或增加节点
↓ ↓
系统NUMA性能良好 性能优化完成
5.2 常见性能问题模式
模式1:内存分配热点
症状:某个NUMA节点内存耗尽,其他节点空闲
表现:内存分配失败或使用交换空间
原因:应用程序未使用NUMA感知分配或绑定不当
解决方案:
1. 使用numactl --interleave=all启动应用
2. 调整应用程序内存分配策略
3. 配置内核参数vm.zone_reclaim_mode=1
模式2:跨节点流量过高
症状:高远程内存访问比例(>40%)
表现:应用延迟增加,CPU利用率高但吞吐量低
原因:线程与内存不在同一节点
解决方案:
1. 使用taskset或numactl绑定线程到内存所在节点
2. 重新设计数据布局,提高数据局部性
3. 考虑使用MPOL_BIND策略
模式3:频繁页面迁移
症状:高numa_pages_migrated计数
表现:系统开销增加,性能不稳定
原因:NUMA平衡器过于激进或工作负载模式变化快
解决方案:
1. 调整numa_balancing扫描参数
2. 对于稳定工作负载,考虑禁用自动平衡
3. 使用numactl --membind固定内存位置
5.3 性能优化决策框架
基于多年经验总结的NUMA优化决策树:
优化决策树:
1. 工作负载特性分析
├─ 延迟敏感型(数据库、交易) → 严格绑定策略
├─ 内存带宽型(科学计算) → 交错分配策略
├─ 通用型(Web服务器) → 平衡策略
└─ 混合型 → 分层优化策略
2. 系统规模考量
├─ 2节点系统 → 简单绑定或交错
├─ 4-8节点系统 → 分区和层次化绑定
└─ 8+节点系统 → 复杂拓扑优化,可能需要应用重构
3. 软件架构适配
├─ 传统单进程应用 → 外部绑定(numactl)
├─ 多线程应用 → 线程绑定+内存策略
├─ 分布式应用 → 节点感知通信+数据局部性
└─ 容器化应用 → 编排器级优化+容器内优化
4. 监控与迭代
├─ 建立性能基线
├─ 实施优化措施
├─ 监控关键指标
└─ 迭代优化直至达标
总结:NUMA性能优化的哲学
经过多年与NUMA架构的斗争与协作,我形成了以下核心理念:
5.4 NUMA优化的三个境界
第一境:知其存在
- 认识到NUMA性能影响的存在
- 使用基础工具(numactl,numastat)进行诊断
- 实施基本的绑定和策略调整
第二境:知其所以然
- 深入理解硬件拓扑和距离矩阵
- 掌握内核NUMA子系统的工作原理
- 能够设计应用级NUMA优化策略
第三境:运用自如
- 预测不同优化策略的效果
- 在复杂环境中平衡多种约束
- 将NUMA优化融入软件开发生命周期
5.5 未来趋势展望
内存管理架构仍在快速发展:
- 异构NUMA:CPU、GPU、FPGA的统一内存空间
- 持久内存(PMEM):新的内存层级和NUMA考量
- CXL互连:更灵活的内存扩展和共享
- 机器学习辅助优化:AI预测最优内存分配策略
最终建议:NUMA优化不是一次性任务,而是持续的过程。最好的策略是建立监控、建立基线、小步迭代。记住优化的黄金法则——先测量,再优化,再测量。欢迎到 云栈社区 交流讨论更多性能优化实践。
明日预告:CPU性能计数器:PMC硬件事件的监控秘籍。我们将深入探索CPU性能监控单元(PMU),学习如何利用硬件性能计数器诊断最细微的性能问题,从缓存未命中到分支预测失败,全方位掌握CPU内部行为的监控技术。
 发表于 2025-12-30 04:54:01
|
查看: 338|
回复: 0
发表于 2025-12-30 04:54:01
|
查看: 338|
回复: 0
