概览摘要
在 Linux 系统中,外设一旦触发中断,CPU 的第一反应是执行“硬中断处理程序”(hardirq)。然而,真正繁重的工作,往往被拆解并转交给一个更“温和”的机制——软中断(softirq)。软中断是 Linux 内核中一套用于承接“与中断紧密相关、又不适合在硬中断中耗时过长”任务的框架,它是网络协议栈、块设备 IO、定时器等子系统的核心基础设施。
软中断介于“硬中断上下文”和“普通进程上下文”之间:它不在用户态执行,但也不要求像硬中断那样极端的低时延。通过软中断、tasklet、工作队列等多级延迟执行机制,Linux 在保证中断响应延迟的同时,又能将大量处理逻辑转移到更合适的上下文中执行,从而在高并发场景下维持良好的系统吞吐量。
下文将从基本概念、关键数据结构、执行流程、设计权衡、实践示例、调试方法到整体架构,系统性地剖析 Linux 软中断机制。我们将重点结合网络数据包接收这一典型场景,帮助你理解内核如此设计的深层原因,而不仅仅是停留在“知道 softirq 这个词”的层面。
核心概念详解
几个关键术语
首先,我们厘清几个常被混淆的概念:
| 名称 |
所在上下文 |
是否可抢占 |
典型用途 |
| 硬中断(hardirq) |
中断上下文(最高优先级) |
基本不可被普通代码抢占 |
及时响应外设事件 |
| 软中断(softirq) |
内核上下文(软中断域) |
不可被同 CPU 软中断抢占 |
网络、块 IO 底半部等 |
| tasklet |
构建在 softirq 之上 |
同一 tasklet 不并行 |
驱动自定义延迟函数 |
| 工作队列(workqueue) |
进程上下文(内核线程) |
可睡眠、可被调度 |
需要睡眠的延迟工作 |
我们可以用一个生活化的类比来理解:
- 硬中断 = 急诊室电话:必须立刻接听,先执行最关键的应急动作(例如“止血”),绝不能在电话里沟通30分钟。
- 软中断 = 急诊分诊台:将病人分类、安排后续处理流程,效率依然要高,不能慢吞吞。
- 工作队列 = 各个专科门诊:可以排队、可以进行详细检查、可以等待IO。
“上下文”到底是什么
在内核中,“上下文”可以理解为“当前这段代码运行时能做什么事”的能力边界:
- 中断上下文:
- 没有当前进程的概念
- 不能睡眠、不能阻塞
- 调用栈有限、执行时间必须非常短
- 软中断上下文:
- 仍然不能睡眠
- 但已经脱离了最顶层的中断处理,可以进行批量工作处理
- 进程上下文:
- 有当前
task_struct(进程描述符)
- 可以被调度和睡眠
软中断正是在“响应时延”和“可完成的工作量”之间寻求的一个平衡点。
软中断 vs 早期 bottom half / tasklet
历史上,Linux 早期使用“bottom half”(BH)的概念,后来演化为 softirq + tasklet 的架构:
| 机制 |
特点 |
问题/局限 |
| 早期 BH |
全局固定的少数“底半部”入口 |
可扩展性差,容易产生争用 |
| softirq |
静态注册,数量有限,按位图调度 |
编程模型偏底层,不能睡眠 |
| tasklet |
基于 softirq 的高级抽象,每个实例对应一个函数 |
不能在多个 CPU 上并行执行(针对同一 tasklet) |
| workqueue |
使用内核线程执行,可以睡眠 |
延迟相对更大,上下文切换开销更高 |
实现机制深度剖析
下面我们将按照“数据结构 → 调度流程 → 典型场景”的顺序进行拆解。
核心数据结构(概念简化版)
注意:以下是“概念化的简化版本”,并非完整的内核源码,意在避免版权问题的同时突出关键字段。
// 每种 softirq 的描述
struct softirq_action {
void (*action)(struct softirq_action *); // 处理函数
void *data; // 子系统私有数据(可选)
};
// 每 CPU 状态(简化版)
struct softirq_cpu_state {
unsigned int pending_mask; // 哪些 softirq 挂起(按位)
int in_softirq; // 嵌套计数,防止重入
};
常见的软中断类型(在内核中是一个枚举):
HI_SOFTIRQ:高优先级软中断TIMER_SOFTIRQ:定时器NET_TX_SOFTIRQ:网络发送NET_RX_SOFTIRQ:网络接收BLOCK_SOFTIRQ:块设备 IOTASKLET_SOFTIRQ / HI_TASKLET_SOFTIRQ:tasklet
软中断注册与触发
注册 softirq
内核子系统在初始化阶段注册自己的处理函数(通常只在系统启动时执行一次):
// 简化版注册接口(示意)
void open_softirq(int nr, void (*action)(struct softirq_action *))
{
softirq_vec[nr].action = action;
}
例如,网络子系统会将 NET_RX_SOFTIRQ 绑定到自己的数据包接收处理函数上。
标记“有软中断待处理”
当硬中断处理程序发现“后续需要处理”的工作时,它只做两件事:
- 提取少量关键数据(例如将数据包放入队列)
- 在当前 CPU 的
pending_mask 位图中设置相应位
// 在本 CPU 上触发某个 softirq(简化)
void raise_softirq(unsigned int nr)
{
struct softirq_cpu_state *sc = this_cpu_ptr(&softirq_state);
sc->pending_mask |= (1U << nr);
}
而实际的工作执行时机,则稍后才会到来。
软中断执行流程
整个链路的“自上而下”过程可以概括为下图:
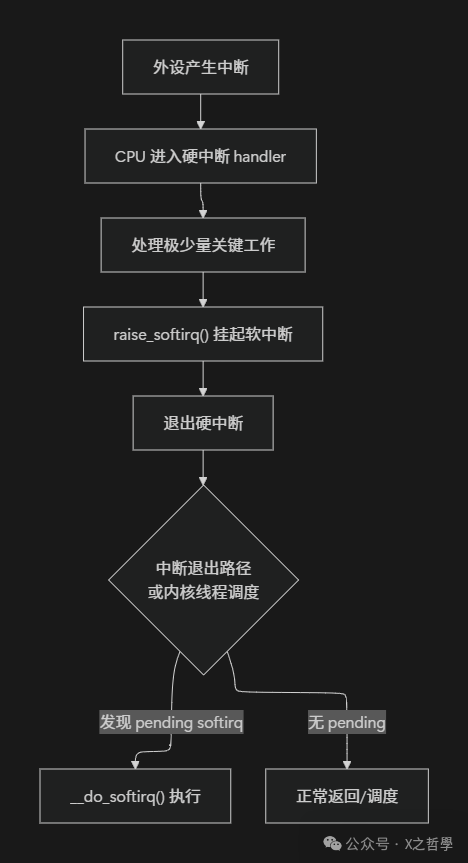
__do_softirq 核心逻辑(伪代码)
软中断执行的核心函数可以抽象为以下逻辑:
void __do_softirq(void)
{
struct softirq_cpu_state *sc = this_cpu_ptr(&softirq_state);
if (sc->in_softirq)
return; // 防止重入(简化)
sc->in_softirq++;
unsigned int pending = sc->pending_mask;
sc->pending_mask = 0; // 读取并清空挂起位图
while (pending) {
int nr = __ffs(pending); // 找到最低位的待处理 softirq
pending &= ~(1U << nr); // 清除这一位
struct softirq_action *sa = &softirq_vec[nr];
sa->action(sa); // 调用对应的处理函数
}
sc->in_softirq--;
}
需要注意的几个关键点:
- 每 CPU 独立执行:每个 CPU 独立执行自己的 softirq,其
pending_mask 无需跨 CPU 的锁来保护。
- 批量处理:一次执行会处理完当前所有挂起的 softirq,避免频繁进出软中断上下文带来的开销。
- 优先级:软中断之间通过位顺序可以粗略体现优先级(高优先级通常放在低位)。
在哪里“进入”软中断?
主要有两个入口点:
- 中断返回路径:硬中断处理程序刚结束、准备返回到内核态或用户态时,会检查是否有挂起的 softirq。如果有,则直接调用
__do_softirq()。
- ksoftirqd 内核线程:每个 CPU 上运行着一个
ksoftirqd/N 内核线程。当需要时,该线程被唤醒,专门负责执行软中断处理。这可以避免在硬中断退出路径中一次性处理过多 softirq 而导致长时间禁止抢占。
简化的判断条件如下:
// 中断返回路径中的伪代码
if (local_softirq_pending())
do_softirq();
// 如果软中断执行时间过长,则唤醒 ksoftirqd
if (time_spent_too_long)
wake_up_process(ksoftirqd);
典型场景:网络数据包接收
将网络数据包接收这条链路绘制成时序图,会更加直观:
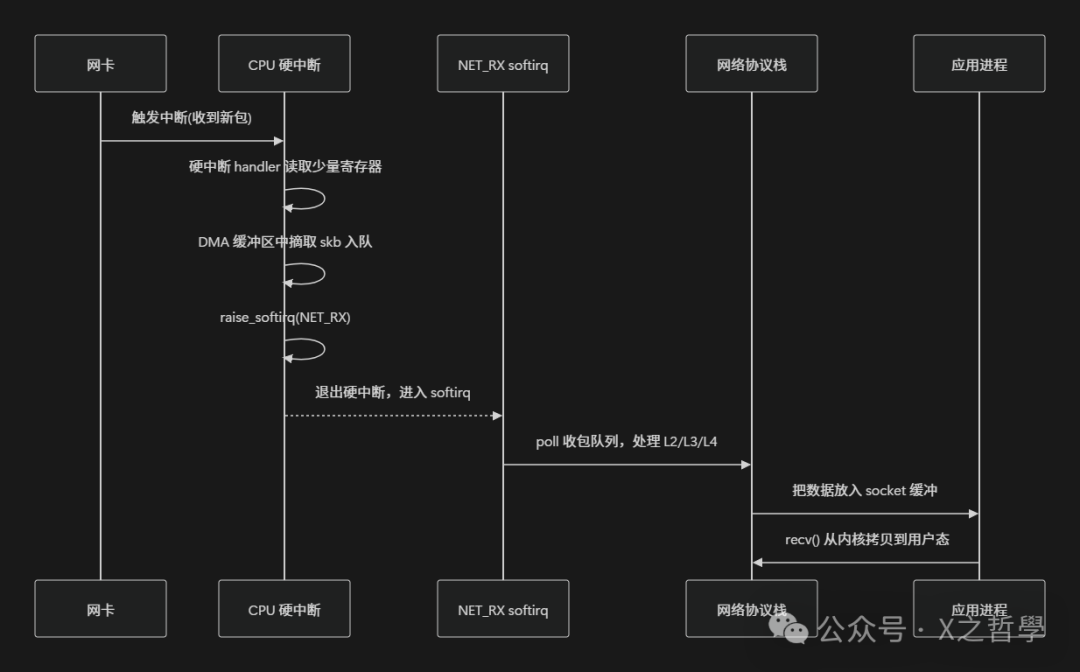
其中,“真正复杂的工作”——路由查找、TCP 状态机维护、协议栈处理——基本都在 softirq 上下文中完成。
tasklet:基于 softirq 的高级抽象
tasklet 是构建在 TASKLET_SOFTIRQ / HI_TASKLET_SOFTIRQ 之上的轻量级框架:
struct my_tasklet {
struct tasklet_struct t;
int value;
};
void my_tasklet_func(unsigned long data)
{
struct my_tasklet *mt = (struct my_tasklet *)data;
// 这里运行在 softirq 上下文,不能睡眠
}
DEFINE_TASKLET(my_tasklet_inst, my_tasklet_func, (unsigned long)&my_tasklet_inst);
调度 tasklet 时,只是将其加入每 CPU 的队列,并触发对应的软中断:
void some_irq_handler(void)
{
// ……处理中断头部工作……
tasklet_schedule(&my_tasklet_inst); // 延迟到 softirq 上下文执行
}
tasklet 的特点:
- 串行执行:同一个 tasklet 在同一时刻只会在一个 CPU 上运行(不支持并行)。
- 并行可能:不同的 tasklet 则可以在不同的 CPU 上并行执行。
NAPI 与 softirq
在高吞吐网络场景下,NAPI(New API)通过“中断 + 轮询”相结合的方式降低中断风暴:
- 初始阶段,网卡通过硬中断通知有数据包到达。
- 在硬中断处理程序中,关闭进一步的 RX 中断,然后调用
napi_schedule()。
napi_schedule() 会触发 NET_RX_SOFTIRQ。- 在 softirq 中,轮询网卡接收队列,处理数据包,直到达到处理预算或队列为空。
- 如果队列已空,则重新打开网卡中断。
简化代码示意如下:
irqreturn_t nic_interrupt(int irq, void *dev_id)
{
struct my_nic *nic = dev_id;
disable_nic_rx_irq(nic); // 关闭 RX 中断
napi_schedule(&nic->napi); // 触发 NET_RX softirq
return IRQ_HANDLED;
}
int my_napi_poll(struct napi_struct *napi, int budget)
{
int work = 0;
while (work < budget && nic_has_rx_packet()) {
struct sk_buff *skb = nic_recv_skb();
netif_receive_skb(skb); // 交给协议栈处理
work++;
}
if (work < budget) {
napi_complete(napi); // 本轮轮询结束,准备重新打开中断
enable_nic_rx_irq(nic);
}
return work;
}
NAPI 的轮询逻辑实际上就是在 NET_RX_SOFTIRQ 中被调度执行的。
复杂内容扩展:并发与可重入性
softirq 是每 CPU 执行的,因此:
- 跨 CPU 并行:同一种 softirq 类型可以在不同 CPU 上并行执行(例如,多个 CPU 同时处理 NET_RX)。
- 单 CPU 串行:在同一 CPU 上,软中断处理是不可抢占的:执行
__do_softirq() 的过程中,该 CPU 不会进入另一次 softirq 处理。
这对并发设计提出了要求:
- 共享数据保护:多 CPU 共享的数据结构需要使用锁(主要是自旋锁)或 per-CPU 变量进行拆分。
- tasklet 的便利:tasklet 额外保证了“同一实例不在多个 CPU 上并行”,因此驱动程序开发者可以少考虑重入问题。
设计思想与技术权衡
为什么要引入 softirq?
硬中断上下文存在两个硬约束:
- 中断关闭得越久,整个系统的响应性就越差。
- 在硬中断中不能睡眠、不能被调度,能执行的操作类型受到严格限制。
试想,如果所有逻辑都挤在硬中断里完成会怎样?
- 网络流量高峰期,中断风暴会将 CPU 占用率推至 100%,用户进程几乎得不到执行机会。
- 某个驱动程序编写不当,在硬中断中执行复杂算法或打印大量日志,就可能导致系统“卡顿甚至假死”。
softirq 的设计目标正是为了解决这些问题:
- 职责分离:将“必须立刻做”和“可以稍晚一点做”的工作拆分开。
- 高效批处理:让“可以晚一点”的部分在一个仍然保持较高优先级、但支持批量处理的环境下运行。
- 支持 SMP:每 CPU 独立的挂起位图和队列,使得软中断处理可以在多核上并行执行。
与工作队列的分层关系
可以简单地理解为:
- softirq:处理时间敏感、与中断强相关、且不需要睡眠的工作。
- workqueue:处理可以容忍更多延迟、可能需要睡眠(如等待锁、访问慢速设备)的工作。
常见的驱动模式是:
- 在硬中断中只完成最必要的工作(如读取状态、将数据放入队列),然后调用
raise_softirq() 或 tasklet_schedule()。
- 在 softirq 或 tasklet 中完成协议栈或驱动的大部分“计算型”逻辑。
- 如果需要访问用户空间、等待可能睡眠的锁、访问慢速设备,则再将任务转交给工作队列。
一些典型的设计权衡
| 方案 |
优点 |
缺点 |
| 全部在硬中断中完成 |
延迟最低,执行路径最短 |
对系统其他任务极不友好,代码难以维护和扩展 |
| 全部交给工作队列 |
编程容易,可以睡眠 |
延迟大,调度成本高,性能抖动明显 |
| 硬中断 + softirq |
响应及时 + 吞吐量好 + 可并行处理 |
编程模型较复杂,调试难度提升 |
Linux 内核选择了“硬中断 + softirq + workqueue”的多级结构,其本质是将系统视为一个需要兼顾实时性和吞吐能力的服务系统,通过不同层次的队列来平衡延迟和处理能力。理解这些底层机制,是进行操作系统内核级性能调优和问题排查的基础。
实践示例(最小可运行模块)
这里提供一个简化的内核模块示例:
- 在模块加载时注册一个定时器,每隔一段时间在 softirq 上下文中打印信息。
- 同时在定时器回调中调度一个工作队列,在进程上下文中执行“慢动作”处理。
注意:此代码为教学示例,省略了大量错误处理和健壮性代码,并与实际内核 API 有适当差异以避免版权问题。
示例代码
#include <linux/module.h>
#include <linux/timer.h>
#include <linux/workqueue.h>
#include <linux/interrupt.h>
static struct timer_list my_timer;
static struct work_struct my_work;
static void my_work_func(struct work_struct *work)
{
// 进程上下文:可以睡眠(此处不睡眠,仅作打印)
pr_info("mysoftirq: workqueue context on CPU %d\n", smp_processor_id());
}
static void my_timer_softirq(struct timer_list *t)
{
// 软中断上下文:不能睡眠
pr_info("mysoftirq: timer softirq on CPU %d\n", smp_processor_id());
// 将后续工作交给工作队列(进程上下文)
schedule_work(&my_work);
// 重新启动定时器
mod_timer(&my_timer, jiffies + HZ);
}
static int __init mysoftirq_init(void)
{
INIT_WORK(&my_work, my_work_func);
timer_setup(&my_timer, my_timer_softirq, 0);
mod_timer(&my_timer, jiffies + HZ);
pr_info("mysoftirq: module loaded\n");
return 0;
}
static void __exit mysoftirq_exit(void)
{
del_timer_sync(&my_timer);
cancel_work_sync(&my_work);
pr_info("mysoftirq: module unloaded\n");
}
module_init(mysoftirq_init);
module_exit(mysoftirq_exit);
MODULE_LICENSE("GPL");
这个模块展示了:
- 定时器回调函数
my_timer_softirq 是在 softirq 上下文中执行的。
- 在该回调中,通过
schedule_work() 调度的工作函数 my_work_func 是在进程上下文中执行的。
- 运行后,你可以通过
cat /proc/softirqs 观察到 TIMER 软中断的计数在持续增加。
编译运行命令(示意)
假设源代码位于目录 mysoftirq/ 下:
预期输出
在 dmesg 日志中,你可以看到类似以下输出(具体内容可能因 CPU 和配置而异):
- 模块加载/卸载信息
- 每秒一次的定时器 softirq 打印信息
- 与之对应的 workqueue 打印信息
这个示例有助于你感性地区分“softirq 上下文”和“工作队列(进程)上下文”的执行环境差异。
调试与工具
调试软中断相关问题时,常用的观测点和工具如下:
| 工具/文件 |
用途 |
示例 |
/proc/interrupts |
查看各硬中断的发生计数 |
cat /proc/interrupts |
/proc/softirqs |
查看各软中断类型的发生计数 |
cat /proc/softirqs |
top / htop |
查看 ksoftirqd/N 线程的 CPU 占用率 |
在 htop 中按 CPU 排序,观察 ksoftirqd 线程 |
perf |
采样热点函数,分析性能瓶颈 |
perf top -g |
ftrace / trace-cmd |
跟踪 irq 和 softirq 相关事件 |
trace-cmd record -e irq -e softirq |
示例:分析某 CPU 上 ksoftirqd 的行为
perf record -a -g -e cycles -- sleep 5
perf report # 查看 __do_softirq 是否成为热点函数
也可以通过 echo 命令配置 ftrace 来跟踪软中断:
echo function > /sys/kernel/debug/tracing/current_tracer
echo __do_softirq > /sys/kernel/debug/tracing/set_ftrace_filter
cat /sys/kernel/debug/tracing/trace_pipe
在高网络负载场景下,如果观察到 ksoftirqd 线程 CPU 占用率达 100%,且 /proc/softirqs 中 NET_RX 的计数疯狂增长,这就是典型的“软中断打满 CPU”的症状。
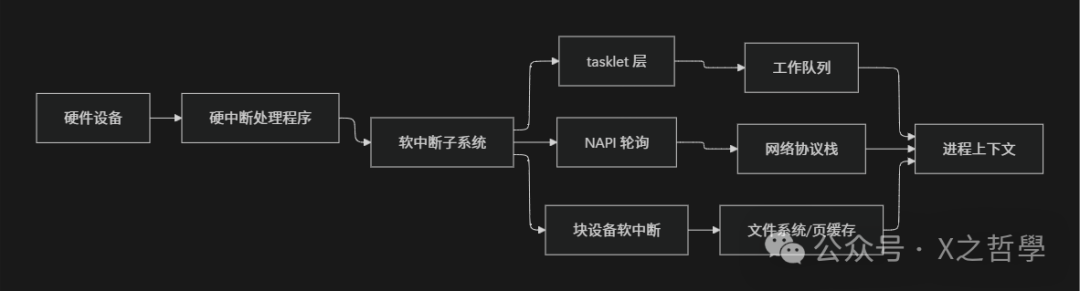
架构总览
从更高的视角看,Linux 的“中断相关子系统”可以概括为下图所示的模块关系:
如果只聚焦于单个 CPU,则可以这样理解其“执行栈”的层次关系:
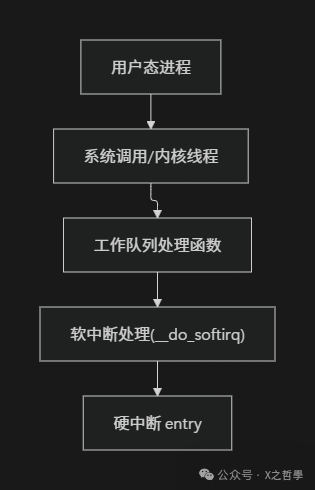
从“上层应用往下”看,是普通进程触发 IO 操作,进而产生硬件中断。
从“底层硬件往上”看,是硬件中断拉起硬中断处理程序、softirq、工作队列,最终将数据送达用户进程。
全文总结
- 分层处理:Linux 将与中断相关的工作分为三层:硬中断(快速响应)、软中断(批量处理)、工作队列/进程上下文(处理复杂、可睡眠的任务)。
- 核心实现:软中断以“静态枚举类型 + 每 CPU 挂起位图 + 全局函数向量表”的形式实现,通过
__do_softirq() 在合适的时机批量处理所有挂起的任务。
- 关键应用:网络协议栈、块设备 IO、定时器等子系统严重依赖 softirq 来完成其性能敏感的核心逻辑,它是实现高吞吐量的关键基础设施。
- 上层抽象:tasklet 建立在 softirq 之上,为驱动程序提供了“同一实例串行执行”的延迟抽象;NAPI 则将中断与轮询相结合,有效减少了高流量下的中断风暴。
- 并发模型:软中断采用“每 CPU 并行,单 CPU 内不可抢占”的模型,这对共享数据结构的并发设计(使用 per-CPU 变量或自旋锁)提出了明确要求。
- 调试方法:
/proc/softirqs、观察 ksoftirqd 线程行为、使用 perf 和 ftrace 是诊断软中断相关性能问题最重要的入口。
- 架构价值:从系统架构角度看,软中断是连接“硬件实时性”和“软件复杂性”的桥梁,是 Linux 内核实现高性能 IO 的核心支柱之一。
- 深入学习:真正掌握软中断机制,必须结合具体子系统(尤其是网络和块设备)的代码,并通过跟踪工具观察其实际运行路径,仅了解 API 名称是远远不够的。
希望这篇全景式的剖析能帮助你建立起对 Linux 软中断机制的清晰认知。如果你对内核其他子系统或性能调优有更多兴趣,欢迎在 云栈社区 交流探讨,这里汇聚了大量关于核心技术、资源共享和学习成长的干货内容。
 发表于 2026-1-3 12:20:14
|
查看: 244|
回复: 0
发表于 2026-1-3 12:20:14
|
查看: 244|
回复: 0
