一、核心问题:硬件潜力与软件现实的巨大鸿沟
在过去十年中,闪存固态硬盘(Flash SSDs)已取代磁盘,成为操作型数据库系统的默认持久存储介质。NVMe SSD阵列的性能更是接近了直接访问内存的带宽水平。但这是否意味着,只要我们购买最好的NVMe SSD,系统性能就能获得线性提升?
现实往往更复杂。当系统压力上升时,性能可能并未如预期般提高,CPU利用率却可能暴增。这并非空谈,以下实验数据清晰地揭示了问题所在。
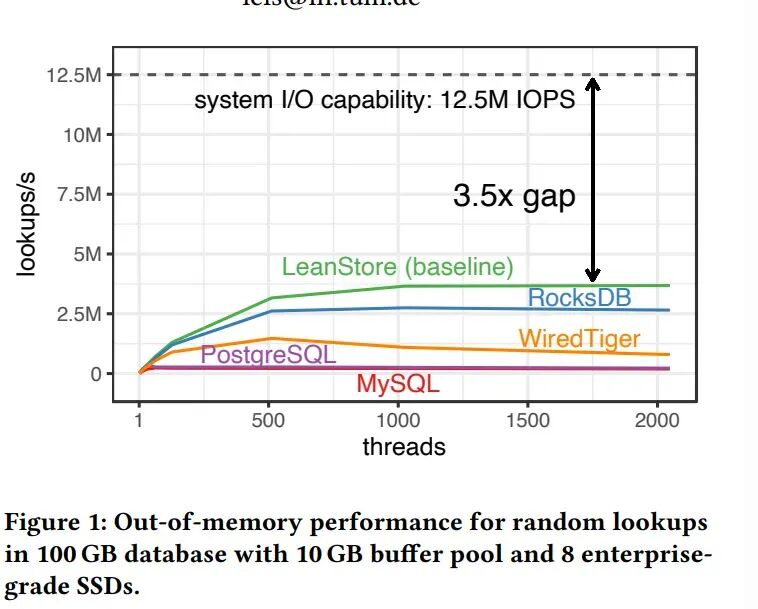
图1:在100GB数据库、10GB缓冲池及8块企业级NVMe SSD环境下,各系统的随机查找性能对比。
从图中可以直观看到,即便是MySQL、RocksDB等广泛使用的软件,在启用1000-2000个线程的高并发场景下,其性能也仅能发挥出硬件潜能的很小一部分。
| 系统/指标 |
最高性能 (IOPS) |
达到峰值所需线程数 |
与硬件极限的差距 |
| 硬件极限 |
12.5 M |
不适用 (参考线) |
0 (基准) |
| LeanStore (基准版) |
~3.6 M |
约 1500 线程 |
3.5倍 |
| RocksDB |
~2.8 M |
约 1000 线程 |
4.5倍 |
| WiredTiger |
~1.8 M |
约 500 线程 |
约7倍 |
| PostgreSQL |
~1.3 M |
约 1500 线程 |
约9.6倍 |
| MySQL |
~0.8 M |
约 1000 线程 |
约15.6倍 |
这张图基于一个典型的“内存外”场景:一个100 GB的数据库,仅使用10 GB的缓冲池,数据量是内存的10倍。测试使用8块企业级NVMe SSD,负载为随机查找。结果证明了两个关键事实:
- 现代NVMe SSD阵列拥有巨大的性能潜力(理论可达1250万IOPS)。
- 现有主流存储引擎存在显著的性能鸿沟,最高仅能利用约29%的硬件能力。
这个性能差距的根源是什么?简单来说,I/O本身(数据在SSD和内存间传输)确实不占用CPU,但管理这些海量I/O请求的过程——包括生成、提交、跟踪、完成通知和错误处理——会消耗大量的CPU时间。
当系统需要调度数百万IOPS时,CPU处理能力本身就成了瓶颈。传统的、基于操作系统线程的同步I/O架构,无法协调现代NVMe硬件所要求的极高请求级并行性、有限CPU核心数和高SSD I/O深度之间的矛盾,导致了线程过度订阅、高上下文切换开销和严重的CPU瓶颈。
那么,如何通过重新设计存储引擎的I/O架构来弥合这一性能鸿沟?这正是VLDB 2023上发表的论文《What Modern NVMe Storage Can Do, And How To Exploit It》所回答的核心问题。
二、论文核心解答:六个关键设计决策
该论文通过系统性的实验和分析,回答了六个关键的研究问题,为构建高性能存储引擎提供了清晰的路线图。
| 问题编号 |
研究问题 |
论文给出的核心解答与发现 |
| Q1 |
NVMe阵列能否达到硬件标称的性能? |
可以,甚至能超越。 实验证实,8块NVMe SSD组成的阵列能够实现1250万次/秒的随机读取IOPS,超过了单盘标称性能的简单叠加。 |
| Q2 |
应该使用哪种I/O API?是否需要内核旁路? |
1. 所有异步接口都能实现高吞吐。 2. 内核旁路在CPU效率上具有绝对优势,但io_uring在轮询模式下也能接近其性能。对于追求极致效率,SPDK是最佳选择。 |
| Q3 |
存储引擎应使用多大的页大小? |
4 KB是最佳权衡点。 这是NVMe SSD随机读取性能的“甜点”,能同时优化IOPS、带宽和延迟。更大页面会导致严重的I/O放大。 |
| Q4 |
如何管理实现高SSD吞吐所需的高并发度? |
必须采用用户态协作式多任务。 传统“一个查询一个OS线程”的模型开销巨大。论文通过用户态任务调度,使少量工作线程能高效管理海量并发的I/O请求。 |
| Q5 |
如何让存储引擎足够快? |
内存外代码路径必须深度优化和并行化。 包括:采用分区锁消除热点、优化淘汰算法、移除内存分配、以及微调热代码路径。 |
| Q6 |
I/O应由专用I/O线程还是工作线程执行? |
应由工作线程直接执行。 论文采用对称设计:每个工作线程拥有通往所有SSD的独立I/O通道,无需线程间通信,实现了最佳可扩展性。 |
下面,我们将深入探讨其中几个最关键的技术选型与设计。
三、关键技术实现:从CPU瓶颈回归I/O瓶颈
3.1 I/O接口选择:效率至上的内核旁路
要发挥NVMe硬件的全部实力,首先要选对“沟通方式”。论文比较了Linux上几种主要的存储I/O接口。
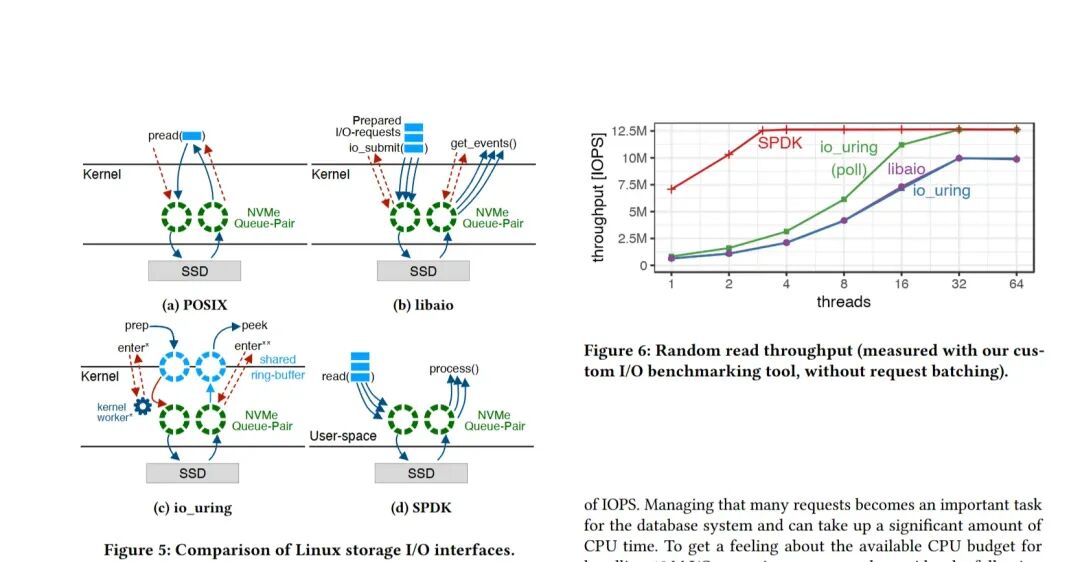
图:四种I/O接口的架构对比及其随机读取吞吐量性能。
- SPDK:性能最佳,CPU开销最低。仅需3个线程即可达到峰值带宽,因为它完全绕过了操作系统内核。
- io_uring(轮询模式):最先进的内核异步I/O方案,性能接近SPDK,是内核空间的强大替代。
- libaio:传统异步接口,可实现高吞吐,但接口较原始,在高并发下效率可能成为瓶颈。
- 阻塞式POSIX:完全无法满足高性能需求,线程模型与NVMe的并行能力严重不匹配。
结论是明确的:要“榨干”性能,必须使用异步接口。SPDK凭借其极致的CPU效率成为首选,而io_uring则为希望留在内核空间的系统提供了优秀的备选方案。
3.2 理解NVMe的并行核心:队列对
为什么SPDK和io_uring能如此高效?这需要理解NVMe硬件的底层设计——队列对。
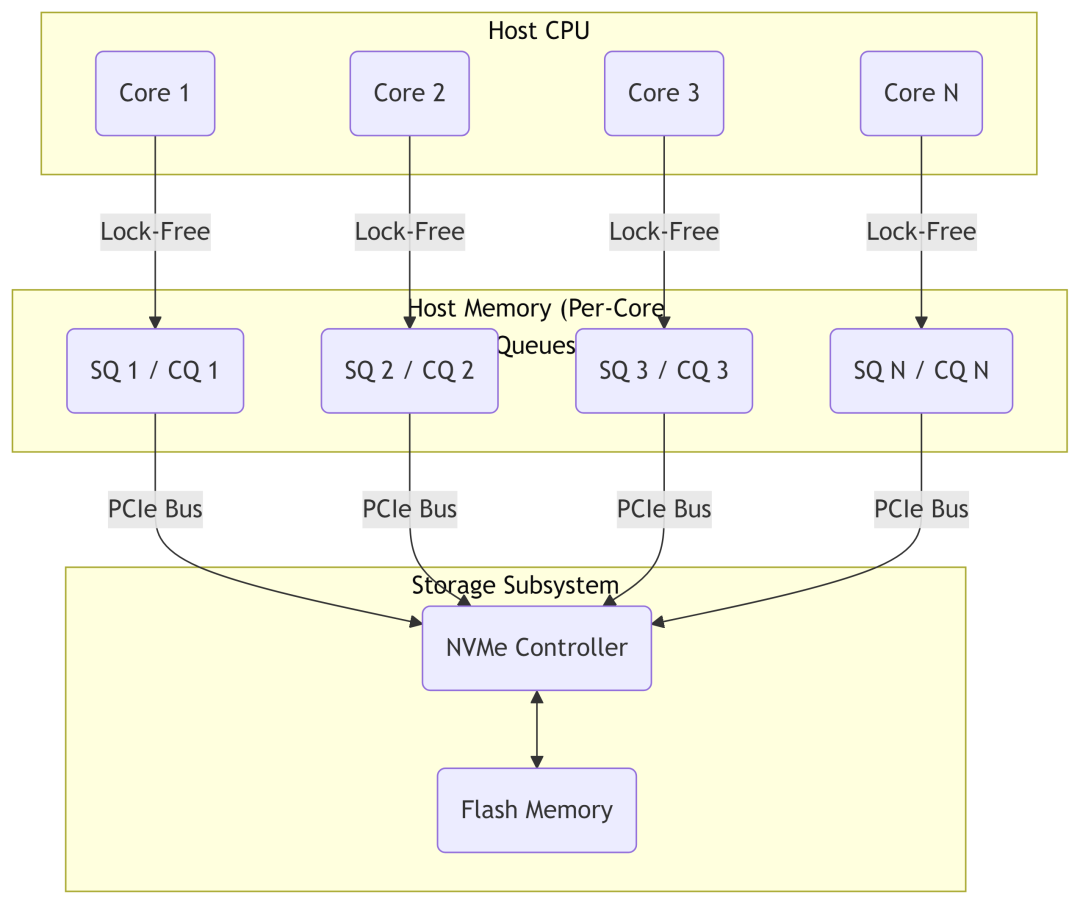
图:NVMe允许多个CPU核心通过独立的队列对无锁访问SSD。
一个NVMe队列对包含一个提交队列和一个完成队列,构成了主机与SSD之间高效的生产者-消费者模型。其革命性在于:
- 极高的并行性:一个NVMe设备可支持数万个队列对。
- 无锁模型:每个CPU核心可以拥有自己专属的队列对,彻底避免了多核争用锁的开销。
无论使用哪种I/O库,最终目标都是高效地将请求放入提交队列,并从完成队列取出结果。SPDK等方案的优势在于,它们在用户态直接操作这些队列,消除了所有不必要的内核路径开销。
3.3 线程与I/O模型:对称、集成的全对全设计
选择了高效的I/O接口后,接下来需要在软件层面设计一个能管理海量并发请求的架构。论文提出的核心思想是:让少数工作线程身兼多职,并直接处理所有I/O。
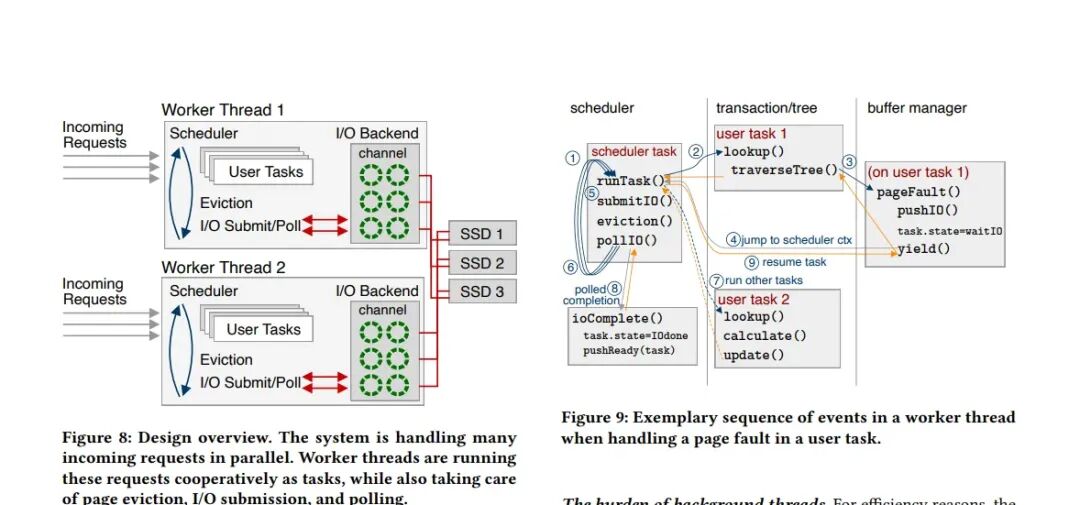
图:系统设计概览,展示了工作线程如何集成处理用户任务、页面淘汰和I/O操作。
工作线程采用用户空间协作式多任务模型:
- 职责集成:每个线程不仅执行用户查询,还负责页面淘汰、I/O提交和轮询完成事件。
- 协作式调度:当用户任务遇到页错误(需触发I/O)时,会提交异步请求,然后将自身挂起,让出CPU。调度器接着处理I/O提交、淘汰等后台工作。I/O完成后,回调函数将任务状态置为就绪,等待下次调度执行。
I/O后端是一个软件抽象层,为工作线程提供统一的I/O接口。关键在于其连接模型:
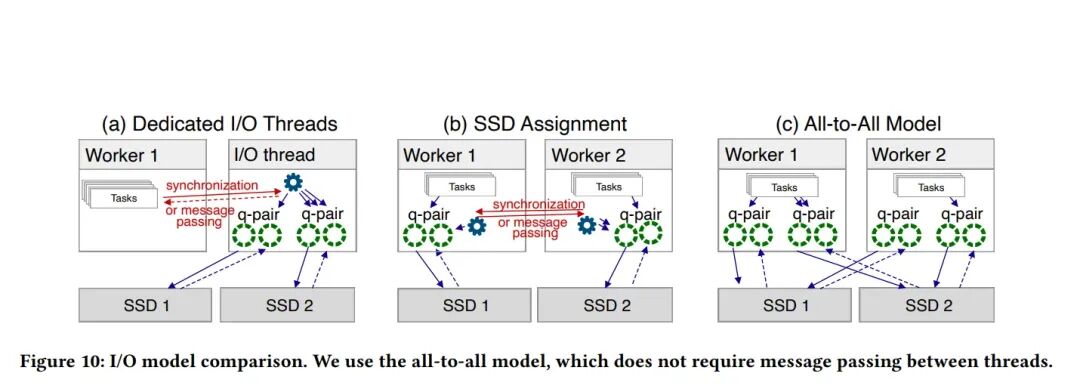
图:三种I/O连接模型对比。论文采用了无需线程间通信的“全对全模型”。
论文否定了“专用I/O线程”或“SSD绑定给特定线程”的模型,采用了全对全模型:
- 每个工作线程都拥有自己独立的I/O通道,该通道管理着到所有SSD的直接连接。
- 无需任何线程间消息传递或同步。任何工作线程都可以直接向任何SSD提交请求。
- 这种对称设计简化了架构,并实现了最佳的可扩展性和健壮性。
3.4 页面大小选择:4KB是最佳权衡
存储引擎的页面大小对性能有深远影响。更大的页面可能带来更高的顺序带宽,但在以随机访问为主的数据库负载中呢?
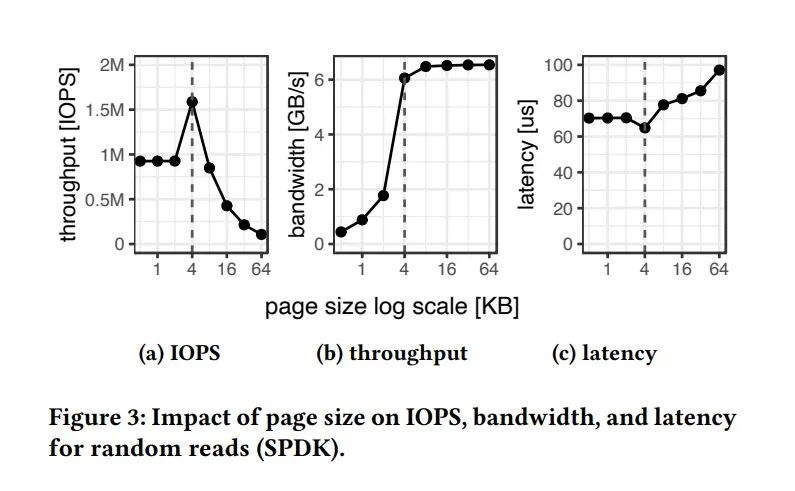
图:页面大小对随机读取性能的影响。4KB在IOPS、带宽和延迟上达到了最佳平衡点。
实验表明,4 KB页面在随机IOPS、吞吐量、延迟和I/O放大之间实现了最佳权衡。它是NVMe SSD随机读取性能的“甜点”。小于4KB会受到硬件限制,性能下降;大于4KB(如16KB)则会导致严重的I/O放大——读取一个100字节的记录却要搬动16KB的数据,产生160倍的放大效应,这对内存外工作负载是致命的。
四、总结与启示
这篇VLDB 2023论文为我们系统性地揭示了现代NVMe存储的性能潜力与挖掘方法。其核心结论可以概括为以下几点:
- 硬件不是瓶颈:通过合理配置(如使用8块企业级NVMe SSD),完全可以达到甚至超越千万级IOPS的硬件标称性能。
- 软件架构是关键:传统基于OS线程的同步I/O模型已无法适应新时代硬件。必须转向异步I/O(首选SPDK,次选io_uring)和用户态协作式多任务。
- 设计决策需权衡:4KB页面是数据库存储引擎的最佳选择;全对全的I/O模型能最大化简化设计并提升扩展性。
- 优化无处不在:要管理每秒数千万的IOPS,存储引擎的每一条内存外代码路径都必须进行深度优化,包括使用分区锁、无锁数据结构、优化淘汰算法等。
这项研究不仅对数据库系统的开发者具有直接的指导意义,对于任何需要处理超高并发、低延迟存储访问的后端架构设计,都提供了宝贵的原则和范例。技术的演进要求我们不断重新审视软件与硬件之间的交互方式,而这正是通过研读此类前沿论文能够获得的重要视角。
如果你想与更多开发者探讨存储、网络或系统架构等话题,欢迎访问云栈社区,那里有丰富的技术资源和活跃的交流氛围。
 发表于 2026-1-6 07:18:11
|
查看: 230|
回复: 0
发表于 2026-1-6 07:18:11
|
查看: 230|
回复: 0
