今天我们深入了解一下 Kafka 高性能的秘诀,以及应对高并发情况下有哪些值得借鉴的思路。
- 顺序IO
- 批量处理: 生产者,Broker,消费者分别如何利用批量处理
- 零拷贝:写入消息使用 mmap + write 方式,Broker 给消费端转发消息使用 sendfile 方式
顺序IO
特点
Kafka 的每个 Partition 本质是一个日志文件,消息写入时严格遵循 append only原则,即只能在文件末尾追加。
为什么顺序 IO 比随机 IO 快?
- 顺序IO:
- 数据在存储介质上连续排列,指针定位后只需 匀速前进 读取 / 写入。
- 预读(Read-Ahead):在顺序读取数据时,系统会提前把后续连续的数据加载到内存缓存中。
- 随机IO:
- 数据分散在存储介质的不同位置,指针需要频繁 跳转定位。
- 比如 HDD 的磁头寻道、SSD 的闪存块切换。
结论:
- 定位时间(寻道时间 / 切换时间)是 IO 延迟的主要来源。
- 顺序 IO 的定位时间几乎可以忽略,而随机 IO 的定位时间占比可能超过 90%。
- 比如 HDD 的寻道时间约 5-10ms,而单次数据读写仅需微秒级。
日常开发
- 日志系统(如 ELK)用顺序写日志文件,而非随机修改;
- 数据库(MySQL)优化索引、使用分区表,减少查询时的随机IO;
- Kafka/Redis 等中间件,底层存储设计优先采用顺序IO。
- Kafka 的分区日志是顺序写。
- Redis 的 AOF 日志是顺序追加。
IO优化总结
- IO 性能优化的核心,就是尽可能把随机IO 转化为顺序IO。
- 下次遇到 IO 优化场景,先想:
批量处理
Kafka 从生产端、 Broker 端、消费端全链路优化,通过 批量操作减少 IO 次数。
生产者
核心是先攒批、再发送,避免单条消息频繁发送导致的大量小 IO 请求。
配置
| 核心配置 |
作用 |
推荐值 |
| batch.size |
单个批次的最大字节数(默认 16KB)。生产者会把消息攒到该大小,再发送给 Broker,而非逐条发送。 |
16KB~64KB(根据业务延迟容忍度调整) |
| linger.ms |
生产者等待攒批的最大延迟(默认 0ms)。即使批次没到batch.size,到了该时间也会发送,平衡延迟和批量率。 |
5ms~10ms(非实时场景可设更大) |
| compression.type |
批量压缩(默认 none)。批量消息压缩效率远高于单条,减少网络传输量和 Broker 端的写入 IO 量。 |
lz4/snappy(性能 + 压缩比均衡) |
| acks |
确认机制(默认 1)。批量发送时,一次确认即可覆盖整批消息,减少 Broker 的确认交互次数。 |
1(高吞吐)/all(高可用) |
示例
Properties props = new Properties();
props.put(“bootstrap.servers”, “localhost:9092”);
props.put(“key.serializer”, “org.apache.kafka.common.serialization.StringSerializer”);
props.put(“value.serializer”, “org.apache.kafka.common.serialization.StringSerializer”);
// 批量核心配置
props.put(“batch.size”, 32768); // 批次大小设为32KB
props.put(“linger.ms”, 5); // 最多等5ms攒批
props.put(“compression.type”, “lz4”); // 开启lz4批量压缩
Broker端
核心是批量写入内存 + 批量刷盘,避免频繁小 IO 刷盘,最大化利用磁盘顺序 IO 的特性。
Kafka 数据可靠性优先靠副本机制,而非实时刷盘,所以 刷盘机制不建议调整为手动。
内存页缓存
- 内存页缓存(Page Cache)
- Broker 接收到生产者的批量消息后,先写入操作系统的页缓存(内存),而非直接刷盘。
- 这一步是 内存级批量,几乎无 IO 开销。
批量刷盘
- 操作系统会根据自身策略(如页缓存满 / 定时),把页缓存中的批量数据顺序写入磁盘日志文件,避免了单条消息刷盘的 随机小IO;
- Kafka 的分区日志是追加写,纯顺序IO。
批量读取
Broker 给消费端返回数据时,也是从页缓存 / 磁盘批量读取连续数据,减少磁盘寻道次数。
消费者
核心是按需批量拉取,避免频繁小请求触发 Broker 端的随机读取 IO。
配置
| 核心配置 |
作用 |
推荐值 |
| fetch.min.bytes |
拉取的最小字节数(默认 1B)。Broker 会等攒够该大小的数据,再返回给消费端,避免返回少量数据。 |
102400(100KB) |
| fetch.max.wait.ms |
等待拉取的最大延迟(默认 500ms)。即使没到fetch.min.bytes,到时间也返回,平衡延迟和批量率。 |
500ms~1000ms |
| max.poll.records |
单次 poll() 拉取的最大记录数(默认 500)。控制单次拉取的消息数量,避免拉取过多导致内存溢出。 |
500~2000 |
| enable.auto.commit |
自动提交 offset(默认 true)。批量提交 offset,减少 Broker 端的 offset 写入 IO 次数。 |
true(配合 auto.commit.interval.ms) |
| auto.commit.interval.ms |
自动提交 offset 的间隔(默认 5000ms)。批量提交,而非每条消息提交一次。 |
5000ms |
举例
假设你配置:
fetch.min.bytes=100KBfetch.max.wait.ms=500ms
Broker 的行为是:
- 消费端发起拉取请求后,Broker 先 收下请求但不返回,开始为这个请求攒数据;
- 若在 500ms 内,攒够了 100KB 的数据 , 立刻返回这 100KB 数据给消费端;
- 若 500ms 到了,只攒了 50KB 的数据 , 也会返回这 50KB 数据,避免消费端等太久。
那么,如果消费者上一次拉取请求还没返回,会不会就发起新请求?这就涉及到消费端拉取请求的触发频率。
触发频率
消费端的拉取请求完全由poll()方法的调用触发,没有 固定时间间隔,核心规则:
- 消费端每调用一次
poll(),就会向 Broker 发起一次拉取请求;
- 只有当本次
poll()完成(拿到 Broker 返回的数据 / 超时)并处理完消息后,才会发起下一次poll()。
所以:
- 拉取请求的频率 =
poll()循环的执行频率 = Broker 返回数据的时间 + 消费端处理消息的时间;
- 比如:Broker 攒数据用了 500ms,消费端处理消息用了 100ms ,那么拉取请求的频率就是约 600ms / 次;
- 如果消费端处理消息很慢(比如 10 秒),那么拉取请求的频率也会变成 10 秒 / 次,不会频繁发起。
那如何避免 “上一次请求未返回,又发新请求”这种情况呢?
- 默认情况下,消费端是单线程调用
poll(),且poll()是阻塞式的,同一时间只会有一个拉取请求发往 Broker。
类似以下代码:
while (true) {
// 调用poll() → 发起拉取请求,阻塞等待Broker响应(直到返回数据/本地超时)
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
// 只有当poll()返回后,才会执行这里的消息处理逻辑
processRecords(records); // 处理消息,耗时由业务逻辑决定
// 处理完消息后,才会进入下一次循环,发起新的拉取请求
}
如果业务需要提升消费速度,如何正确使用多线程?
正确的姿势是:
- 单线程调用
poll()拉取数据,然后将数据分发到多线程池中处理。
- 处理完成后再发起下一次
poll()。
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class MultiThreadConsumerExample {
// 固定线程池,处理消息
private staticfinal ExecutorService PROCESS_POOL = Executors.newFixedThreadPool(4);
public staticvoidmain(String[] args) {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, “localhost:9092”);
props.put(ConsumerConfig.GROUP_ID_CONFIG, “multi_thread_consumer”);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 核心攒数配置
props.put(ConsumerConfig.FETCH_MIN_BYTES_CONFIG, 102400);
props.put(ConsumerConfig.FETCH_MAX_WAIT_MS_CONFIG, 500);
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 1000);
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList(“test_topic”));
try {
while (true) {
// 1. 单线程poll() → 仅一个拉取请求在途
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
if (!records.isEmpty()) {
// 2. 分发到多线程处理,不阻塞poll()循环(但仍要等本次poll()返回)
PROCESS_POOL.submit(() -> processRecords(records));
}
// 3. 处理线程异步执行,poll()循环继续,但下一次poll()仍要等本次poll()完成
}
} finally {
consumer.close();
PROCESS_POOL.shutdown();
}
}
// 消息处理逻辑
private staticvoidprocessRecords(ConsumerRecords<String, String> records) {
records.forEach(record -> {
System.out.printf(“线程%s处理:offset=%d, value=%s%n”,
Thread.currentThread().getName(), record.offset(), record.value());
// 模拟业务处理耗时
try {
Thread.sleep(10);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
}
}
结论:
poll()方法必须由单线程调用,确保同一时间只有一个拉取请求;- 消息处理可以多线程,但拉取请求的发起必须单线程,从根源避免重复请求。
那使用@KafkaListener注解如何避免多线程poll?
主题有3个分区,设置spring.kafka.listener.concurrency=3:
- 框架会创建3 个独立的 KafkaConsumer 实例,每个实例都有自己的单线程 poll 循环;
- 每个实例只会处理分配给自己的分区数据,且每个实例同一时间只有一个拉取请求在途;
- 整体是 多实例并行消费,但单个实例内部依然是 处理完一批,再拉取下一批,不会出现重复请求。
concurrency=3 是不是跟使用pod起3个消费者的springboot实例一个效果?
两者最终的并行消费能力可能相同,但部署粒度、资源隔离、容错性、扩缩容方式完全不同。
| 对比维度 |
concurrency=3 |
3 个 Pod |
| 部署粒度 |
进程内线程级 / 实例级并发(单 JVM 进程内的 3 个 KafkaConsumer 实例) |
进程级跨节点并发(3 个独立 JVM 进程,可分布在不同节点) |
| 资源占用与隔离 |
共享 Pod 的 CPU / 内存(3 个实例抢同一个 Pod 的资源) |
独立占用 Pod 资源 |
| 故障影响范围 |
单个实例异常可能影响整个 Pod,故障影响面大 |
单个 Pod 故障仅影响该 Pod 内的 1 个消费实例,其他 2 个 Pod 正常工作,故障隔离性好 |
| 扩缩容成本 |
改配置即可,扩缩容粒度细、成本低 |
Pod 创建/销毁策略 |
| 网络 / 连接开销 |
单 Pod 内 3 个实例共享 Pod 网络,Kafka 连接数 = 3 |
3 个 Pod 各占 1 个网络,Kafka 连接数 = 3 |
| 适用场景 |
消费逻辑轻、资源占用低、追求资源利用率的场景 |
消费逻辑重、资源占用高、追求高可用 / 故障隔离的场景 |
把 Kafka 分区比作 3 个快递柜,消费实例比作快递员:
- concurrency=3:1 个快递站点(单 Pod)里安排 3 个快递员,共享站点的电动车、仓库资源,一起处理 3 个快递柜的快递;
- 3 个 Pod:3 个独立的快递站点(每个站点 1 个快递员),每个站点有自己的电动车、仓库,分别处理 1 个快递柜的快递。
零拷贝
零拷贝技术实现的方式通常有 2 种:
我们先从传统IO开始了解,再深入零拷贝技术。
传统的IO流程
流程
以read示例,CPU 全程参与数据拷贝,无任何硬件辅助,性能极低。
- 应用程序调用
read()系统调用,触发用户态 → 内核态切换;
- 内核向磁盘控制器发送 读数据 指令,磁盘将数据读到自身缓存;
- CPU 将磁盘缓存中的数据拷贝到内核页缓存(内核态内存);
- CPU 再将内核页缓存中的数据拷贝到应用程序的用户态内存;
read()调用返回,触发内核态 → 用户态切换。
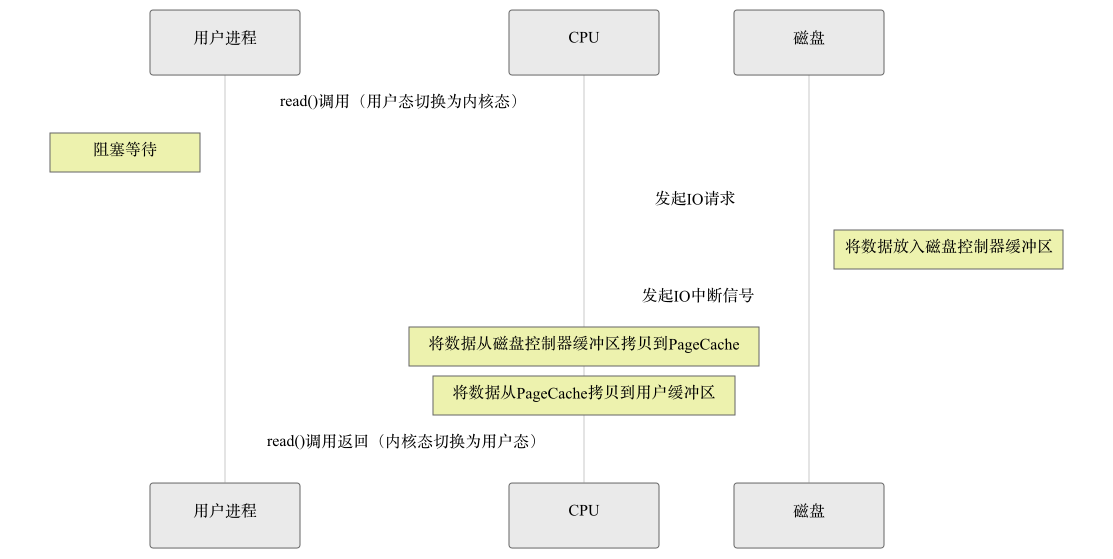
小结
- 拷贝次数:2 次 CPU 拷贝(无 DMA 参与);
- 态切换:2 次;
- CPU 占用:极高(全程参与拷贝);
- 适用场景:仅早期无 DMA 硬件的场景,现代系统已淘汰。
全程都需要CPU,而 CPU 的核心价值是执行计算、逻辑调度等核心任务,完全沦为 数据搬运工。于是就有了 DMA(直接内存访问)硬件来解放 CPU。
带DMA的IO流程
流程
- 应用程序调用read()系统调用,触发用户态 → 内核态切换;
- 内核向磁盘控制器发送 读数据 指令,同时告知 DMA 控制器目标内存地址(内核页缓存);
- DMA 控制器(无需 CPU 参与)将磁盘数据从磁盘缓存拷贝到内核页缓存;
- CPU 将内核页缓存中的数据拷贝到应用程序的用户态内存;
read()调用返回,触发内核态 → 用户态切换。
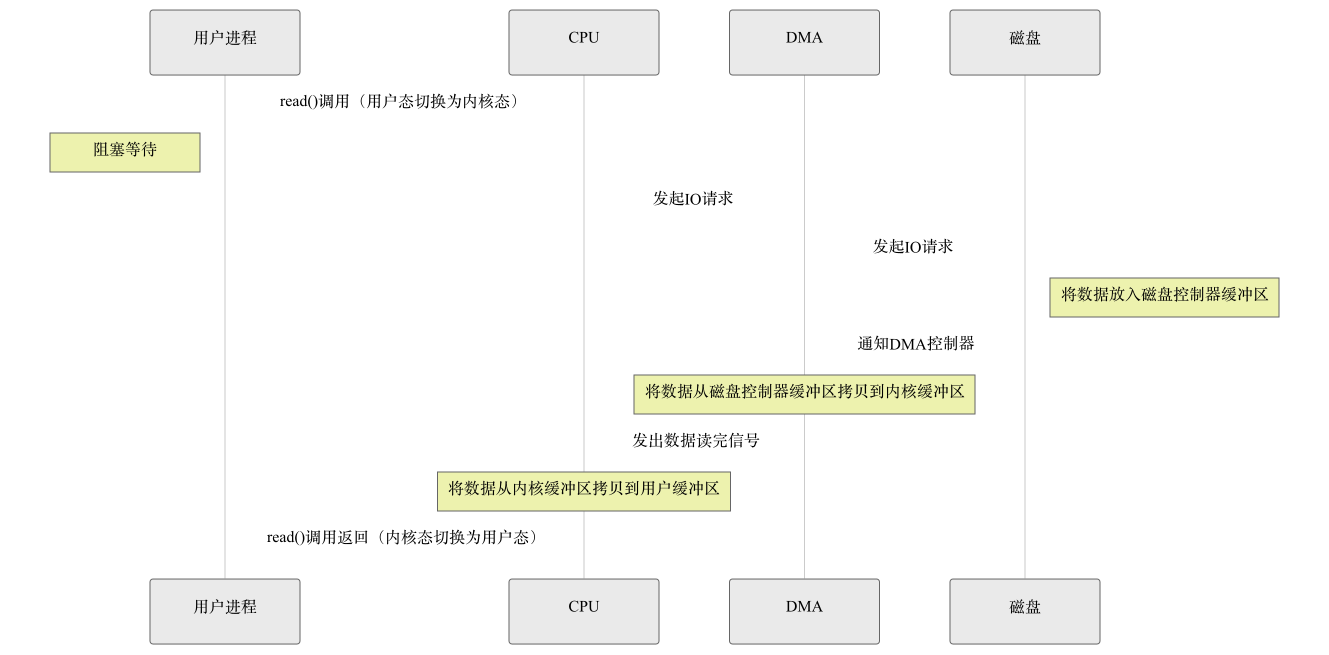
小结
- 拷贝次数:1 次 CPU 拷贝 + 1 次 DMA 拷贝(共 2 次);
- 态切换:2 次;
- CPU 占用:中等(仅参与内核→用户的拷贝);
- 适用场景:现代系统基础读取操作(如应用读取本地文件)。
在像 Kafka 这样的消息系统中,场景更加复杂。当消费者向 Broker 发出拉取消息的请求时,Broker 需要完成“读取磁盘数据并发送到网络”的操作。我们先来看最传统的读写文件流程是如何进行的。
传统读写文件
一般会需要两个系统调用:
read(file, tmp_buf, len);
write(socket, tmp_buf, len);
流程
- 应用调用
read(),触发用户→内核切换,DMA 将磁盘数据拷贝到内核页缓存。
- CPU 将内核页缓存数据拷贝到用户态内存,
read()返回,触发内核→用户切换。
- 应用调用
write(),触发用户→内核切换,CPU 将用户态内存数据拷贝到内核 socket 缓存。
- DMA 将 socket 缓存数据拷贝到网卡,
write()返回,触发内核→用户切换。
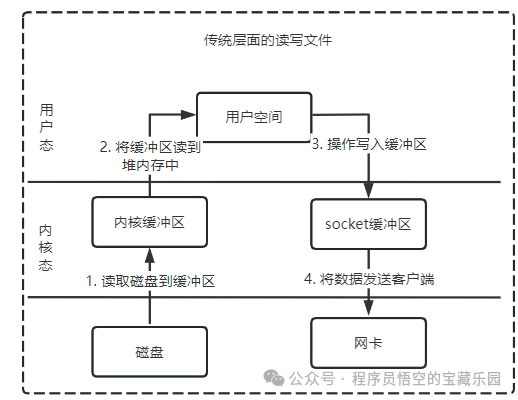
小结
- 拷贝次数:2 次 CPU 拷贝 + 2 次 DMA 拷贝(共 4 次);
- 态切换:4 次;
- CPU 占用:高(2 次 CPU 拷贝)。
如何提高性能呢?这就需要减少「用户态与内核态的上下文切换」和「内存拷贝」的次数,这正是零拷贝技术要解决的问题。
mmap + write
用 mmap() 替换 read() 系统调用函数,这正是 Kafka Broker 写入消息到磁盘时采用的方式。
buf = mmap(file, len);
write(sockfd, buf, len);
特点
- 将内核页缓存与用户态内存做 映射,跳过 内核→用户 的 CPU 拷贝。
- Kafka Broker 接收生产者消息时,用
mmap将消息写入映射内存(等价写入内核页缓存),后续 OS 批量刷盘,避免内核→用户的无用拷贝。
流程
- 应用调用
mmap(),触发用户→内核切换,内核将磁盘文件映射到内核页缓存,返回映射的用户态内存地址,mmap()返回,触发内核→用户切换。
- 应用向 映射的用户态内存 写入数据,等价于直接写入内核页缓存,无需 CPU 拷贝。
- 应用调用
write(),触发用户→内核切换,CPU 将内核页缓存数据拷贝到 socket 缓存。
- DMA 将 socket 缓存数据拷贝到网卡,
write()返回,触发内核→用户切换。
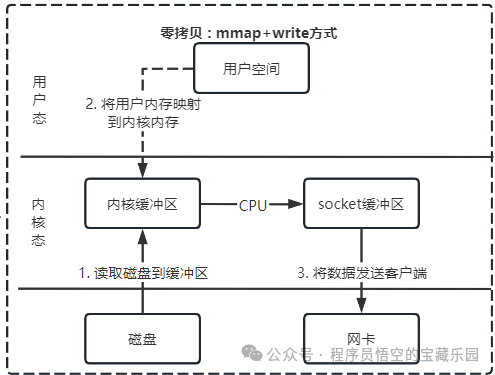
小结
- 拷贝次数:1 次 CPU 拷贝 + 2 次 DMA 拷贝(共 3 次);
- 态切换:4 次(
mmap+write各 2 次);
- CPU 占用:中等(减少 1 次 CPU 拷贝)。
sendfile
这个系统调用替代了前面的 read() 和 write() 这两个独立的系统调用,是 Kafka Broker 给消费端通过网络转发消息时采用的高效方式。
#include<sys/socket.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
特点
- Linux 内核提供的专门发送文件的系统调用函数
sendfile()。
- 减少一次系统调用,也就减少了 2 次上下文切换的开销。
流程
- 应用调用
sendfile(),触发用户→内核切换,DMA 将磁盘数据拷贝到内核页缓存。
- 内核将 数据的描述符 拷贝到 socket 缓存,仅元数据,无实际数据拷贝。
- DMA 控制器根据 socket 缓存中的描述符,直接从内核页缓存拷贝数据到网卡。
sendfile()返回,触发内核→用户切换。
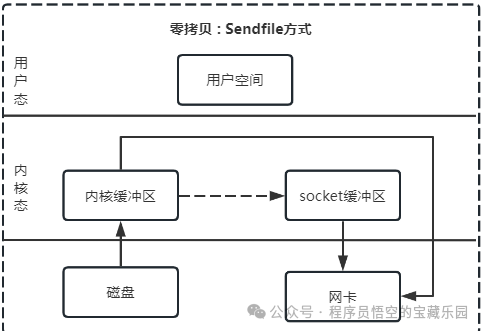
小结
- 拷贝次数:0 次 CPU 拷贝 + 2 次 DMA 拷贝(共 2 次);
- 态切换:2 次(仅
sendfile 调用的 1 次切换往返);
- CPU 占用:极低,仅处理指令,不参与数据拷贝。
总结
Kafka 的高性能不是单一优化的结果,而是多重技术叠加的成果:
- 顺序IO 从根本上解决了磁盘寻道慢的瓶颈。
- 全链路批量处理(生产、Broker、消费)大幅减少了频繁小IO请求的开销。
- 零拷贝技术(生产者写入用
mmap,消费转发用sendfile)最大限度地解放了 CPU 算力,使其专注于业务处理。
理解这些底层机制,不仅能帮助我们更好地使用和调优 Kafka,其设计思想(如顺序写、批处理、减少拷贝)对于设计其他高性能 Java 后端系统或处理高并发 网络 IO 场景也具有普遍的指导意义。如果你想深入探讨更多分布式系统的高性能设计,欢迎在云栈社区交流分享。
 发表于 2026-1-6 07:25:34
|
查看: 227|
回复: 0
发表于 2026-1-6 07:25:34
|
查看: 227|
回复: 0
