
英伟达推出的Blackwell B200 GPU有望成为新一代的顶级计算GPU。与前几代产品不同,Blackwell无法像以往那样依靠制程节点的改进。台积电的4NP制程可能比上一代Hopper所使用的4N制程有所提升,但不太可能像之前的全节点缩小那样带来显著的性能提升。
因此,Blackwell放弃了英伟达久经考验的单芯片设计,转而采用两个光罩大小的芯片。这两个芯片在软件层面被视为一个独立的GPU,这使得B200成为英伟达首款芯片级GPU。每个B200芯片物理上包含80个流式多处理器(SM),类似于CPU的核心。B200每个芯片支持74个SM,因此整个GPU共有148个SM。时钟频率与 H100 的高功率 SXM5 版本相似。

我在上表中列出了 H100 SXM5 的规格,但除非另有说明,下文中的数据将来自 H100 PCIe 版本。
缓存和内存访问
B200 的缓存层级结构与 H100 和 A100 非常相似。L1 缓存和共享内存均从同一个 SM 私有池中分配。L1 缓存/共享内存的容量与 H100 相同,仍为 256 KB。L1 缓存/共享内存的分配比例也未改变。共享内存类似于 AMD 的本地数据共享 (LDS) 或 Intel 的共享本地内存 (SLM),它为一组线程提供软件管理的片上本地存储。开发者可以通过 Nvidia 的 CUDA API 来设置 L1 缓存的分配比例,例如:分配更大的 L1 缓存、分配相等的 L1 缓存或分配更多的共享内存。这些选项分别对应 216 KB、112 KB 和 16 KB 的 L1 缓存容量。
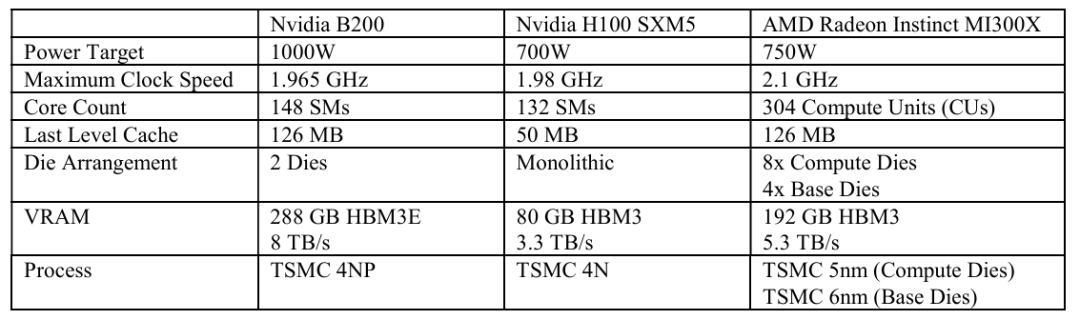
在其他 API 中,共享内存和 L1 缓存的分配完全取决于 Nvidia 的驱动程序。OpenCL 获得了最大的 216 KB 数据缓存分配,而其内核未使用共享内存,这相当合理。Vulkan 获得的 L1 缓存分配略小,为 180 KB。经测试,OpenCL 中数组索引的 L1 缓存延迟仅为 19.6 纳秒,即 39 个时钟周期。
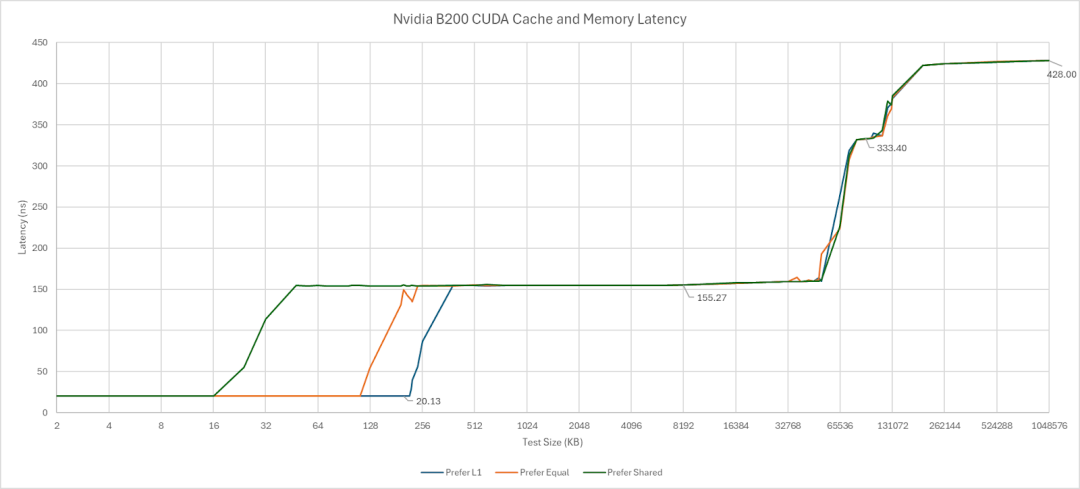
与 A100 和 H100 一样,B200 也采用了分区式 L2 缓存。然而,其容量大幅提升,总容量达到 126 MB。作为对比,H100 的 L2 缓存容量为 50 MB,A100 为 40 MB。直接连接到同一 L2 分区的延迟与前几代产品类似,约为 150 纳秒。当测试数据超出分区范围时,延迟会显著增加。B200 的跨分区延迟比其前代产品略高,但提升幅度不大。B200 上的 L2 分区几乎可以肯定对应于其两个芯片。如果是这样,跨芯片的延迟增加很小,而且单个 L2 分区的容量就超过了 H100 的整个 L2 缓存容量,因此可以忽略不计。
从单线程的角度来看,B200 的表现就像采用了三级缓存架构。L2 缓存的分区特性可以通过将指针追踪数组分段,并让不同的线程遍历每个段来体现。奇怪的是,我需要大量的线程才能访问大部分 126 MB 的容量而不产生跨分区性能损失。或许 Nvidia 的调度器会先尝试填充一个分区的 SM(流式多处理器),然后再访问另一个分区。
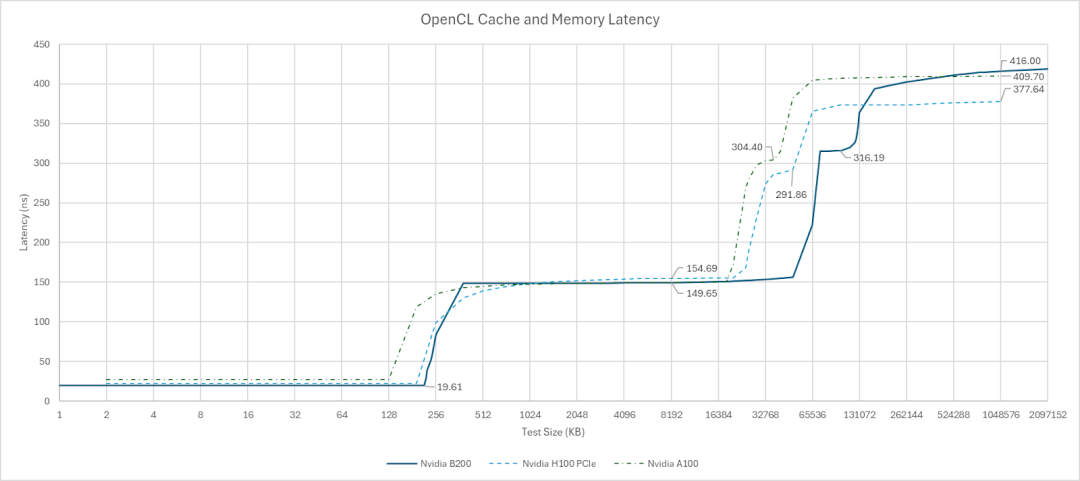
AMD 的 Radeon Instinct MI300X 采用真正的三级缓存架构,与 B200 系列显卡不相上下。Nvidia 的 L1 缓存容量更大、速度更快。AMD 的 L2 缓存牺牲了部分容量,换取了比 Nvidia 更低的延迟。最后,AMD 的 256 MB 末级缓存实现了低延迟和高容量的完美结合,其延迟甚至低于 Nvidia 的“远端”L2 分区。
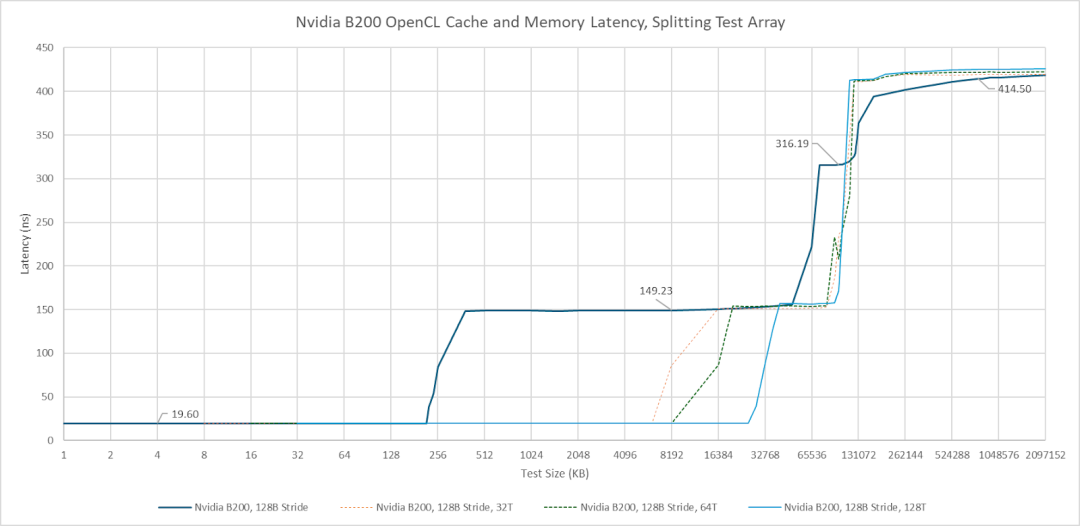
一个有趣的现象是,当多个线程访问分段指针追踪数组时,MI300X 和 B200 在末级缓存 (TLB) 上的延迟都更加均匀。然而,造成延迟增加的原因却不尽相同。AMD 平台上超过 64MB 后的延迟增加似乎是由 TLB 未命中引起的,因为使用 4KB 步长进行测试时,在同一位置也出现了延迟增加。启动更多线程会增加 TLB 实例的参与度,从而减轻地址转换的惩罚。消除 TLB 未命中惩罚也降低了 MI300X 的 VRAM 延迟。而对于 B200 来说,拆分数组并没有降低 VRAM 延迟,这表明 TLB 未命中要么在单线程情况下并非主要因素,要么增加线程数并没有减少 TLB 未命中。因此,B200 的 VRAM 延迟似乎高于 MI300X 以及更早的 H100 和 A100。与 L2 跨分区惩罚一样,与 H100/A100 相比,延迟回归的程度并不严重,这表明英伟达的多芯片设计运行良好。
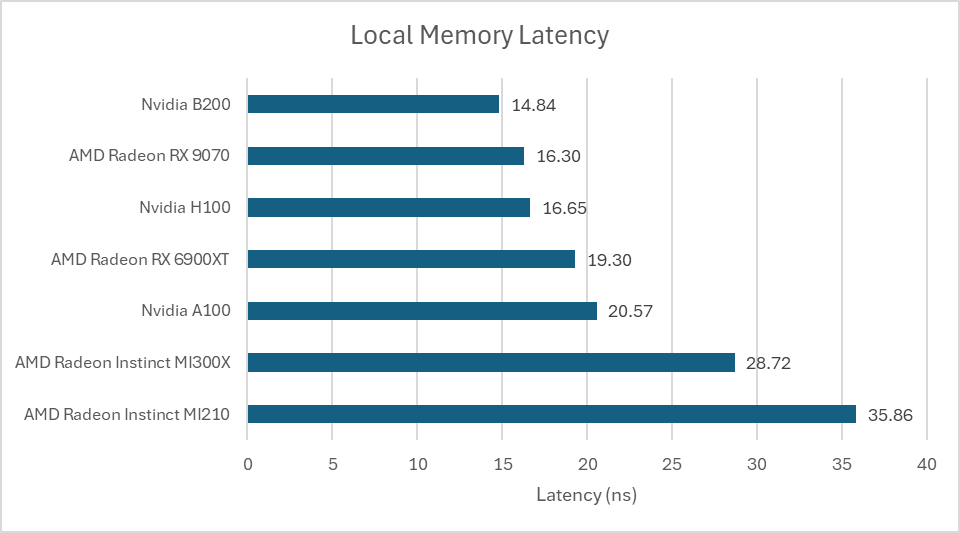
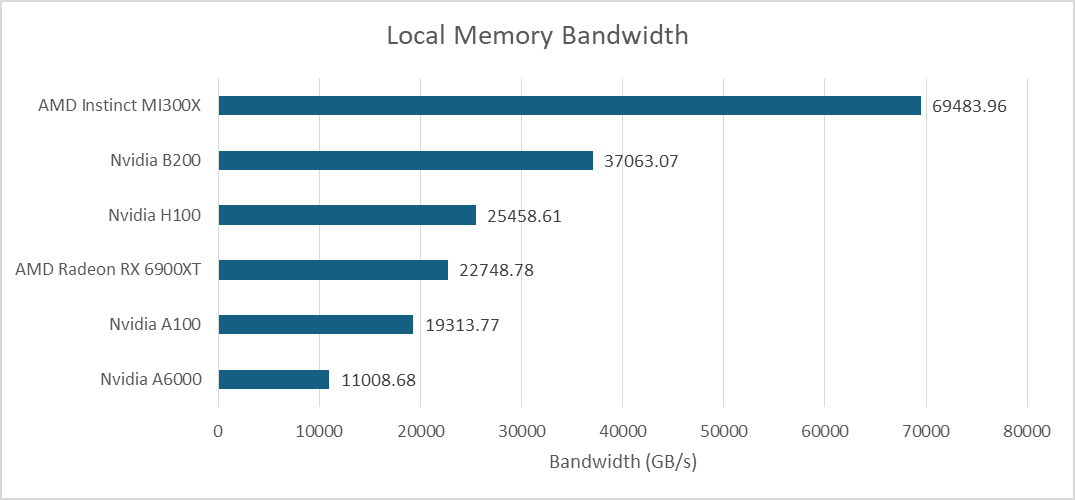
OpenCL 的本地内存空间由英伟达的共享内存 (Shared Memory)、AMD 的 LDS 或英特尔的 SLM 提供支持。使用阵列访问测试本地内存延迟表明,B200 延续了其在共享内存延迟方面的出色表现。其访问速度比我迄今为止测试过的任何 AMD GPU 都要快,包括 RDNA 系列的高频型号。AMD 基于 CDNA 架构的 GPU 的本地内存延迟则要高得多。
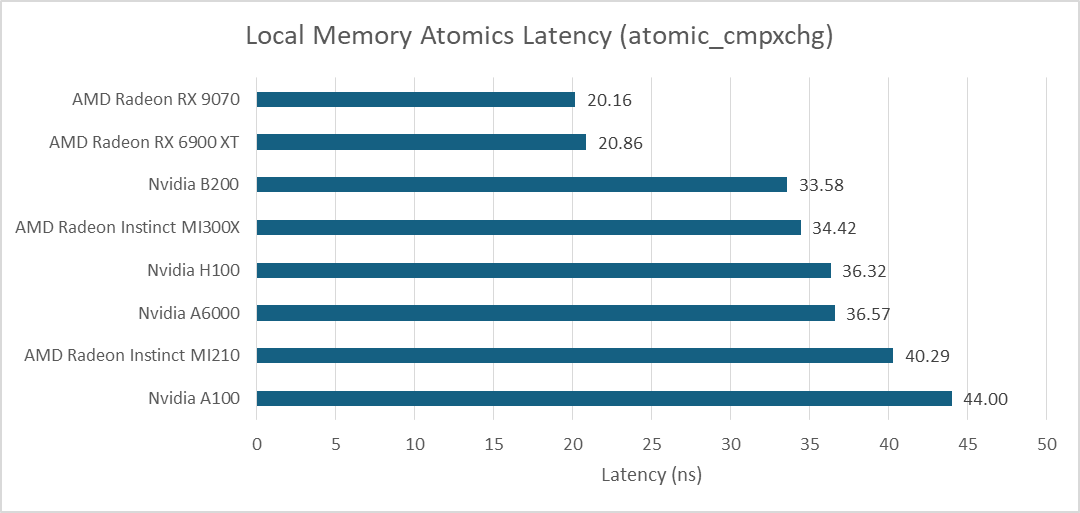
原子操作可用于在同一工作组内的线程之间交换数据。在Nvidia平台上,这意味着运行在同一SM上的线程之间交换数据。使用atomic_cmpxchg在线程间快速传递数据,其延迟与AMD的MI300X相当。与指针追踪延迟一样,B200相比前几代产品仅有小幅改进。与大型计算GPU相比,AMD的RDNA系列在此项测试中表现出色。
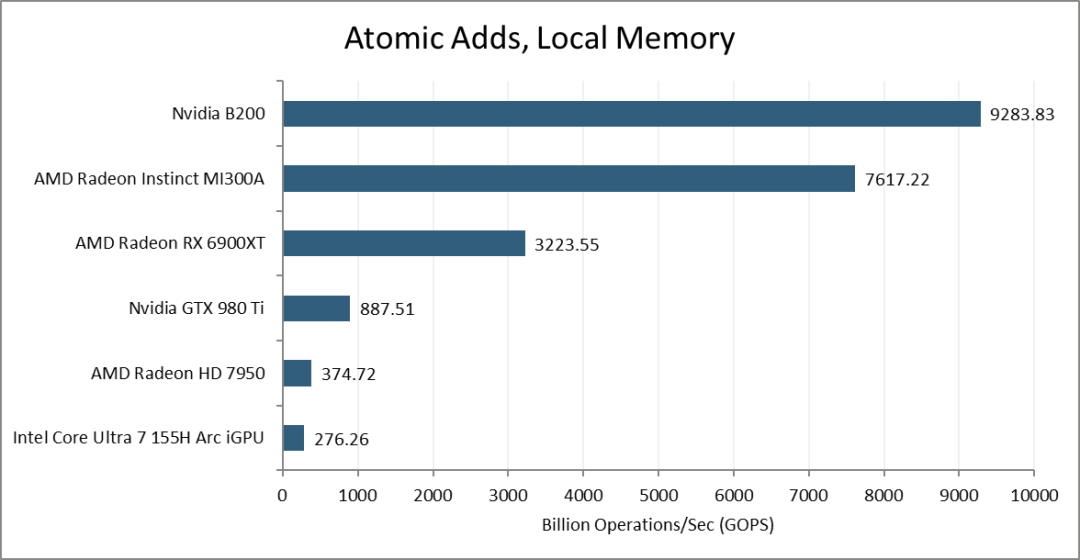
现代GPU使用专用的原子ALU来处理原子加法和递增等操作。使用atomic_add进行测试,B200的每个SM每个周期可以执行32次操作。这个测试是在MI300X测试结束后编写的,所以我只有MI300A的数据。与GCN架构类似,AMD的CDNA3计算单元每个周期可以执行16次原子加法。这使得B200尽管核心数量较少,却依然能够胜出。
带宽测量
更高的SM单元数量使B200的L1缓存带宽比其前代产品有了显著优势。在OpenCL测试中,它的性能也赶上了AMD的MI300X。而像RX 6900XT这样较老、尺寸较小的消费级GPU则被远远甩在了后面。
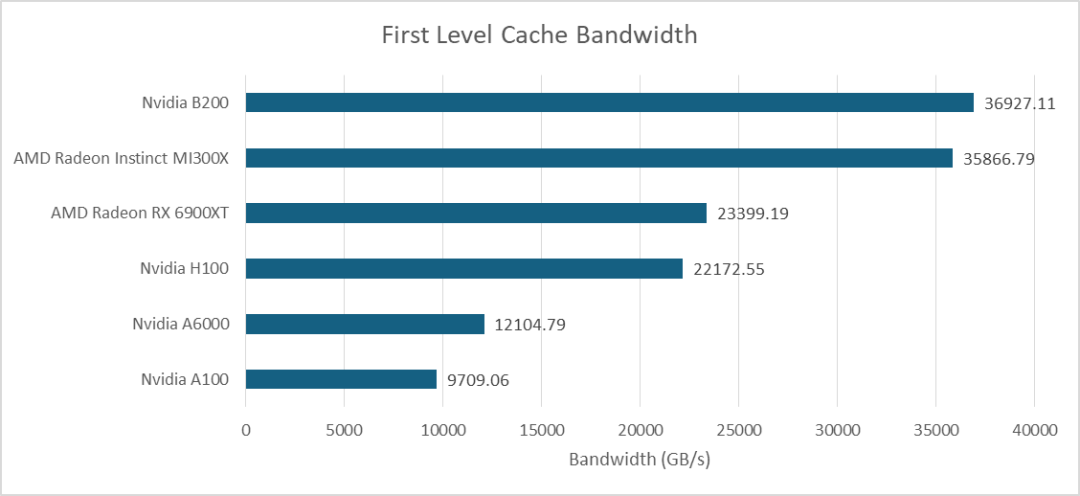
在B200平台上,本地内存和L1缓存的带宽相同,因为它们都基于同一块存储介质。这使得AMD的MI300X在带宽方面拥有巨大的优势。本地内存更难充分利用,因为开发者必须显式地管理数据移动,而缓存则能自动利用局部性。但即便如此,MI300X在这一领域依然保持领先地位。
Nemez 基于 Vulkan 的基准测试可以大致反映 B200 的 L2 带宽情况。本地 L2 分区内较小的数据量可以达到 21 TB/s 的带宽。当数据开始在两个分区之间传输时,带宽会下降到 16.8 TB/s。AMD 的 MI300X 不支持图形 API,也无法运行 Vulkan 计算。不过,AMD 指出其 256 MB 的 Infinity Cache 可以提供 14.7 TB/s 的带宽。MI300X 不需要从 Infinity Cache 获得如此高的带宽,因为其前面的 4 MB L2 实例应该可以吸收大部分 L1 缓存未命中流量。
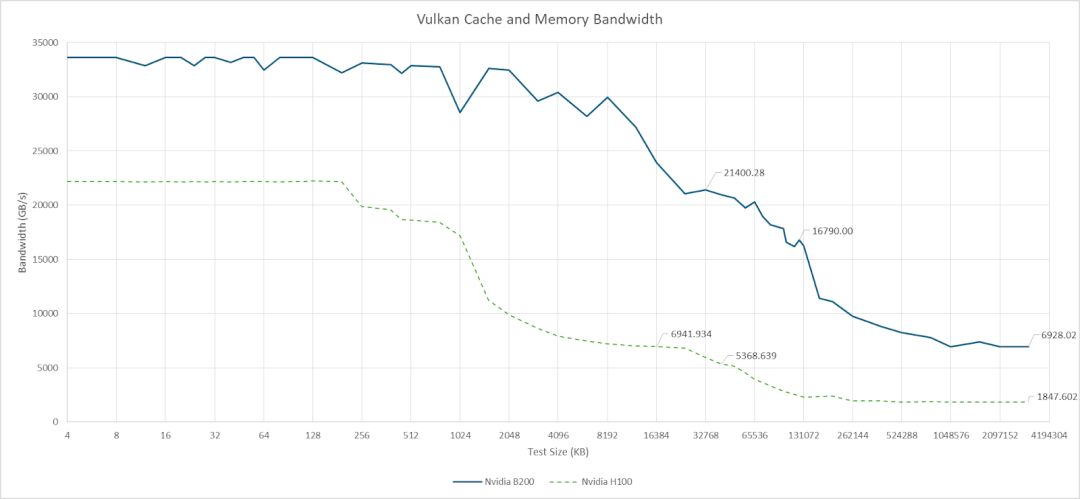
与上一代 H100 相比,B200 在缓存层次结构的各个层级都拥有显著的带宽优势。得益于 HBM3E,B200 的显存带宽也优于 MI300X。虽然 MI300X 也配备了八个 HBM 堆栈,但它使用的是较老的 HBM3,最高带宽仅为 5.3 TB/s。
全局内存原子(Global Memory Atomics)
AMD 的 MI300X 在使用 atomic_cmpxchg 在线程间切换数值时表现出不同的延迟。其复杂的多芯片结构可能是造成这种现象的原因。B200 也存在同样的问题。在这里,我启动了与 GPU 核心(SM 或 CU)数量相同的单线程工作组,并选择不同的线程对进行测试。我使用的访问模式类似于 CPU 端核心间延迟测试,但无法控制每个线程的放置位置。因此,这并非一个标准的 CPU 端核心间延迟测试,且不同运行的结果并不一致。但这足以展示延迟的变化,并表明 B200 具有双峰延迟分布。
在理想情况下,延迟为 90-100 纳秒,这很可能是因为线程位于同一个 L2 分区上。在较差的情况下,延迟则在 190-220 纳秒之间,这很可能是因为通信跨越了 L2 分区边界。AMD MI300X 的测试结果在 116 纳秒到 202 纳秒之间。B200 在理想情况下的性能略优于 AMD,但在较差情况下的性能则略逊一筹。
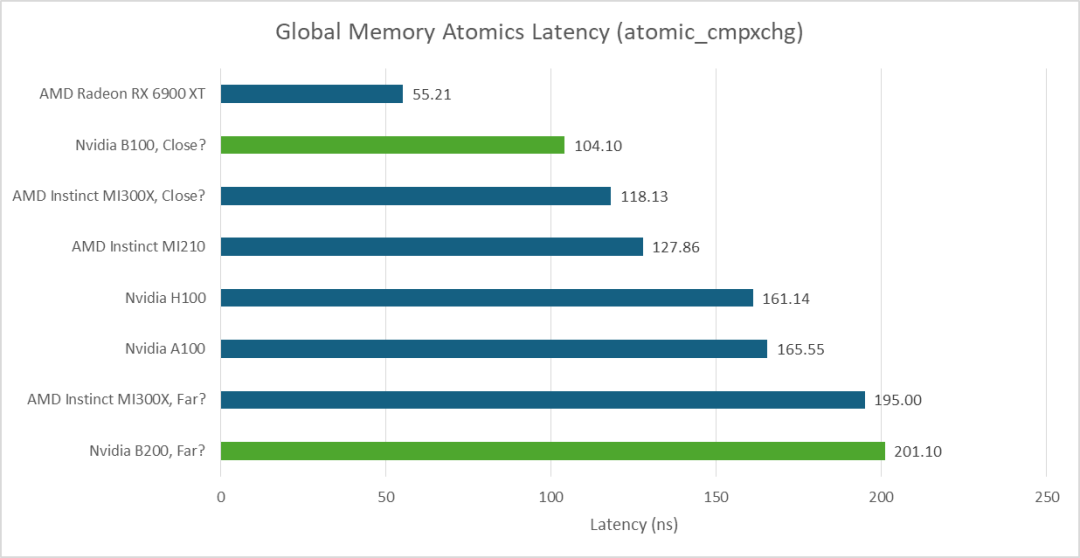
与RX 6900XT等高频消费级GPU相比,数据中心GPU的线程间延迟通常更高。即使在最佳情况下,在拥有数百个SM或CU的GPU之间交换数据也是一项挑战。

全局内存上的原子操作通常由GPU共享缓存级别的专用ALU处理。Nvidia的B200芯片每个周期可以支持GPU上近512次此类操作。AMD的MI300A芯片在这项测试中表现不佳,吞吐量甚至低于面向消费者的RX 6900XT。
计算吞吐量
SM 数量的增加使得 B200 在大多数向量运算中拥有比 H100 更高的计算吞吐量。然而,FP16 运算是个例外。Nvidia 的旧款 GPU 可以以 FP32 两倍的速度执行 FP16 运算,而 B200 则不能。
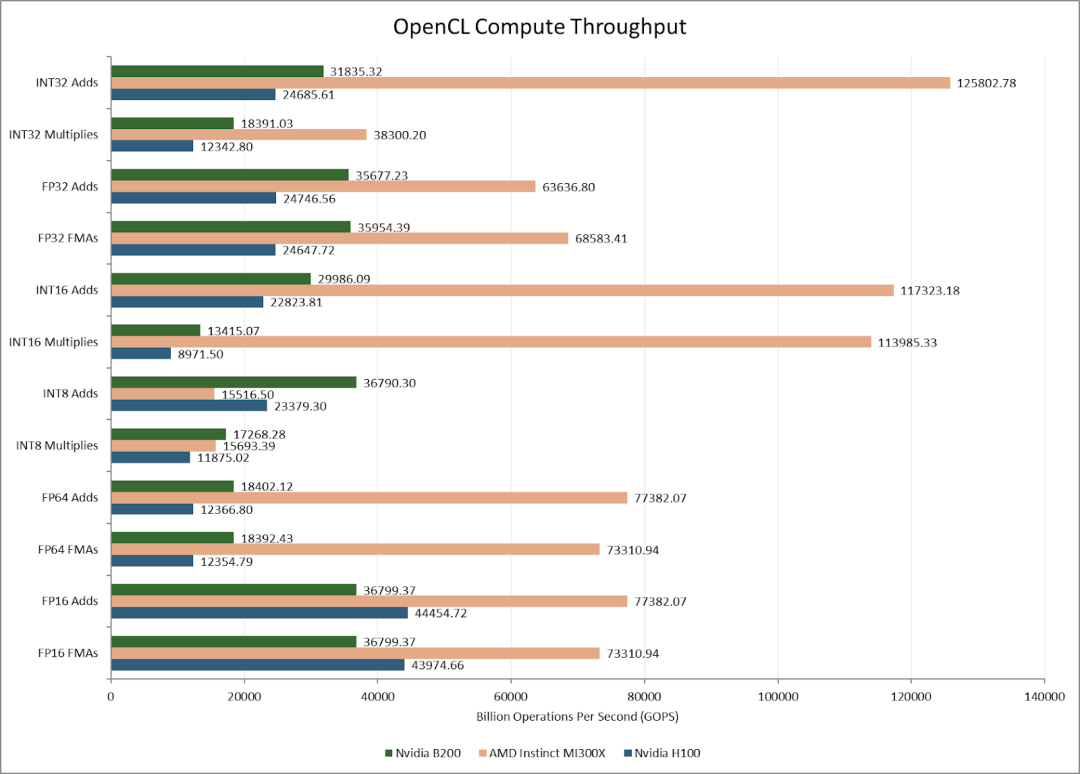
AMD 的 MI300X 也能进行双倍速率的 FP16 计算。英伟达可能决定将 FP16 计算的重点放在 Tensor Core(矩阵乘法单元)上。总的来说,MI300X 的强大运算能力在大多数向量运算方面都远超 H100 和 B200。尽管采用了较旧的制程工艺,AMD 激进的芯片组架构仍然具有优势。
张量内存
B200 的目标应用是人工智能,因此,如果不提及它的机器学习优化,讨论就不完整。英伟达早在图灵/伏特架构时代就开始使用张量核心(Tensor Core),也就是专用的矩阵乘法单元。GPU 提供了一种 SIMT 编程模型,开发者可以将每个通道视为一个独立的线程,至少从正确性的角度来看是如此。张量核心打破了 SIMT 的抽象,要求矩阵在一个波(或向量)上采用特定的布局。Blackwell 的第五代张量核心更进一步,允许矩阵在一个工作组(CTA)中跨越多个波。

Blackwell 还引入了张量内存(Tensor Memory,简称 TMEM)。TMEM 类似于专用于张量核心(Tensor Core)的寄存器文件。开发人员可以将矩阵数据存储在 TMEM 中,Blackwell 的工作组级矩阵乘法指令使用 TMEM 而非寄存器文件。TMEM 的组织结构为 512 列 x 128 行,每个单元格为 32 位。每个波形只能访问 32 行 TMEM 数据,具体行数由其波形索引决定。这意味着每个 SM 子分区都有一个 512 列 x 32 行的 TMEM 分区。“张量核心收集器缓冲区”(TensorCore Collector Buffer)可以利用矩阵数据重用,充当 TMEM 的寄存器重用缓存。
因此,TMEM 的工作方式类似于 AMD CDNA 架构上的累加器寄存器文件 (Acc VGPR)。CDNA 的 MFMA 矩阵指令同样操作 Acc VGPR 中的数据,但 MFMA 也可以从常规 VGPR 中获取源矩阵。在 Blackwell 架构上,只有较早的波形级矩阵乘法指令才接受常规寄存器输入。TMEM 和 CDNA 的 Acc VGPR 容量均为 64 KB,因此两种架构的每个执行单元分区都拥有 64+64 KB 的寄存器文件。常规向量执行单元无法从 Nvidia 的 TMEM 或 AMD 的 Acc VGPR 中获取输入。
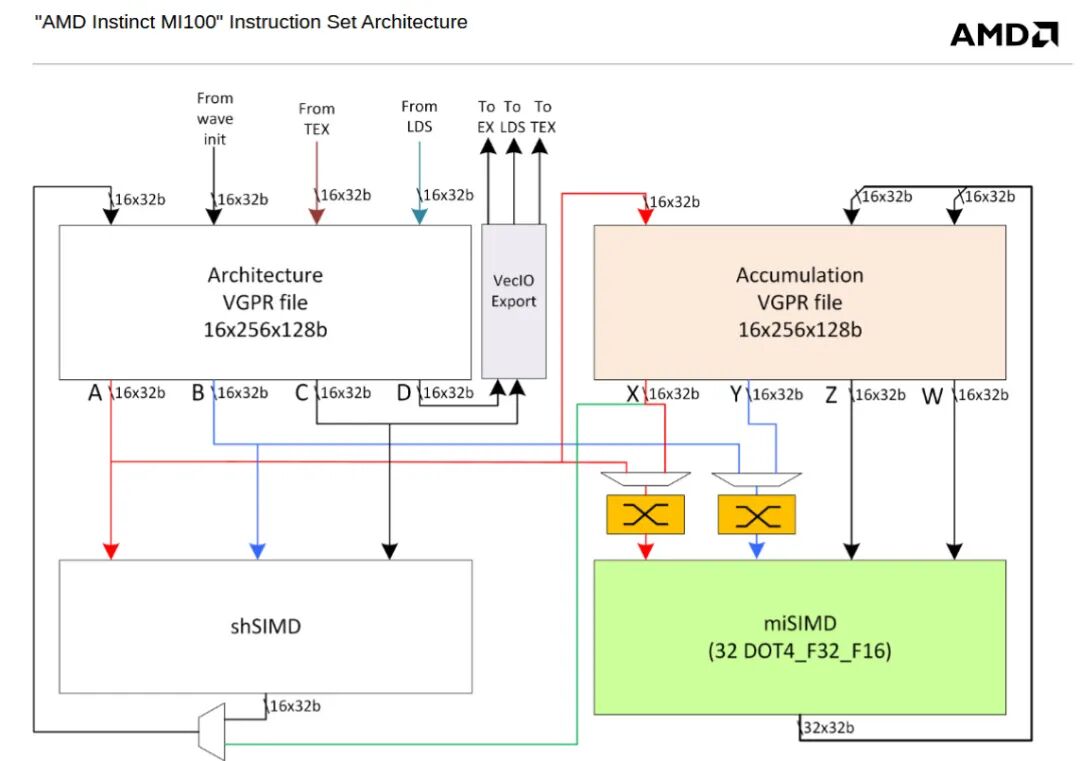
尽管 Blackwell 的 TMEM 和 CDNA 的 Acc VGPR 在总体目标上相似,但 TMEM 对分离式寄存器文件理念的实现更加完善和成熟。CDNA 必须为每个 wave 分配相同数量的 Acc 和常规 VGPR。这样做可能简化了簿记,但却造成了一种不灵活的安排,即混合使用矩阵波和非矩阵波会导致寄存器文件容量的低效利用。相比之下,TMEM 使用了一种动态分配方案,其原理类似于 AMD RDNA4 上的动态 VGPR 分配。每个 wave 开始时都没有分配 TMEM,并且可以分配 32 到 512 列(以 2 的幂次方为单位)。所有行同时分配,并且 wave 必须在退出前显式释放已分配的 TMEM。TMEM 还可以从共享内存或常规寄存器文件加载,而 CDNA 的 Acc VGPR 只能通过常规 VGPR 加载。最后,TMEM 可以在加载数据时选择性地将 4 位或 6 位数据类型“解压缩”为 8 位。
与之前的英伟达架构相比,引入 TMEM 有助于降低常规寄存器文件的容量和带宽压力。引入 TMEM 可能比扩展常规寄存器文件更容易。Blackwell 的 CTA 级矩阵指令每个周期、每个分区可以支持 1024 次 16 位 MAC 操作。由于矩阵输入始终来自共享内存,TMEM 每个周期只需读取一行并将其累加到另一行。而常规向量寄存器对于 FMA 指令则需要每个周期进行三次读取和一次写入。此外,TMEM 无需连接到向量单元。所有这些特性使得 Blackwell 能够像拥有更大的寄存器文件一样运行,从而简化硬件。自 2012 年 Kepler 架构以来,英伟达一直使用 64 KB 的寄存器文件,因此增加寄存器文件容量似乎势在必行。TMEM 在某种程度上实现了这一点。
AMD方面,CDNA2放弃了专用的Acc VGPR,并将所有VGPR合并到一个统一的128KB寄存器池中。采用更大的统一寄存器池可以使更广泛的应用程序受益,但代价是无法简化某些硬件。
一些简单的基准测试
数据中心级GPU历来拥有强大的FP64性能,B200也不例外。其基本FP64运算速度仅为FP32的一半,远超消费级GPU。在我们自行编写的基准测试中,B200的表现依然优于消费级GPU和H100。然而,即便MI300X是一款即将停产的GPU,其庞大的体积依然显露无疑。
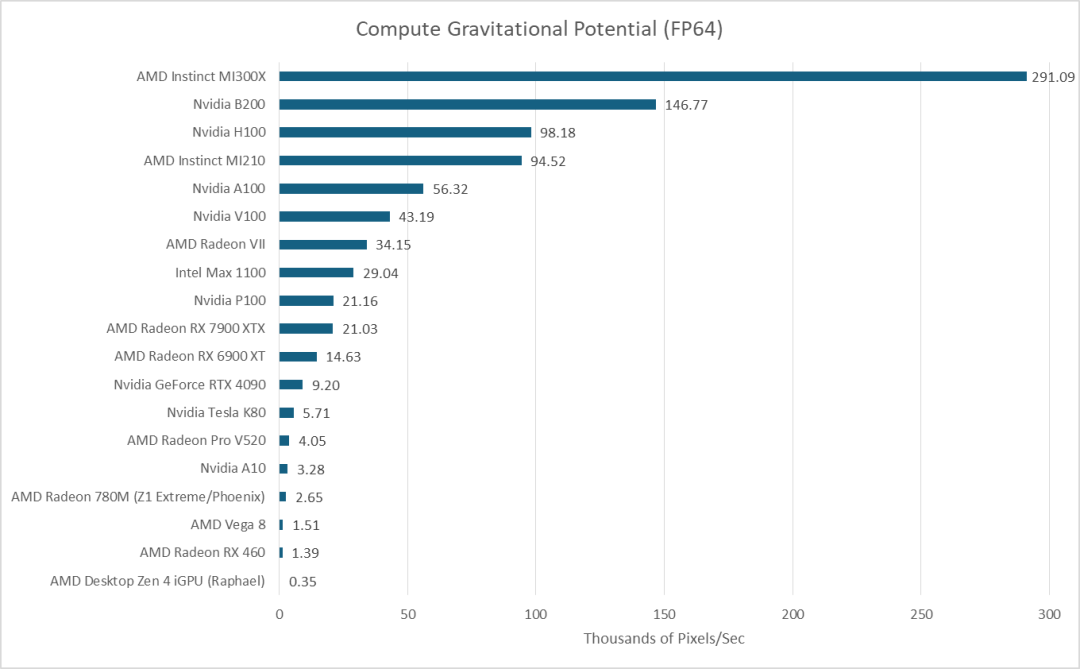
在上述工作负载中,我使用一个 2360x2250 的 FITS 文件(包含列密度值)并输出相同尺寸的引力势值。因此,数据量为 85 MB。即使没有性能计数器数据,也可以合理地假设它能够放入 MI300X 和 B200 的末级缓存中。
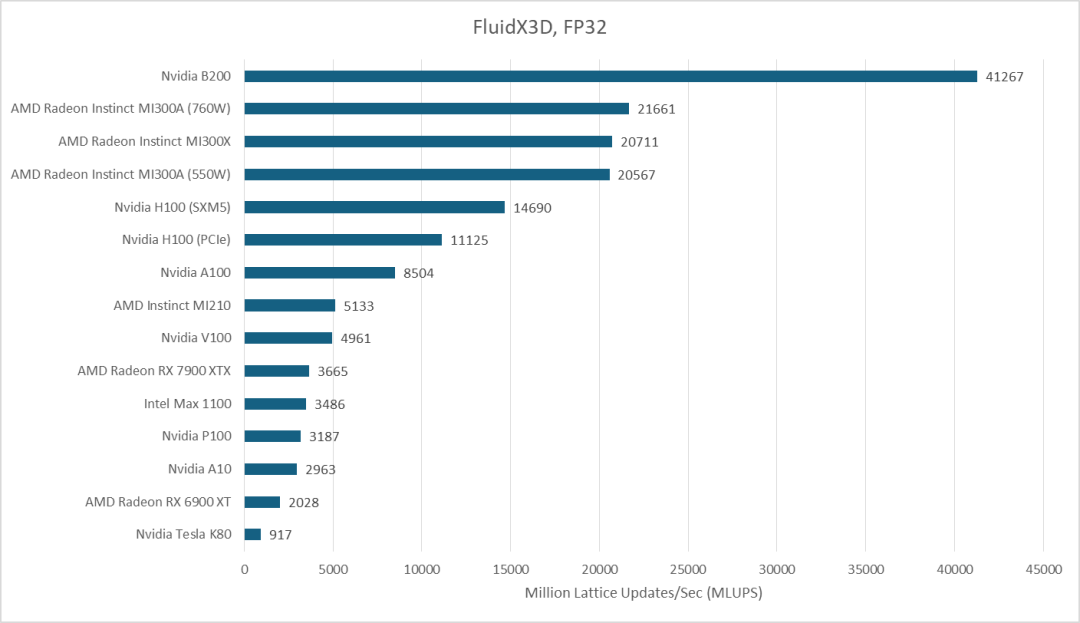
FluidX3D 的情况则有所不同。它的基准测试采用 256x256x256 的单元配置,FP32 模式下每个单元占用 93 字节,因此需要 1.5 GB 的内存。根据在 Strix Halo 显卡上使用性能计数器进行的测试,它的访问模式对缓存并不友好。FluidX3D 充分发挥了 B200 的显存带宽优势,目前 B200 的性能已经超越了 MI300X,这证明了其在智能 & 数据 & 云领域,尤其是在需要高带宽模型训练和数据密集型计算场景下的潜力。
FluidX3D 还可以使用 16 位浮点格式进行存储,从而降低内存容量和带宽需求。计算仍然使用 FP32,格式转换需要额外的计算资源,因此 FP16 格式可以带来更高的计算带宽比。这通常会提升性能,因为 FluidX3D 的性能很大程度上受限于带宽。当使用 IEEE FP16 进行存储时,AMD 的 MI300A 略有进步,但仍然远胜于 B200。
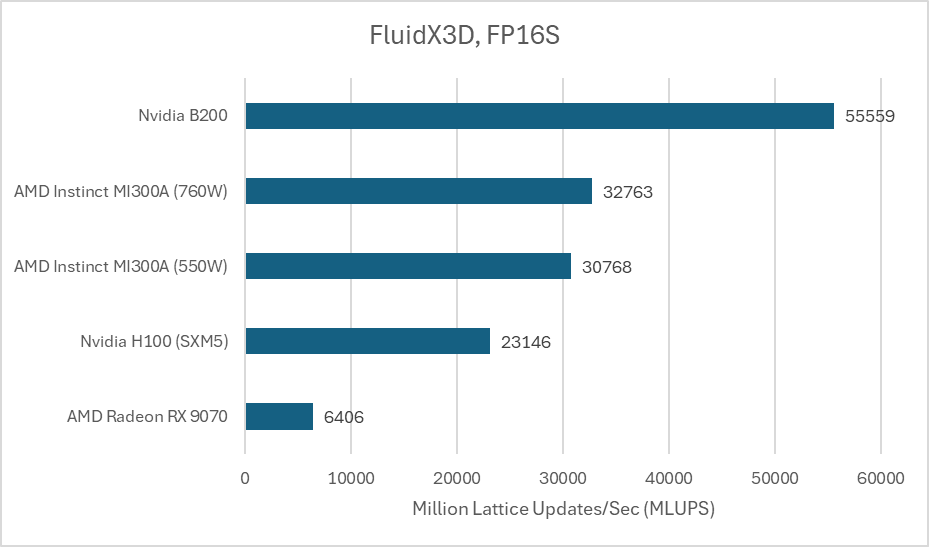
另一种 FP16C 格式降低了使用 16 位存储格式带来的精度损失。它是一种无需硬件支持的自定义浮点格式,这进一步提高了计算带宽比。
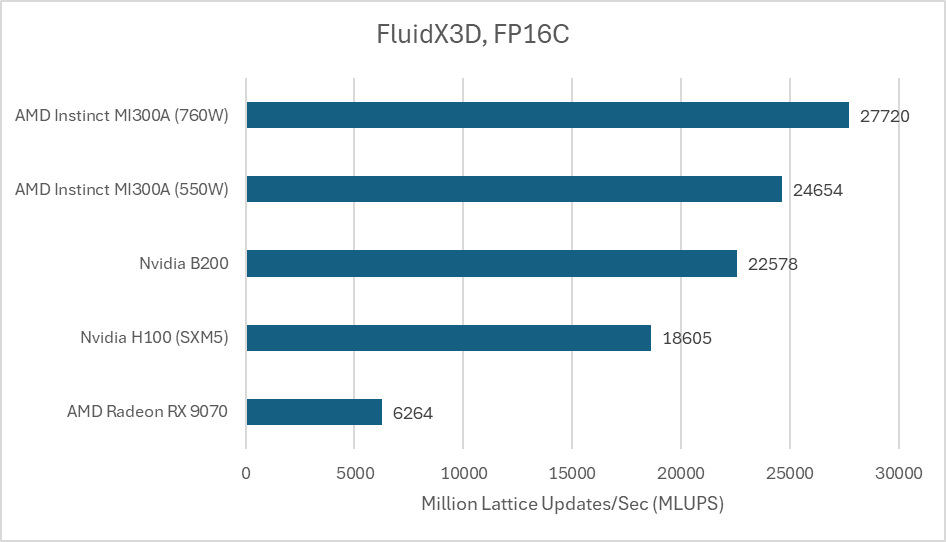
计算能力再次成为焦点,AMD 的 MI300A 脱颖而出。B200 的表现也不错,但它无法与 AMD 大型芯片 GPU 所提供的强大计算吞吐量相媲美。
结语
英伟达在芯片组升级方面并未做出重大性能妥协。B200 是 H100 和 A100 的直接继任者,软件无需考虑多芯片架构。与 AMD 的 MI300X(12 芯片怪兽)相比,英伟达的多芯片策略显得较为保守。尽管 MI300X 已是即将停产的产品,但它仍然保留了一些令人惊喜的优势,优于英伟达最新的 GPU。AMD 即将推出的数据中心 GPU 很可能也会保持这些优势,同时在 B200 已经领先一些的领域迎头赶上。例如,MI350X 将把显存带宽提升至 8 TB/s。

但英伟达的保守策略是可以理解的。他们的优势不在于打造市面上最强大、性能最卓越的GPU,而在于其CUDA软件生态系统。GPU计算代码通常首先针对英伟达GPU编写,而对非英伟达GPU的考虑则往往是次要的,甚至根本不会考虑。硬件如果没有相应的软件运行,就毫无用处,而快速移植也无法获得同等程度的优化。英伟达无需在所有方面都与MI300X或其后续产品匹敌,他们只需要足够优秀,足以阻止竞争对手填补CUDA的“护城河”即可。试图打造一款能够与MI300X匹敌的“怪物”风险极大,而英伟达在占据市场主导地位的情况下,完全有理由规避风险。
尽管如此,英伟达的策略也给AMD留下了机会。AMD如果敢于冒险、追求卓越,必将获益匪浅。像MI300X这样的GPU堪称硬件工程的杰作,充分展现了AMD实现高难度设计目标的能力。英伟达保守的硬件策略和强大的软件实力,尤其是其核心的CUDA和人工智能加速库生态,能否使其继续保持领先地位,值得我们拭目以待。
来源与参考
- 原文:chipsandcheese.com/p/nvidias-b200-keeping-the-cuda-juggernaut
- Blackwell Tuning Guide, indicating 126 MB of L2 capacity
- Inside Blackwell (Nvidia site)
- Tensor Memory Documentation
- Hopper Whitepaper
- AMD CDNA (MI100) ISA Manual
本文技术分析由社区成员分享,关于GPU架构、AI算力及更多前沿技术讨论,欢迎访问 云栈社区 与广大开发者深入交流。
 发表于 2026-1-4 16:24:30
|
查看: 259|
回复: 0
发表于 2026-1-4 16:24:30
|
查看: 259|
回复: 0
