RL 训练难早在大模型爆发之前就已成为业界共识,诸如 reward hacking、信用分配、致命三元组等问题,其根本原因往往在于探索与利用之间的平衡难以把握。
这里整理了在大模型 GRPO 训练中导致崩溃的常见原因及应对思路,内容侧重工程经验与机制层面的总结,并非严格的理论结论。
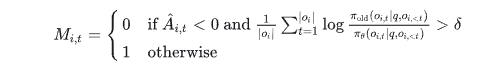
图:DeepSeek-V3.2中用于控制策略偏离的二进制掩码计算公式
01 熵坍塌 (Entropy Collapse)
熵坍塌与模型预测下一个词元的概率分布有关。简单来说,当概率分布从一个相对平坦、高不确定性的状态,退化到一个尖锐、低熵甚至单一模态的状态时,就发生了熵坍塌。
在训练过程中,如果一个词元本身的概率已经很高,同时又获得了一个较高的优势值,那么它的概率会被进一步推高,导致整个分布越发尖锐,最终走向坍塌。
对此,不同团队有不同的应对策略。上海 AI 实验室的 Clip-Cov 方法是直接停止更新,阻止分布进一步恶化。而字节的 Clip-Higher 则采取了不同思路:它认为,当低概率词元获得高优势值时,能对冲分布尖锐化的趋势,因此需要给予更大的更新幅度。
但一味抑制熵坍塌也不行,这可能导致走向另一个极端——熵爆炸。过度利用导致坍塌,过度探索则引发爆炸。因此,后续又出现了分位数优势估计等算法,旨在更灵活地调控探索与利用的平衡。
02 重要性权重 (Importance Weight) 问题
有观点认为,GRPO 只在词元级别计算重要性权重,而非在整个序列级别,这种做法存在问题。词元级的权重充满了随机噪声,失去了修正分布的真实意义。这种噪声会随着生成长度的增加而不断累积,最终像滚雪球一样引发灾难性的模型崩溃。
相应的解决思路,自然是采用序列级的重要性采样,例如 GSPO 所采用的方法。
03 训练与推理的不一致性
现代大模型训练框架通常采用混合引擎,底层封装了独立的训练引擎和推理引擎。推理引擎在效率方面做了大量优化,这可能导致其与训练引擎之间存在不一致性。
已知的解决方法包括使用 FP16 代替 BF16,以及采用截断重要性采样等技术。
04 K3 估计器存在的偏差
DeepSeek-V3.2 提出了一个见解,它将 KL 散度从独立的奖励项移入了奖励函数内部,以此来修正估计偏差。这个问题的根源在于,GRPO 在训练时很难完全维持严格的 On-policy 设定。
从工程角度看,这样做缓解了 GRPO 在多步更新下因难以维持严格 on-policy 而带来的 KL 估计偏差。当数据分布与当前策略存在偏离时,KL 作为独立正则项其梯度估计会更不稳定;将其并入奖励后,可以通过优势函数进行统一处理,从而使整个训练过程更加鲁棒。
05 引入 Off-policy 的影响
为了提高数据生成效率,通常会先生成大批量的轨迹数据,然后切分成多个小批量进行多次梯度更新。这个过程本身就引入了 Off-policy 行为。
DeepSeek-V3.2 为了解决此问题,引入了一个二进制掩码 M_i,t,用于屏蔽那些引入了显著策略偏离的负优势序列。其中,δ 是控制策略偏离阈值的超参数。这意味着模型主要从自身的错误中学习,而屏蔽那些高度 Off-policy 的负样本,因为这些样本可能会误导优化方向。
此外,在面向智能体(Agentic)的 RL 训练中,还存在一些独特的崩溃模式:
-
(1)重分词偏移
因为智能体 RL 需要将响应字符串重新分词为词元,这个过程可能引入偏差。例如,同一个单词可能有不同的分词方式,如果模型输出的词元序列在重新编码时发生了变化,就会引入巨大的 Off-policy 偏差。
-
(2)对局部正确动作的无差别惩罚
在多轮对话的早期,正确轨迹和错误轨迹往往非常相似。这意味着它们在特征空间中的嵌入高度重叠。此时,来自错误轨迹的巨大负梯度可能会“误伤”正确轨迹,强行拉低正确动作的概率,最终导致训练崩溃。
解决办法通常是更精细地控制损失函数,例如 LLDS 等方法,它们鼓励词元概率升高的行为,而惩罚概率降低的行为,这有点类似于将优势值从 +1, -1 调整为 +1, 0。
以上更多是基于工程实践的归纳与理解,欢迎从事相关工作的朋友在专业的 人工智能 技术社区中进行补充、修正或从不同视角展开讨论。技术问题的深入探讨往往能激发新的解决思路。本文内容先整理到此,后续会基于实践进行进一步补充。
本文观点整理自技术分享,已获授权发布。
 发表于 2025-12-30 04:57:03
|
查看: 313|
回复: 0
发表于 2025-12-30 04:57:03
|
查看: 313|
回复: 0
