在当前 AI 系统软件栈中,Triton 并不是“又一个 CUDA ”,而是一个面向高性能算子开发的中间层工具。它通过 Python DSL 描述算子级计算与访存逻辑,并在底层借助完整编译体系,将高层算法自动映射为接近手写 CUDA / HIP 质量的设备代码,在开发效率与性能可控性之间取得平衡。
Triton 的核心设计在于解耦算法描述与硬件实现策略:开发者关注“算什么、怎么访存”,而线程绑定、并行度展开、内存布局与指令选择等细节,由编译器与运行时系统协同完成。同时,通过 BLOCK_SIZE、num_warps、num_stages 等参数,Triton 又允许开发者显式参与性能建模与调优。这种“半抽象、半显式”的设计,使其在 GEMM、Softmax 等核心算子中被广泛采用。但正因如此,Triton 的性能不再简单归因于 kernel 的算法实现,而是由算法表达、编译优化、自动调优与运行时调度等多个阶段共同塑造的结果。工程实践中常见的性能波动或跨硬件差异,其根源往往隐藏在这一完整的编译与执行路径之中。
因此,本文将系统性拆解 Triton Kernel 从 Python 代码到设备执行的全生命周期,重点分析其编译流程以及 launch 阶段 program 到硬件线程的映射机制,帮助开发者从“能写能跑”,走向对性能与计算成本的真正可控。
Triton Kernel 的整体执行视角
对多数用户而言,Triton kernel 的使用体验往往被简化为三行代码:定义 kernel、指定 grid、传入参数。但在这三行代码背后,Triton 实际上完成了一整套跨语言、跨 IR、跨编译期与运行期的协同工作。
@triton.jit
def my_kernel(...):
...
my_kernel[grid](x_ptr, y_ptr, n)
从宏观视角看,一次 Triton kernel 的执行可以被拆分为如下阶段:
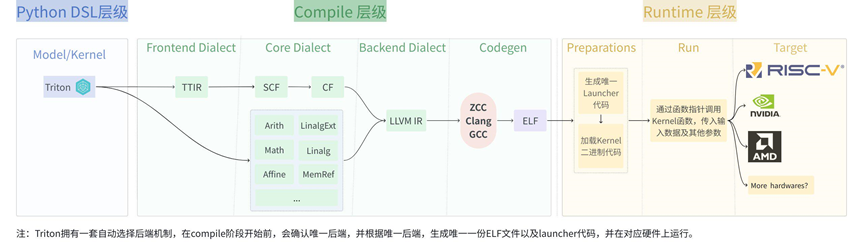
1.Python DSL 层级
负责描述 Kernel 算子要算什么、以怎样的并行结构去算,包括算子级计算逻辑、显式的并行维度(program / block)。在这一层中并不执行 kernel,而是将其算子级计算逻辑与并行意图从 Python 动态语义中抽离出来,捕获并固定为一个结构化的中间表示。
2.Compile 层级
负责回答这些高层算子语义如何在具体硬件模型中成立。Triton 通过多阶段 IR 与 pass pipeline,将 program、mask、tensor 等抽象概念的中间表示(TTIR),逐步转换为目标架构可执行的代码形式。
3.Runtime 层级
负责让已经编译好的 kernel 算子真正跑起来:包括参数封装、并行实例的展开、program 到硬件线程或 core 的映射,以及实际的 launch 与调度。
这种分层设计让同一 kernel 逻辑可以在不同设备和 grid 配置下复用,但也意味着性能不再只由 kernel 代码本身决定,而取决于高层算子语义在编译和运行过程中如何被具体化:并行与内存访问在哪些阶段被逐层确定以及最终的 launch 方式是否与底层硬件的执行模型相匹配。理解这一整体执行视角,是深入 Triton 编译流程与 runtime 机制的前提。
基于上述分层架构,下文将围绕这三个层级展开阐述,以揭示从高层算子语义到底层硬件执行模型的完整映射过程。
Python DSL 层级
Python DSL 是 Triton kernel 的入口,其核心设计在于:在这一层级,kernel 并不被立即执行。为实现这一点,Triton 引入了 @triton.jit 机制。当开发者在 Python 中定义函数并添加该装饰器时,Triton 会捕获函数的 Python AST 或 bytecode,将其封装为一个 JITFunction 对象。该对象仅描述“如何生成 kernel”,实际的编译与执行将在函数调用时才被触发,从而实现延迟运行与跨硬件复用。
基于这一机制,本章将聚焦 Python DSL 层,系统分析 JITFunction 的生成及运行过程。
1. 函数定义时使用@triton.jit
@triton.jit
def kernel(x, y):
# kernel code
pass
当 Python 执行这段代码时:@triton.jit 装饰器被调用, kernel 函数对象会作为参数传入 jit() 函数
# Invoke the decorator and reassign the value
kernel = triton.jit(kernel)
jit 代码如下,返回一个 JITFunction 实例,替换原来的 kernel 函数对象,变量名 kernel 现在指向 JITFunction 实例,这正是 Python 装饰器的本质:以函数为输入,返回一个语义被重新定义的新对象。在 Triton 中,这个新对象就是 JITFunction。
@triton.jit -> Union[JITFunction[T], Callable[[T], JITFunction[T]]]:
def decorator(fn: T) -> JITFunction[T]:
assert callable(fn)
if os.getenv("TRITON_INTERPRET", "0") == "1":
...
else:
return JITFunction(
fn,
version=version,
do_not_specialize=do_not_specialize,
do_not_specialize_on_alignment=do_not_specialize_on_alignment,
debug=debug,
noinline=noinline,
repr=repr,
launch_metadata=launch_metadata,
)
if fn is not None:
return decorator(fn)
...
2. JITFunction 的初始化
JITFunction 实例在被创建时,会调用 JITFunction._init_ 函数,这一初始化过程并不涉及任何真实的代码生成或设备执行,但它完成了后续所有编译与运行阶段所依赖的元信息收集、参数建模与提取 kernel 的 Python 源码等流程。
- 函数语义与参数结构的建模
self.fn = fn
self.signature = inspect.signature(fn)
- 提取 kernel 的 Python 源码
src = textwrap.dedent(inspect.getsource(fn))
src = src[re.search(r"^def\s+\w+\s*\(", src, re.MULTILINE).start():]
此处只展示_init_函数部分初始化代码,详细源码,读者可自行阅读源码。
初始化完毕后,原始的 kernel 变量指向 JITFunction 实例。
3. JITFunction 的运行(kernel 真正进入编译和运行阶段)
到目前为止,我们仍然停留在 Python DSL 层,@triton.jit 的作用是将一个普通 Python 函数转化为可被实例化的 kernel 描述体(JITFunction)。此时,函数仍然只是一种算法意图的抽象表示,算子语义(如 tl.load、program_id 或 BLOCK_SIZE)在这个阶段仅仅描述“高层算子行为 + 并行结构”,而非真实的计算。
当用户执行 kernel[grid](...) 时,Python DSL 层会捕获 kernel 的 grid 形状和运行参数,并将它们与 kernel 参数绑定。基于 Python 的 Magic Method 机制:表达式 obj[key] 会被解释为调用 obj.__getitem__(key) ,因此运行kernel[grid] 会调用 JITFunction.__getitem__(grid)。
class JITFunction(KernelInterface[T]):
class KernelInterface(Generic[T]):
run: T
def __getitem__(self, grid) -> T:
return lambda *args, **kwargs: self.run(
grid=grid,
warmup=False,
*args,
**kwargs,
)
__getitem__ 返回一个 lambda,该 lambda 捕获了 grid 参数,调用该 lambda 时,它会调用 self.run(grid=grid, warmup=False, *args, **kwargs)。这里的 self 是 JITFunction 实例,因此调用的是JITFunction.run函数。
JITFunction.run函数运行流程图如下。主要是完成 kernel 的编译、缓存、运行等操作,并且返回编译好的 kernel (class CompiledKernel的实例化对象)。
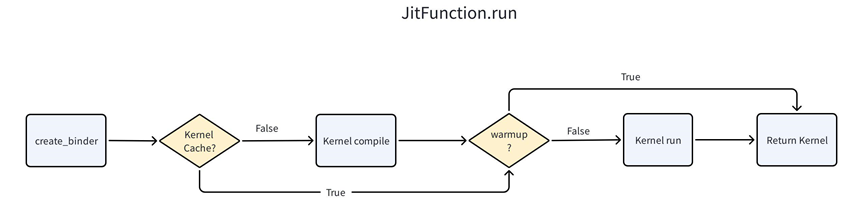
首先,JITFunction 会查找缓存 kernel;如果没有缓存,它会触发 ASTSource 的生成与后端编译,生成可执行 kernel。在 warmup=False 的情况下,编译好的 kernel 会立即被 launch 执行,实现真正的计算。这种设计既允许延迟执行和参数缓存,也支持在第一次调用时进行即时编译和运行,从而兼顾灵活性与性能。
def run(self, *args, grid, warmup, **kwargs):
...
# compile the kernel
src = self.ASTSource(self, signature, constexprs, attrs)
kernel = self.compile(src, target=target, options=options.__dict__)
...
kernel.run(grid_0, grid_1, grid_2, stream, kernel.function, kernel.packed_metadata,
launch_metadata, self.CompiledKernel.launch_enter_hook, self.CompiledKernel.launch_exit_hook,
*bound_args.values())
return kernel
其中 self.compile 以及 kernel.run 是关键的编译和运行流程,self.compile 在 create_binder 函数中被初始化,实际指向 triton.compiler.compile 函数。
从JITFunction.run() 被调用起,控制权从 Python 的抽象算子语义转交给 Triton 编译器。随后,编译器会执行优化、向量化、内存布局调整以及 codegen,将高层抽象逐步转换为可在具体硬件上运行的 kernel 程序。
Compile 层级
进入编译阶段后,编译器接手的不再是 Python 的函数调用,而是一份可供分析和优化的编译器高层 IR 表示。它将基于这份表示,规划计算顺序、优化内存布局、执行向量化,并最终生成能在目标硬件上高效运行的 kernel。完整的 Kernel 算子编译流程如下:

从上述流程可以看出,编译过程并非简单的代码转换,而是一个需要深度理解目标硬件特性的复杂过程。具体而言,该流程包含五个关键阶段:
- 初始化目标后端。编译器首先根据目标硬件平台(如 CPU、GPU 等)创建唯一的后端实例。
- 注册编译阶段(
add_stages())。基于第一阶段确定的后端,通过 add_stages() 方法注册一系列用于适配特定硬件架构的编译阶段,每个阶段对应一个中间表示的转换过程。
- 生成 TTIR(
make_ir())。编译器调用 make_ir() 方法,将 Python AST 或已有的 IR 源文件转换为初始的 Triton IR(TTIR)。这一阶段会进行基础的优化,如内联、公共子表达式消除、循环不变式外提等,生成一个便于后续优化的中间表示。
- 沿着第二阶段注册的编译阶段逐层翻译,将高层 TTIR 逐步降级为更接近特定硬件的 IR 表示。
- 生成二进制文件。最后,编译器将 LLVM IR 通过 LLVM 工具链(如 clang)编译为目标硬件的机器码,生成可执行的二进制文件(如
.so 共享库等),完成从高层表示到可执行代码的完整转换。
编译过程是一个多阶段、多层次的优化过程,它要求编译器不仅要理解程序的语义,更要深刻把握目标硬件的特性。从高层抽象逐步降级到机器码,期间通过大量的优化 pass 来提升执行效率。
1. 后端驱动自动选择与激活
在传统认知中,编译往往被理解为一段代码翻译成另一段代码。但在 Triton 中,编译的第一步并不是 lowering,而是确定语义具体在哪个硬件执行。同一份 TTIR,在 CPU、CUDA 或 HIP 后端中,其 program_id 的含义、并行展开方式以及内存访问模型都完全不同。因此,在任何 IR pass 被执行之前,Triton 必须先回答一个更根本的问题:这些算子语义,最终要在哪一种硬件执行模型中被解释?这正是 Triton 引入 Driver / Backend 自动发现 + 延迟激活 + 运行时判定机制的原因。它确保后续的每一个编译阶段,都建立在唯一且一致的硬件语义假设之上。
Backend 的注册
当 Triton 被 import 时,Python 会加载 triton/init.py,触发加载 triton/runtime/init.py、triton/runtime/driver.py、triton/runtime/driver.py 以及 triton/backends/init.py
backends = _discover_backends()
def _discover_backends():
backends = dict()
root = os.path.dirname(__file__)
for name in os.listdir(root):
if not os.path.isdir(os.path.join(root, name)):
continue
if name.startswith('__'):
continue
compiler = _load_module(name, os.path.join(root, name, 'compiler.py'))
driver = _load_module(name, os.path.join(root, name, 'driver.py'))
backends[name] = Backend(_find_concrete_subclasses(compiler, BaseBackend),
_find_concrete_subclasses(driver, DriverBase))
return backends
_discover_backends 函数会扫描 backends/ 目录,加载后端的 driver.py 以及 compiler.py 中各模块,找到各后端的 DriverBase 和 BaseBackend 子类,并将每个后端名称映射到全局 backends 字典。此时不创建任何 Driver 和 Backend 实例。
Driver 的延迟初始化和激活
Driver 表示当前运行环境中可用的硬件驱动。Triton 使用 DriverConfig 来管理当前活跃的 Driver:
class DriverConfig:
def __init__(self):
self.default = LazyProxy(_create_driver)
self.active = self.default
...
driver = DriverConfig()
此时:driver.active 并不是一个 Driver 实例,而是一个 LazyProxy,内部仅保存了 _create_driver 这个构造函数。其中,LazyProxy 是一个延迟初始化类,用于在首次访问时才创建特定后端的实例对象 CPUDriver。
class LazyProxy:
def __init__(self, init_fn):
self._init_fn = init_fn
self._obj = None
当执行 kernel[grid](...) 时,JITFunction.run 会首次通过 driver.active 访问运行时驱动对象(若在此之前已有代码访问过 driver.active,例如 @triton.autotune 在初始化阶段触发,则以更早的那一次为准)。此时,LazyProxy 才会触发 _create_driver(),遍历 backends 字典,调用各后端的 is_active()(如 CPUDriver.is_active()),判断当前硬件是否可用,找到唯一返回 True 的 Driver 并实例化。
def run(self, *args, grid, warmup, **kwargs):
...
# parse options
device = driver.active.get_current_device()
def _create_driver():
actives = [x.driver for x in backends.values() if x.driver.is_active()]
if len(actives) != 1:
raise RuntimeError(f"{len(actives)} active drivers ({actives}). There should only be one.")
return actives[0]()
根据 Driver 确定 Backend
Backend 表示针对某一类 target 的编译后端
在编译阶段(compile())中:
def compile(src, target=None, options=None):
if target is None:
target = driver.active.get_current_target()
backend = make_backend(target)
通过 get_current_target 函数决定当前 target
def get_current_target(self):
cpu_arch = llvm.get_cpu_tripple().split("-")[0]
return GPUTarget("cpu", cpu_arch, 0)
这个 target 描述了:backend 类型,架构以及 device id。
最终 Backend 根据 target 选择唯一支持它的 backend,实例化该 backend。
def make_backend(target):
actives = [x.compiler for x in backends.values() if x.compiler.supports_target(target)]
if len(actives) != 1:
raise RuntimeError(
f"{len(actives)} compatible backends for target ({target.backend}) ({actives}). There should only be one.")
return actives[0](target)
通过这一套自动发现 + 延迟初始化 + 运行时判定的机制,Triton 实现了在不暴露复杂配置的前提下,对不同硬件环境的自适应支持。这也是 Triton kernel 能够同一份代码,跨 CPU / CUDA / HIP 执行的基础前提。
2. 编译阶段注册
确定 backend 以后,调用 backend.add_stages() 注册对应后端的编译阶段:
# run compilation pipeline
stages = dict()
backend.add_stages(stages, options)
add_stages() 是抽象方法,每个后端目录都包含 compiler.py 以及 driver.py 文件,各后端实现自己的编译阶段,实际运行时,会根据 backend 的实际实例类型动态调用对应后端类的 add_stages 方法实现。例如 Triton CPU 后端:
def add_stages(self, stages, options):
stages["ttir"] = lambda src, metadata: self.make_ttir(src, metadata, options)
stages["ttcir"] = lambda src, metadata: self.make_ttcir(src, metadata, options)
stages["tttcir"] = lambda src, metadata: self.make_tttcir(src, metadata, options)
stages["llir"] = lambda src, metadata: self.make_llir(src, metadata, options)
stages["asm"] = lambda src, metadata: self.make_asm(src, metadata, options)
stages["so"] = lambda src, metadata: self.make_so(src, metadata, options)
3. 生成 tt.ir
module = src.make_ir(options, codegen_fns, module_map, context)
make_ir 用于将 Python AST 转为 Triton IR(TTIR),softmax 算子生成的部分 tt.ir 如下:
module {
tt.func public @softmax_kernel_2(
%arg0: !tt.ptr<f32> {tt.divisibility = 16 : i32},
%arg1: !tt.ptr<f32> {tt.divisibility = 16 : i32},
%arg2: i32
) attributes { noinline = false } {
%c1024_i32 = arith.constant 1024 : i32
%0 = tt.get_program_id x : i32
%1 = arith.muli %0, %c1024_i32 : i32
%2 = tt.make_range
{ start = 0 : i32, end = 1024 : i32 }
: tensor<1024xi32>
%3 = tt.splat %1 : i32 -> tensor<1024xi32>
%4 = arith.addi %3, %2 : tensor<1024xi32>
%5 = tt.splat %arg2 : i32 -> tensor<1024xi32>
%6 = arith.cmpi slt, %4, %5 : tensor<1024xi32>
%7 = tt.splat %arg0
: !tt.ptr<f32> -> tensor<1024x!tt.ptr<f32>>
%8 = tt.addptr %7, %4
: tensor<1024x!tt.ptr<f32>>, tensor<1024xi32>
%9 = tt.load %8, %6
: tensor<1024x!tt.ptr<f32>>
%10 = "tt.reduce"(%9)
<{ axis = 0 : i32 }> ({
^bb0(%arg3: f32, %arg4: f32):
%19 = arith.maxnumf %arg3, %arg4 : f32
tt.reduce.return %19 : f32
})
: (tensor<1024xf32>) -> f32
...
}
}
4. TTIR 逐层生成 kernel 动态库
TTIR 是 Triton 编译流程中最后一个仍然显式保留 Triton DSL 专有语义的 IR 层。在该层级中,program_id、非结构化 mask、指针算术以及 tensor 级算子仍以高层抽象形式存在。例如生成tt.ir小节 softmax 算子中,第 13 行 IR 代码:tt.load 的 mask 参数%6并非控制流或标量条件,在 TTIR 中表达的是向量级 predication 语义:向量中每个 lane 根据 mask 的布尔值决定是否从内存加载数据,而所有 lane 都在同一条指令下并行执行。
%9 = tt.load %8, %6 : tensor<1024x!tt.ptr<f32>>
由于 LLVM IR 本身采用单线程、显式控制流的执行模型,无法直接表达隐式并行实例(program_id)与数据级 predication(mask)等语义,而且 TTIR 无法直接一次性 lowering 到目标二进制,Triton 因此引入了以 stage 为单位的分阶段编译机制,通过在每个 stage 中组合多种 MLIR dialect 的 pass,逐步将算子语义转换为可执行语义。
for ext, compile_ir in list(stages.items())[first_stage:]:
next_module = compile_ir(module, metadata)
stage 并非严格等价于某一个 IR dialect,而是 Triton 为组织 lowering 过程而定义的逻辑编译阶段。每个 stage 可能涉及多个 dialect 的协同转换,其输出会作为下一阶段的输入,直到最终生成 LLVM IR ,并由后端编译为面向目标架构的可加载二进制(通常以 ELF 形式存在)。
不同后端(如 CPU、CUDA)会定义各自的 stage 序列与 pass 组合。例如在 Triton CPU 后端中,make_llir 阶段会引入 vector-to-SCF、SCF-to-CF 以及 program_id 到 LLVM IR 的语义映射 pass,将隐式并行与向量语义等逐步转换为 LLVM 可接受的控制流与标量/向量操作。
def make_llir(self, src, metadata, options):
...
cpu.passes.ttcpuir.add_vector_to_scf(pm, True, 1, False)
...
passes.convert.add_scf_to_cf(pm)
cpu.passes.ttcpuir.add_program_id_to_llvmir(pm)
编译完成后,Triton 会将生成的中间 IR、目标二进制及相关元数据缓存,并返回一个 CompiledKernel 对象。该对象并非直接可执行函数,而是包含二进制句柄、ABI 绑定信息与运行时元数据的封装,供后续 kernel launch 阶段使用。
从工程视角看,stage 的存在使 Triton 得以在保持 DSL 表达能力的同时,逐步向底层 IR 过渡;从编译器设计角度看,它本质上是一种语义逐级消解(semantic erosion)的过程。
Runtime 层级
当 TTIR 经历多阶段 lowering 并最终生成目标架构的二进制代码后,kernel 的计算逻辑已完整且可执行,但其并行实例的展开、参数从 Python 到设备的传递以及线程或 core 的调度仍需由运行时系统负责;因此,我们进入 Triton Kernel 的 runtime 层级。
在编译阶段创建的 CompiledKernel 对象时,会调用 CompiledKernel.__init__ 函数,此时 self.kernel、self.metadata 以及 self.asm 均已被初始化,但是 self.run、self.module 和 self.function 运行时相关的参数还没有被初始化,而且启动 kernel 函数的代码还没有生成。
CompiledKernel 也使用延迟初始化,流程如下:

当用户使用 kernel[grid] 时,最终会调用 kernel.run 函数,此时的 kernel 指向 CompiledKernel 对象,CompiledKernel 中包含 __getattribute__ 函数,因此 __getattribute__ 会拦截所有属性访问(如 kernel.run)。因此,调用 kernle.run() 时,通过 __getattribute__ 函数中的 _init_handles 函数进行初始化,并返回 self.run 对象。
def __getattribute__(self, name):
if name == 'run':
self._init_handles()
return super().__getattribute__(name)
def _init_handles(self):
...
self.run = driver.active.launcher_cls(self.src, self.metadata)
...
self.module, self.function, self.n_regs, self.n_spills = driver.active.utils.load_binary(self.name, self.kernel, self.metadata.shared, device)
至此,运行时相关的 self.run、 self.module、self.function 相关参数会被初始化,供后续使用。
1. 初始化 self.run
初始化 device
device = driver.active.get_current_device()
同理 3.1 章节阐述的内容,确定 active device。
初始化 launcher_cls
_create_driver() 会遍历 backends 字典,调用各后端的 is_active()(如 CPUDriver.is_active())
def _create_driver():
actives = [x.driver for x in backends.values() if x.driver.is_active()]
if len(actives) != 1:
raise RuntimeError(f"{len(actives)} active drivers ({actives}). There should only be one.")
return actives[0]()
找到激活的后端后,actives[0]()实例化(如 CPUDriver()),执行 __init__,此时 launcher_cls 被初始化
class CPUDriver(DriverBase):
def __init__(self):
self.utils = CPUUtils()
self.launcher_cls = CPULauncher
super().__init__()
在 CPULauncher 实例化的过程中,会通过调用 make_launcher 函数生成启动 kernel 的代码,后文会详细介绍 make_launcher 函数的具体实现。
初始化 self.run
由于实例化的时候在 __init__ 函数内部已经设置了 self.launcher_cls = CPULauncher,
self.run = driver.active.launcher_cls(self.src, self.metadata)
通过 launcher_cls 类创建启动器实例(如 CPULauncher 或 CudaLauncher),并返回给 self.run。
2. 初始化 self.module & self.function
调用 load_binary 函数获取二进制内容以及 self.function(内核函数的函数指针,可调用的地址)
self.module, self.function, self.n_regs, self.n_spills = driver.active.utils.load_binary(
self.name, self.kernel, self.metadata.shared, device)
def load_binary(self, name, kernel, shared_mem, device):
with tempfile.NamedTemporaryFile(mode="wb", suffix=".so") as f:
f.write(kernel)
f.flush()
import ctypes
lib = ctypes.cdll.LoadLibrary(f.name)
fn_ptr = getattr(lib, name)
# 获取kernel函数的指针,后续传给launch()
fn_ptr_as_void_p = ctypes.cast(fn_ptr, ctypes.c_void_p).value
return (lib, fn_ptr_as_void_p, 0, 0)
3. 通过 make_launcher 函数生成启动代码并初始化 self.launch
通过 launcher_cls 类创建启动器实例时(CPULauncher),调用 __init__函数,会调用 make_launcher 函数,这个函数会在编译时生成 cpp 代码(启动器代码,用于解析 Python 参数),从而真正调用用户写的 kernel 内核函数。并且通过 compile_native 中的 _build 函数将 C++ 代码编译为共享库并作为 python 模块加载。最后初始化 self.launch。
def __init__(self, src, metadata):
ids = {"ids_of_const_exprs": src.fn.constexprs if hasattr(src, "fn") else tuple()}
constants = src.constants if hasattr(src, "constants") else dict()
cst_key = lambda i: src.fn.arg_names.index(i) if isinstance(i, str) else i
constants = {cst_key(key): value for key, value in constants.items()}
signature = {cst_key(key): value for key, value in src.signature.items()}
src = make_launcher(constants, signature, ids)
mod = compile_module_from_src(src, "__triton_cpu_launcher")
self.launch = mod.launch
Host–Device 协同:以 Triton-CPU 为例,阐述数据传输以及运行的流程
在前面的章节中,我们分析了 Triton kernel 的编译与 runtime 初始化流程:一次 Triton kernel 调用,究竟是如何从 Python DSL,跨越语言层级,最终生成可以真实硬件上并行执行的 kernel 动态库。同时也知道了启动代码生成和编译成共享库并被使用的逻辑。然而,在具体硬件架构上执行 Triton kernel 的流程还未完全串联清楚,尤其是数据从 Host 到 Device 的传输以及 kernel 的执行机制。
在这里,我们选择以 Triton-CPU 为例来说明整个 Host–Device 协同流程。Triton-CPU 是 Triton 框架在 CPU 环境下的运行时实现,它允许用户在没有 GPU 的机器上运行 Triton kernel,同时保持与 GPU 版本类似的 Python DSL 编程体验。选择 Triton-CPU 的原因在于:相比 GPU,CPU 的内存访问模型和线程调度机制更直观,有助于清晰地说明数据传输、调度和执行的整体流程;同时,它也避免了对特定 GPU 硬件和驱动的依赖,使概念性分析更加通用。
1. 通用运行流程
当 kernel[grid] 完成编译流程,执行到 kernel.run 时,由于 kernel.run 已被初始化 CPULauncher 对象,Python 会调用CPULauncher.__call__方法,因此 kernel.run(...)等价于 CPULauncher.__call__(...)等价于self.launch(*args, **kwargs)。
def __call__(self, *args, **kwargs):
self.launch(*args, **kwargs)
在 CPULauncher.__init__ 中,Triton 通过 compile_module_from_src函数将生成的 C++ 启动代码编译为一个 Python 扩展共享对象(.so),并利用 importlib 动态加载为 Python 模块。
该模块在初始化阶段注册了用于 kernel 启动的 C++ 接口,因此 self.launch 实际上是对 __triton_launcher.cpp 中 launch() 函数的 Python 绑定入口。
在 kernel 调用过程中,Python 侧传入的张量数据与运行参数被封装并传递至该 launch() 函数,由其在 C++ 侧完成参数解析、并行实例(program)展开以及 CPU 执行调度,并通过已绑定的内核函数指针调用编译生成的 kernel 代码,从而在 CPU 硬件上完成实际计算。
下面将以 softmax 算子为例,进一步阐述从 Python 数据传入到 CPU 上 kernel 执行完成的完整流程。
2. 用户定义 kernel
@triton.jit
def softmax_kernel(
output_ptr, # 输出指针 (*fp32)
input_ptr, # 输入指针 (*fp32)
input_row_stride, # 输入行步长 (i32)
output_row_stride, # 输出行步长 (i32)
n_cols, # 列数 (i32)
BLOCK_SIZE: tl.constexpr, # 块大小 (编译时常量)
):
row_idx = tl.program_id(0)
# ... softmax 计算逻辑
生成随机输入数据
x = torch.randn(1823, 781, dtype=torch.float32, device='cpu')
# x.shape = (1823, 781)
# x.data_ptr()
调用 Kernel
def softmax(x):
n_rows, n_cols = x.shape # n_rows=1823, n_cols=781
BLOCK_SIZE = triton.next_power_of_2(n_cols) # 1024
y = torch.empty_like(x) # y.data_ptr()
softmax_kernel[(n_rows,)](
y, # output_ptr
x, # input_ptr
x.stride(0), # input_row_stride = 781
y.stride(0), # output_row_stride = 781
n_cols, # n_cols = 781
BLOCK_SIZE=BLOCK_SIZE, # BLOCK_SIZE = 1024 (编译时常量)
)
return y
3. 运行入口
用户代码调用: softmax_kernel[(1823,)] 等价于: JITFunction.run
# grid[0], # 1823
# grid[1], # 1
# grid[2], # 1
# stream, # None
# kernel.function, # kernel 函数指针 (void*),此时还没有被更新
# kernel.packed_metadata,
# launch_metadata,
# None, # self.CompiledKernel.launch_enter_hook
# None, # self.CompiledKernel.launch_exit_hook
# *args # (y, x, 781, 781, 781,1024)
kernel.run(grid_0, grid_1, grid_2, stream, kernel.function, kernel.packed_metadata,
launch_metadata, self.CompiledKernel.launch_enter_hook, self.CompiledKernel.launch_exit_hook,
*bound_args.values())
4. Backend call
class CPULauncher:
def __call__(self, *args, **kwargs):
# args[0] gridX = 1823
# args[1] gridY = 1
# args[2] gridZ = 1
# args[3] stream = None (PyObject*)
# args[4] function = 0x78711f27c320 (kernel 函数指针, void*),后续会被运行时代码使用
# args[5] packed_metadata = <PyObject*>
# args[6] launch_metadata = <PyObject*>
# args[7] launch_enter_hook = None (PyObject*)
# args[8] launch_exit_hook = None (PyObject*)
# args[9] y (torch.Tensor, PyObject*)
# args[10] x (torch.Tensor, PyObject*)
# args[11] input_row_stride = 781 (int32_t)
# args[12] output_row_stride = 781 (int32_t)
# args[13] n_cols = 781 (int32_t)
# args[14] block_size = 1024
self.launch(*args, **kwargs) # 调用编译后的 C++ launch 函数
5. 启动入口
_triton_launcher.cpp 是生成的启动器代码,包含 launch 函数,作为 Python 入口点。
// 1. 定义 kernel 函数指针类型,此时函数的参数类型需要和kernel.so的行参一一对应
using kernel_ptr_t = void(*)(...参数类型...);
// 2. 并行执行函数 (run_omp_kernels)
// 这里的实际参数指的是def make_launcher(constants, signature, ids):传入进来的signature的itmes
// 例如 softmax就是src = {'output_ptr': '*fp32', 'input_ptr': '*fp32', 'input_row_stride': 'i32', 'output_row_stride': 'i32', 'n_cols': 'i32', 'BLOCK_SIZE': 'constexpr'}
static void run_omp_kernels(int gridX, int gridY, int gridZ, int num_threads,
kernel_ptr_t kernel_ptr, ...实际参数...) {
// 使用 OpenMP 并行执行
#pragma omp parallel for
for (size_t i = 0; i < N; ++i) {
(*kernel_ptr)(...参数..., x, y, z, gridX, gridY, gridZ);
}
}
// 3. Python C API 入口函数
static PyObject* launch(PyObject* self, PyObject* args) {
// 解析 Python 参数
// 提取指针信息
// 调用 run_omp_kernels
}
softmax 测试用例生成的实际 _triton_launcher.cpp 中 launch 函数代码部分如下:
// 生成的函数签名
static PyObject* launch(PyObject* self, PyObject* args) {
...
// 1. 提取 kernel 函数指针
kernel_ptr_t kernel_ptr = reinterpret_cast<kernel_ptr_t>(pKrnl);
// kernel_ptr = 函数地址 0x78711f27c320,此时函数指针的地址和self.function的地址一致
// 因此运行时,程序可以跳转到正确的kernel函数
...
// 2. 调用并行执行函数
// BLOCK_SIZE为常数,因此不生成
run_omp_kernels(gridX, gridY, gridZ, num_threads, kernel_ptr,
ptr_info0.dev_ptr, // void* output_ptr
ptr_info1.dev_ptr, // void* input_ptr
arg2, // input_row_stride = 781
arg3, // output_row_stride = 781
arg4); // n_cols = 781
}
6. 并行执行
static void run_omp_kernels(
int gridX, // 1823
int gridY, // 1
int gridZ, // 1
int num_threads,
kernel_ptr_t kernel_ptr, // 0x7f8a2c001000
void* arg0, // output_ptr = 0x7f8a1d000000
void* arg1, // input_ptr = 0x7f8a1c000000
int32_t arg2, // input_row_stride = 781
int32_t arg3, // output_row_stride = 781
int32_t arg4 // n_cols = 781
) {
// 1. 生成所有 grid 点坐标
...
// 2. OpenMP 并行执行
#pragma omp parallel for schedule(static) num_threads(max_threads)
for (size_t i = 0; i < 1823; ++i) {
const auto [x, y, z] = all_grids[i];
// x = 0..1822, y = 0, z = 0
// 3. 调用实际的 kernel 函数
(*kernel_ptr)(
arg0, // output_ptr = 0x7f8a1d000000
arg1, // input_ptr = 0x7f8a1c000000
arg2, // input_row_stride = 781
arg3, // output_row_stride = 781
arg4, // n_cols = 781
x, // 当前行索引 (0..1822)
y, // 0
z, // 0
1823, // gridX
1, // gridY
1 // gridZ
);
}
}
7. Kernel 函数的 IR 代码的调用接口如下
define void @softmax_kernel(ptr %0, ptr %1, i32 %2, i32 %3, i32 %4, i32 %5, i32 %6, i32 %7, i32 %8, i32 %9, i32 %10)
正好对应了 run_omp_kernels 函数中调用 kernel 函数时传入的参数个数。这就是 triton 编译以及不同 grid 并行跑在真实硬件的全流程,triton 将这部分对用户给隐藏了,从而让用户写算法的时候不需要考虑复杂的硬件适配。
总结
通过对 Triton Kernel 全生命周期的系统分析可以看出,Triton 的性能并非仅由 kernel 算法本身决定,而是由编译优化、IR 设计、后端建模、自动调优(autotune)以及 runtime 启动策略等多环节协同决定。因此,熟悉 Triton Kernel 的全生命周期,本质上是在学习如何与编译器协作,将算法语义、并行结构与硬件约束以显式、结构化、可分析的方式编码到中间表示和调度模型中。这才是从“会用 Triton”,走向“用好 Triton”的关键所在。
本文深入剖析了 Triton 的编译与运行时系统,希望对你理解高性能算子开发的底层机制有所帮助。如果你想深入探讨更多 编译器 与 高性能计算 相关的技术,欢迎在 云栈社区 交流分享,那里汇集了大量关于 开源项目源码分析 的深度内容。
 发表于 2026-1-10 05:49:28
|
查看: 252|
回复: 0
发表于 2026-1-10 05:49:28
|
查看: 252|
回复: 0
