为什么单核CPU能“同时”运行多个程序?当你一边播放音乐、一边浏览网页时,背后其实是CPU上下文切换在毫秒级时间内完成的“无缝接力”。它保存当前任务的运行状态,唤醒下一个任务的执行环境,确保CPU资源永不闲置。然而,多数人对它的理解往往停留在“进程切换”的模糊概念,忽略了从硬件触发到内核执行的完整链路。
深入理解上下文切换,绝非记忆定义那么简单。从原理看,它是寄存器与内存数据的精准搬运;从内核视角,它涉及进程控制块(PCB)的读写与调度算法的决策。无论是用户态与内核态的切换损耗,还是中断上下文与进程上下文的执行差异,都隐藏着系统性能调优的关键线索。本文将打破“原理”与“实现”的割裂,从CPU硬件设计逻辑出发,顺着内核调度流程,拆解上下文切换的触发条件、执行步骤与性能成本,带你看清从指令触发到状态恢复的每一个细节,真正掌握这一操作系统底层的核心机制。
一、什么是 CPU 上下文
要理解CPU上下文切换,首先得弄清楚什么是CPU上下文。简单来说,CPU上下文就是CPU在执行任务时所需要的运行环境。这就像我们完成一项工作需要特定的工具和场地一样,CPU执行任务也离不开它的“工作台”。
CPU上下文主要由CPU寄存器和程序计数器等核心部件构成。先说说CPU寄存器,它是集成在CPU内部的高速存储单元,就像一个临时的小仓库,用来暂存指令、数据和地址信息。由于它直接位于CPU内部,无需通过总线访问,因此速度极快,远超内存访问,能让CPU高效地获取和处理数据。举个例子,当计算5+3时,CPU会先将5和3从内存加载到寄存器,在寄存器中完成加法得到结果8,最后再将结果存回内存。在这个过程中,寄存器就像手边的便签本,方便快速存取,大幅提升了工作效率。
程序计数器则是存储下一条待执行指令地址的部件,如同一个导航仪,始终指引CPU按正确顺序执行程序指令。每执行完一条指令,程序计数器会自动更新,指向下一条指令的地址。这就像我们照着菜谱做菜时,手指指着当前阅读的步骤,让我们清楚地知道接下来该做什么。
当CPU执行一个任务时,这些寄存器和程序计数器会被设置为特定的值,这些值的集合就构成了该任务的CPU上下文。可以说,CPU上下文是任务运行的基础环境,它完整记录了任务当前的运行状态和相关信息,确保任务能够正确、有序地执行。一旦CPU上下文被破坏或丢失,任务就无法继续,好比工作中突然丢失了所有工具和资料,工作自然被迫中断。
二、CPU 上下文切换原理
理解了CPU上下文,接下来我们剖析CPU上下文切换的具体原理。整个过程可以清晰地分为几个核心步骤。
2.1 保存当前上下文
当操作系统决定进行上下文切换时,第一步就是保存当前正在执行任务的上下文。这就像我们做一件事到一半,需要临时处理另一件事时,会先记录下当前的进度和工具状态。
操作系统会将当前任务的CPU寄存器值、程序计数器值以及其他相关状态信息保存到内存中。具体来说,这些信息被存储在任务对应的进程控制块(PCB)或线程控制块(TCB)中。例如,正在执行任务A时,寄存器中存有任务A的临时数据,程序计数器指向任务A的下一条指令,这些信息都会被完整地保存到任务A的PCB里。这样,当任务A后续被重新调度时,就能从这些保存的信息中完全恢复到之前的运行状态,实现无缝衔接。这个过程涉及到操作系统对进程和线程的管理,是调度器工作的基础。
下面通过一段简化的C++代码模拟这一核心过程:
#include <iostream>
#include <string>
#include <vector>
#include <cstdint>
// 模拟CPU寄存器(简化版,仅保留核心寄存器)
struct CPUContext {
uint64_t rax; // 通用寄存器
uint64_t rbx; // 通用寄存器
uint64_t pc; // 程序计数器(指向下一条要执行的指令地址)
uint64_t rsp; // 栈指针寄存器
};
// 进程控制块(PCB):存储进程/任务的上下文和状态
struct PCB {
int pid; // 进程ID
std::string name; // 进程名称
CPUContext context; // 该进程的CPU上下文
bool is_running; // 是否正在运行
PCB(int id, const std::string& n)
: pid(id), name(n), is_running(false) {
// 初始化上下文(寄存器初始值为0)
context.rax = 0;
context.rbx = 0;
context.pc = 0;
context.rsp = 0;
}
};
// 模拟操作系统调度器:管理进程、执行上下文切换
class Scheduler {
private:
std::vector<PCB> processes; // 系统中所有进程
PCB* current_running = nullptr; // 当前正在执行的进程
public:
// 添加进程到调度器
void add_process(const PCB& proc){
processes.push_back(proc);
std::cout << "添加进程:PID=" << proc.pid << ",名称=" << proc.name << std::endl;
}
// 保存当前进程的上下文到PCB
void save_context(){
if (!current_running) {
std::cout << "无正在运行的进程,无需保存上下文" << std::endl;
return;
}
// 模拟:从CPU中读取当前寄存器值,保存到当前进程的PCB
// 实际操作系统中,这一步由硬件/内核中断处理程序完成
std::cout << "\n===== 保存进程[" << current_running->pid << ":" << current_running->name << "]的上下文 =====" << std::endl;
// 模拟寄存器的实时值(任务执行过程中寄存器会变化)
current_running->context.rax = 0x12345678; // 任务执行中产生的临时数据
current_running->context.rbx = 0x87654321;
current_running->context.pc = 0x00401000; // 下一条要执行的指令地址
current_running->context.rsp = 0x7ffeef00; // 当前栈指针位置
// 打印保存的上下文信息
std::cout << "保存的寄存器状态:" << std::endl;
std::cout << " rax = 0x" << std::hex << current_running->context.rax << std::endl;
std::cout << " rbx = 0x" << std::hex << current_running->context.rbx << std::endl;
std::cout << " pc = 0x" << std::hex << current_running->context.pc << "(下一条指令地址)" << std::endl;
std::cout << " rsp = 0x" << std::hex << current_running->context.rsp << "(栈指针)" << std::dec;
current_running->is_running = false; // 标记进程为暂停状态
}
// 恢复目标进程的上下文到CPU
void restore_context(int target_pid){
// 查找目标进程
PCB* target_proc = nullptr;
for (auto& proc : processes) {
if (proc.pid == target_pid) {
target_proc = &proc;
break;
}
}
if (!target_proc) {
std::cerr << "进程PID=" << target_pid << "不存在!" << std::endl;
return;
}
std::cout << "\n===== 恢复进程[" << target_proc->pid << ":" << target_proc->name << "]的上下文 =====" << std::endl;
// 模拟:将PCB中保存的上下文加载到CPU寄存器
std::cout << "从PCB恢复寄存器状态:" << std::endl;
std::cout << " rax = 0x" << std::hex << target_proc->context.rax << std::endl;
std::cout << " rbx = 0x" << std::hex << target_proc->context.rbx << std::endl;
std::cout << " pc = 0x" << std::hex << target_proc->context.pc << "(CPU将从该地址继续执行)" << std::endl;
std::cout << " rsp = 0x" << std::hex << target_proc->context.rsp << std::dec;
current_running = target_proc;
current_running->is_running = true; // 标记进程为运行状态
std::cout << "\n进程[" << target_proc->pid << ":" << target_proc->name << "]已恢复执行" << std::endl;
}
// 执行上下文切换:从当前进程切换到目标进程
void context_switch(int target_pid){
std::cout << "\n=====================================" << std::endl;
std::cout << "开始执行上下文切换" << std::endl;
std::cout << "=====================================" << std::endl;
// 第一步:保存当前进程的上下文
save_context();
// 第二步:恢复目标进程的上下文
restore_context(target_pid);
std::cout << "\n上下文切换完成!" << std::endl;
}
};
int main(){
// 1. 初始化调度器
Scheduler os_scheduler;
// 2. 添加两个测试进程
os_scheduler.add_process(PCB(1, "任务A(视频播放)"));
os_scheduler.add_process(PCB(2, "任务B(文件下载)"));
// 3. 模拟:先执行任务A,再切换到任务B
std::cout << "\n===== 初始执行任务A =====" << std::endl;
os_scheduler.restore_context(1); // 先让任务A运行
// 4. 触发上下文切换:从任务A切换到任务B
os_scheduler.context_switch(2);
return 0;
}
这段代码清晰地展示了三个关键步骤:
- 保存当前上下文(save_context):模拟从CPU读取寄存器实时值,写入当前运行进程的PCB,对应操作系统“暂停当前任务,记录执行状态”的过程。
- 恢复目标上下文(restore_context):从目标进程的PCB读取保存的寄存器值,加载到CPU,对应“恢复任务执行状态,继续执行”的过程。
- 上下文切换(context_switch):组合“保存+恢复”两步,完成从当前任务到目标任务的完整切换,还原了操作系统上下文切换的核心逻辑。
2.2 调度器选择任务
保存了当前任务的上下文后,操作系统的调度器便开始工作。调度器如同一个任务分配管家,它会根据预设的调度算法,从就绪队列中选择下一个要执行的候选任务。就绪队列里存放着所有已准备好运行、只等待CPU资源的任务。
常见的调度算法各具特点:
- 先来先服务(FCFS):像严格按顺序排队,根据任务进入队列的先后分配CPU。优点是简单,但缺点明显:若队首是一个长任务,后面的短任务将被迫长时间等待,导致短任务响应时间过长。
- 时间片轮转(RR):将CPU时间划分为固定长度的时间片(如20毫秒)。每个任务轮流执行一个时间片,时间到即被暂停并放回就绪队列末尾,等待下一轮调度。这种方式保证了公平性,防止单个任务独占CPU。但时间片设置是关键:太短会导致上下文切换过于频繁,增加系统开销;太长则会退化为FCFS,失去其优势。
- 其他算法:如优先级调度、短作业优先、多级反馈队列等,操作系统会根据具体需求和场景选择,以优化整体性能和资源利用率。理解这些调度策略是掌握操作系统核心原理的重要部分。
2.3 加载新上下文
调度器选定下一个任务后,便是加载其上下文。这好比开始新工作前,准备好相应的工具和资料。操作系统会从内存中读取新任务PCB/TCB里保存的CPU寄存器值、程序计数器值等状态信息,并将其加载到CPU的实际寄存器中。
至此,CPU的“工作环境”已完全切换到新任务的状态,知道了从哪里开始执行指令(程序计数器),以及当前可用的临时数据在哪里(寄存器)。下面的代码模拟了这一加载过程:
#include <iostream>
#include <string>
#include <vector>
#include <cstdint>
#include <iomanip>
// CPU核心寄存器(简化版,覆盖上下文核心要素)
struct CPURegisters {
uint64_t rax; // 通用寄存器:存储临时计算数据
uint64_t rbx; // 通用寄存器:存储临时计算数据
uint64_t pc; // 程序计数器:指向要执行的下一条指令地址
uint64_t rsp; // 栈指针寄存器:指向当前栈顶位置
};
// 进程控制块(PCB):存储任务的上下文和基本信息
struct PCB {
int pid; // 任务/进程ID
std::string task_name; // 任务名称
CPURegisters saved_context; // 保存的任务上下文(暂停时的寄存器状态)
bool is_ready; // 任务是否就绪(可被调度)
// 构造函数:初始化任务基本信息和上下文
PCB(int id, const std::string& name)
: pid(id), task_name(name), is_ready(true) {
// 为不同任务初始化差异化的上下文(任务自有运行环境)
if (name.find("视频播放") != std::string::npos) {
saved_context.rax = 0x11223344; // 视频解码临时数据
saved_context.rbx = 0x55667788;
saved_context.pc = 0x00401200; // 视频播放指令起始地址
saved_context.rsp = 0x7ffeef50; // 视频任务栈指针
} else if (name.find("文件下载") != std::string::npos) {
saved_context.rax = 0xaabbccdd; // 网络数据缓存地址
saved_context.rbx = 0xeeff0011;
saved_context.pc = 0x00402400; // 下载任务指令起始地址
saved_context.rsp = 0x7ffeef80; // 下载任务栈指针
}
}
};
// CPU:仅包含当前寄存器状态(物理CPU的硬件状态)
struct CPU {
CPURegisters regs; // CPU当前寄存器值
// 打印当前CPU寄存器状态
void print_current_state(const std::string& tip){
std::cout << "\n【CPU当前状态】" << tip << std::endl;
std::cout << "----------------------------------------" << std::endl;
std::cout << "rax: 0x" << std::hex << std::setw(8) << std::setfill('0') << regs.rax << std::endl;
std::cout << "rbx: 0x" << std::hex << std::setw(8) << std::setfill('0') << regs.rbx << std::endl;
std::cout << "pc : 0x" << std::hex << std::setw(8) << std::setfill('0') << regs.pc << " (下一条指令地址)" << std::endl;
std::cout << "rsp: 0x" << std::hex << std::setw(8) << std::setfill('0') << regs.rsp << " (栈指针位置)" << std::dec;
std::cout << "\n----------------------------------------" << std::endl;
}
};
// 操作系统调度器:负责选择任务、加载上下文
class Scheduler {
private:
std::vector<PCB> task_list; // 系统就绪任务列表
CPU& cpu; // 关联物理CPU(引用)
public:
// 构造函数:绑定CPU
Scheduler(CPU& cpu_hw) : cpu(cpu_hw) {}
// 添加任务到就绪列表
void add_task(const PCB& task){
task_list.push_back(task);
std::cout << "调度器:添加任务 [" << task.pid << "] " << task.task_name << std::endl;
}
// 选择下一个要执行的任务(按PID选择)
PCB* select_next_task(int target_pid){
for (auto& task : task_list) {
if (task.pid == target_pid && task.is_ready) {
std::cout << "\n调度器:选定下一个执行任务 [" << task.pid << "] " << task.task_name << std::endl;
return &task;
}
}
std::cerr << "调度器:任务 [" << target_pid << "] 不存在或未就绪!" << std::endl;
return nullptr;
}
// 加载新任务的上下文到CPU(核心逻辑)
void load_task_context(PCB* new_task){
if (!new_task) return;
std::cout << "\n=====================================" << std::endl;
std::cout << "开始加载新任务上下文到CPU" << std::endl;
std::cout << "=====================================" << std::endl;
// 步骤1:从新任务的PCB中读取保存的上下文
std::cout << "1. 从内存中读取任务 [" << new_task->pid << "] 的上下文(PCB中):" << std::endl;
std::cout << " rax: 0x" << std::hex << new_task->saved_context.rax << std::endl;
std::cout << " rbx: 0x" << std::hex << new_task->saved_context.rbx << std::endl;
std::cout << " pc : 0x" << std::hex << new_task->saved_context.pc << std::endl;
std::cout << " rsp: 0x" << std::hex << new_task->saved_context.rsp << std::dec << std::endl;
// 步骤2:将上下文加载到CPU寄存器(核心操作)
std::cout << "2. 将上下文加载到CPU寄存器..." << std::endl;
cpu.regs.rax = new_task->saved_context.rax;
cpu.regs.rbx = new_task->saved_context.rbx;
cpu.regs.pc = new_task->saved_context.pc;
cpu.regs.rsp = new_task->saved_context.rsp;
// 步骤3:打印加载后的CPU状态
cpu.print_current_state("加载任务 [" + std::to_string(new_task->pid) + "] 上下文后");
std::cout << "任务 [" << new_task->pid << "] 上下文加载完成!CPU可开始执行该任务" << std::endl;
}
// 调度流程:选任务 → 加载上下文
void schedule_task(int target_pid){
PCB* next_task = select_next_task(target_pid); // 选任务
load_task_context(next_task); // 加载上下文
}
};
int main(){
// 1. 初始化物理CPU(初始状态寄存器全0)
CPU physical_cpu;
physical_cpu.print_current_state("初始状态(无任务执行)");
// 2. 初始化调度器并绑定CPU
Scheduler os_scheduler(physical_cpu);
// 3. 添加两个测试任务
os_scheduler.add_task(PCB(1, "视频播放任务"));
os_scheduler.add_task(PCB(2, "文件下载任务"));
// 4. 调度器选择并加载“文件下载任务”的上下文
os_scheduler.schedule_task(2);
return 0;
}
代码执行流程:
- 初始化:CPU寄存器初始为全0,调度器添加了具有不同上下文(不同rax、pc等值)的两个任务。
- 选择任务:调度器选定“文件下载任务”为下一个执行者。
- 加载上下文:系统从内存中读取该任务PCB保存的寄存器值,并逐一写入CPU的物理寄存器。至此,CPU的硬件状态完全更新为新任务所需的环境,可以立即开始执行其指令。
2.4 执行新任务
新任务的上下文加载完毕后,CPU便根据程序计数器指向的地址,开始读取并执行新任务的指令。执行过程中会利用寄存器中的数据完成各种运算和操作。
在理想情况下,如果没有时间片耗尽、高优先级任务到达或I/O阻塞等事件,任务会一直执行直到完成。但在真实的并发环境中,任务执行过程中再次触发上下文切换是常态。例如,时间片用完会触发新一轮调度;高优先级任务就绪可能导致当前任务被立即抢占。这就像我们处理工作时,突然有更紧急的任务插队,需要先保存当前进度去处理紧急事务,之后再回来继续。
三、CPU 上下文切换类型
操作系统中的CPU上下文切换主要分为三种类型:进程上下文切换、线程上下文切换和中断上下文切换,它们各自具有不同的特点和应用场景。
3.1 进程上下文切换
在Linux等现代操作系统中,进程的运行空间被严格划分为内核空间和用户空间,这是系统稳定与安全的基石。
- 内核空间:如同操作系统的“心脏地带”,拥有最高特权级(Ring 0),可以执行任意指令并访问所有硬件和内存资源。它承载着内核代码和关键数据结构。
- 用户空间:是用户程序运行的“舞台”,特权级较低(Ring 3)。程序在此只能执行受限指令,访问硬件资源需通过系统调用向内核请求。
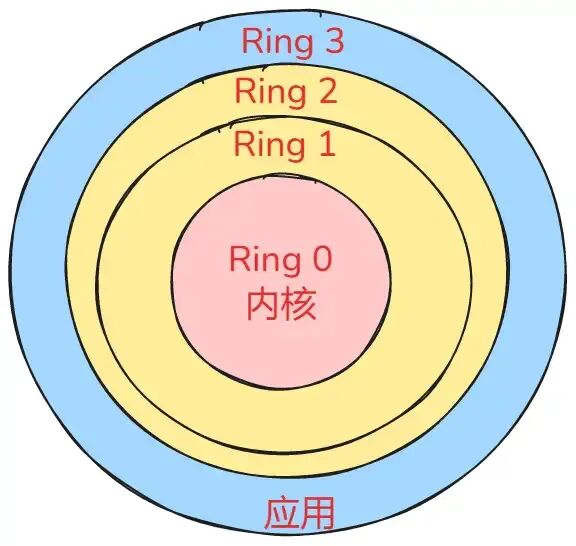
进程在这两个空间运行对应两种状态:
- 用户态:进程在用户空间运行,执行非特权指令。
- 内核态:进程通过系统调用(如
open()、read())陷入内核空间运行,可执行特权指令。
一次系统调用过程会发生两次CPU上下文切换(用户态->内核态->用户态),但注意,这不是进程切换,因为始终是同一个进程在执行,不涉及虚拟内存等完整进程资源的切换。
真正的进程上下文切换会在以下情况发生:
- 时间片耗尽:为保证公平调度,时间片用尽的进程会被挂起,调度其他就绪进程。
- 系统资源不足:如内存不足时,进程可能被换出(swap out),系统调度其他进程。
- 进程主动挂起:进程调用
sleep() 等函数主动让出CPU。
- 更高优先级进程就绪:为保证实时性,高优先级进程可抢占低优先级进程。
- 硬件中断:中断处理完毕后,可能不会恢复原进程,而是调度新进程。
3.2 线程上下文切换
线程与进程在调度和资源分配上截然不同:
- 进程是资源分配的基本单位,拥有独立的内存空间、文件句柄等,像一个独立的“小王国”。
- 线程是CPU调度的基本单位,是进程内的执行流。多个线程共享进程的内存空间(堆、全局变量)和资源,因此线程创建、销毁和切换的开销远小于进程。
同进程内线程切换特点显著:由于共享虚拟内存和全局变量等资源,切换时这些共享资源无需改动。主要开销在于保存和恢复线程的私有数据,如线程独立的栈(存局部变量、函数调用信息)和寄存器状态。
不同进程间线程切换则复杂得多:因为线程所属的进程不同,资源不共享。其切换过程类似于进程上下文切换,除了要保存/恢复线程私有数据,还需切换进程的虚拟内存、全局变量等资源,开销更大。
3.3 中断上下文切换
中断是硬件设备与CPU交互的关键机制。当硬件(如硬盘、网卡)完成操作或发生事件时,会向CPU发送中断信号。CPU收到信号后,立即暂停当前进程,转去执行对应的中断处理程序(ISR)。处理完毕后,再恢复被中断进程的执行。
中断上下文包含了内核态中断服务程序执行所必需的状态,主要包括:
- CPU寄存器值(中断发生时的现场)
- 内核堆栈(用于ISR执行)
- 硬件中断参数(中断来源、类型等)
与进程上下文不同,中断上下文切换不涉及进程的用户态资源(如虚拟内存)。它只保存/恢复内核态相关信息,以实现快速响应,因此开销较小。
中断上下文切换 vs. 进程上下文切换核心区别:
- 优先级:中断切换优先级最高,无条件打断当前进程。
- 目的:中断切换旨在快速响应硬件事件;进程切换旨在实现多任务并发。
- 开销:中断切换开销小(仅内核态);进程切换开销大(涉及用户态和内核态完整资源)。
- 触发者:中断切换由硬件触发;进程切换由操作系统调度器触发。
四、上下文切换开销与优化
4.1 开销来源
上下文切换虽必要,但会引入性能开销,主要来源如下:
- 保存/恢复上下文的时间开销:需要将寄存器等状态写入内存(PCB)再读出,内存访问速度远慢于CPU寄存器,频繁切换会占用大量有效计算时间。
- 调度器决策开销:调度器根据算法(如优先级排序、时间片计算)选择下一个任务,算法越复杂、任务越多,决策耗时越长。
- 缓存与TLB失效:任务切换后,新任务的数据可能不在当前CPU缓存中,导致缓存缺失(Cache Miss),需从内存重新加载,增加延迟。若涉及地址空间切换,还会导致TLB(页表缓存)失效,拖慢地址转换速度。
4.2 优化策略
为降低开销,可采取以下策略:
- 硬件优化:
- 利用高速缓存(Cache):通过优化数据局部性,提高缓存命中率,减少因切换导致的缓存失效。
- 增加CPU核心:多核CPU可真正并行执行多个任务,减少核心内上下文切换的频率。
- 调度算法优化:
- 对I/O密集型任务多的系统,可采用优先队列调度,让I/O任务优先执行,避免CPU空等。
- 对计算密集型任务多的系统,可采用短作业优先(SJF)调度,让短任务尽快完成,减少平均等待时间和切换次数。
- 上下文信息处理优化:
- 减少不必要的上下文保存/恢复量。例如,同进程内线程切换时,共享的进程资源(内存空间)无需处理。
- 使用共享内存等高效通信方式,减少因数据传递引发的进程/线程切换。
- 使用轻量级线程/协程:
- 协程是用户态的轻量级线程,其切换完全在用户态进行,无需陷入内核,开销极小。
- 例如,在Python中使用
asyncio 库,可在单线程内通过协程处理上万个并发网络连接,极大减少传统多线程/多进程带来的上下文切换负担。
五、实际应用与案例分析
5.1 多任务处理
我们日常在电脑上同时运行浏览器、音乐播放器、文档编辑器,正是CPU上下文切换创造的“并发”错觉。它确保CPU在某个任务等待I/O时能立刻切换到其他任务,充分利用资源,并保障了多任务之间的公平性与系统流畅性。
5.2 实时系统
在工业控制、自动驾驶等实时系统中,上下文切换的性能和准确性至关重要。例如,生产线传感器检测到温度异常,必须立即触发中断,CPU快速进行中断上下文切换,执行处理程序来调整设备。若切换过慢,可能导致无法及时响应,引发事故。因此,实时操作系统(RTOS)会采用专用调度算法,确保最坏情况下的切换延迟可控。
5.3 并发编程
在高并发服务器中(如Web服务器),多线程是主流模型。当一个线程因网络I/O而阻塞时,通过上下文切换让CPU去服务其他就绪线程,可以极大提升并发处理能力。但这也引入了线程安全挑战,必须使用锁、信号量等同步机制来保护共享资源,防止数据竞争和死锁。
5.4 性能监控案例分析
在实际运维中,我们可以使用工具监控上下文切换,以诊断性能问题。
1. 使用 vmstat 查看系统整体情况
# 每隔5秒输出一组数据
$ vmstat 5

在输出中,需重点关注以下四列:
- r (Running or Runnable):就绪队列长度,即正在运行和等待CPU的进程总数。若持续大于CPU核心数,说明进程在竞争CPU。
- b (Blocked):处于不可中断睡眠状态(通常等待I/O)的进程数。
- in (interrupt):每秒中断次数。
- cs (context switch):每秒上下文切换次数。如果cs值过高,说明系统可能正在频繁切换,消耗大量CPU时间在调度上,而非有效工作。
2. 使用 pidstat 定位具体进程
vmstat 看整体,pidstat 则可细查到每个进程/线程的切换情况。
# -w输出上下文切换信息,-t包含线程信息,每5秒输出一次
$ pidstat -tw 5
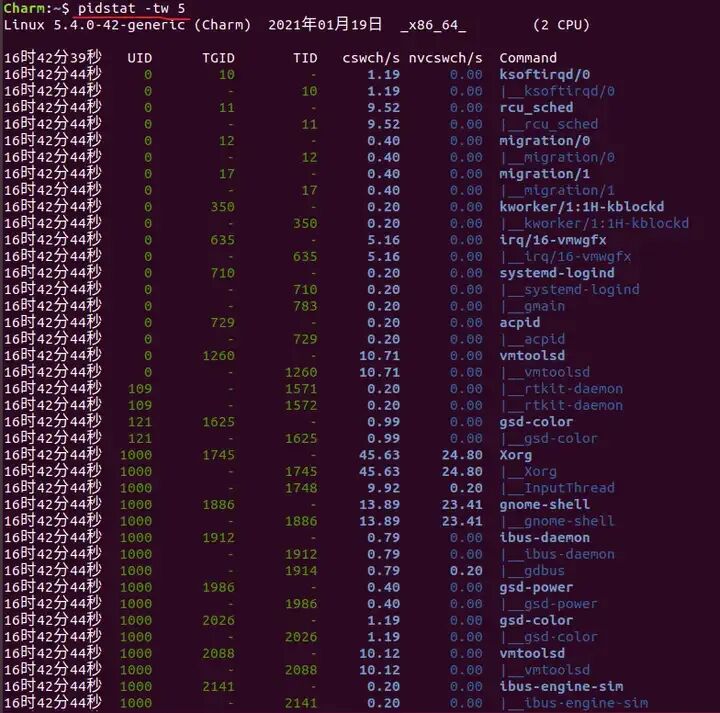
关键指标:
- cswch/s (voluntary context switches):每秒自愿上下文切换次数。通常是进程因等待资源(如I/O、内存)而主动让出CPU。
- nvcswch/s (non voluntary context switches):每秒非自愿上下文切换次数。通常是进程时间片用完或被更高优先级进程强制抢占。
分析思路:
- 若某个进程的
nvcswch/s 很高,说明它经常被系统强制切换,可能因为它单次执行时间过长(计算密集型),或者系统中存在大量竞争CPU的进程。
- 若
cswch/s 很高,可能意味着该进程在频繁等待资源(如大量磁盘I/O或锁竞争)。
- 结合
vmstat 的 cs 和 pidstat 的具体进程数据,可以精准定位导致频繁切换的“元凶”,进而采取优化措施,如调整进程优先级、优化I/O、减少不必要的线程数等。
总结
CPU上下文切换是操作系统实现多任务并发的基石,它精妙地在“保存现场”与“恢复现场”之间完成任务的接力。理解其原理(寄存器/PCB操作)、类型(进程/线程/中断)及开销,对于进行系统级性能调优、高并发编程和解决线上故障至关重要。通过 vmstat、pidstat 等工具进行监控和分析,能将理论应用于实践,真正掌控系统的运行脉络。希望本文的剖析能帮助你深入理解这一核心机制。更多关于系统底层和性能优化的深度讨论,欢迎在云栈社区交流探讨。
 发表于 2026-1-10 02:00:38
|
查看: 183|
回复: 0
发表于 2026-1-10 02:00:38
|
查看: 183|
回复: 0
